現在、ビッグデータ分析コミュニティは、ビッグデータ処理にフルスイングでApacheSparkを使用し始めています。処理は、アドホッククエリ、ビルド済みクエリ、グラフ処理、機械学習、さらにはデータストリーミングにも使用できます。
したがって、Spark Job Submissionを理解することは、コミュニティにとって非常に重要です。 ApacheSparkジョブの送信に関連する手順の学習を共有できることを嬉しく思います。
基本的に2つのステップがあります。

ジョブの送信
count()などのアクションがRDDで実行されると、Sparkジョブが自動的に送信されます。
内部的にrunJob()がSparkContextで呼び出され、派生元の一部として実行されるスケジューラーが呼び出されます。
スケジューラーは、DAGスケジューラーとタスクスケジューラーの2つの部分で構成されています。
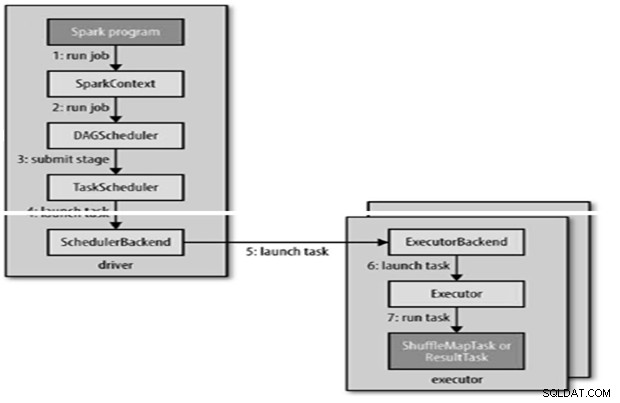
DAGの構築
DAG構造には2つのタイプがあります。

- Simple Sparkジョブはシャッフルを必要としないジョブであるため、MapReduceのマップのみのジョブのように、結果タスクで構成される単一のステージが1つだけあります
- 複雑なSparkジョブにはグループ化操作が含まれ、1つ以上のシャッフルステージが必要です。
- SparkのDAGスケジューラは、ジョブを2つの段階に変えます。
- DAGスケジューラは、タスクスケジューラに送信するために、ステージをタスクに分割する責任があります。
- タスクスケジューラがデータの局所性を利用できるように、各タスクにはDAGスケジューラによって配置設定が与えられます。
- 子ステージは、親が正常に完了した場合にのみ送信されます。
タスクのスケジューリング
- タスクスケジューラは一連のタスクを送信します。アプリケーションで実行されているエグゼキュータのリストを使用し、配置設定を考慮したエグゼキュータへのタスクのマッピングを構築します。
- タスクスケジューラは、空きコアを持つエグゼキュータに割り当てます。各タスクには、デフォルトで1つのコアが割り当てられます。 spark.task.cpusパラメーターで変更できます。
- Sparkは、高度にスケーラブルなイベント駆動型分散アプリケーションを構築するためのアクターベースのプラットフォームであるAkkaを使用しています。
- Sparkはリモート呼び出しにHadoopRPCを使用しません。
タスクの実行
エグゼキュータは次のようにタスクを実行します
- タスクのJARとファイルの依存関係が最新であることを確認します。
- タスクコードを逆シリアル化します。
- タスクコードが実行されます。
- タスクは結果をドライバーに返します。ドライバーは最終結果にアセンブルしてユーザーに返します。
参照
- Hadoop決定ガイド
- 分析とビッグデータのオープンソースコミュニティ
この記事はもともとここに掲載されていました。許可を得て再発行。ここに著作権に関する苦情を提出してください。