このコマンドは、テーブルからすべてのレコードを削除します。 TruncateはDDLコマンドです。構文: TRUNCATE table table_name;
例: Truncate table teacher;
注文者
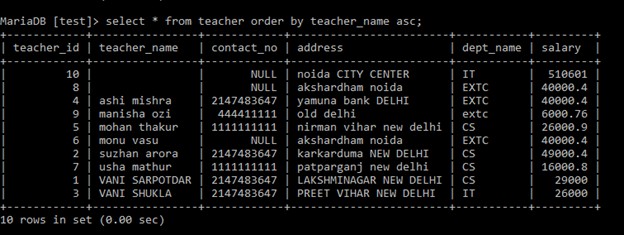
ORDER BY句は、テーブルまたは列を昇順または降順で配置します。デフォルトでは、昇順です。 「ASC」は昇順を示し、「DESC」は降順を示します。結果のレコードをランダムに表示するには、MySQLで使用されるRand()メソッド。例:昇順で並べ替え select *
from teacher
order by teacher_name ;
or
select *
from teacher
order by teacher_name asc ;
 ここでは、出力は同じです。例:
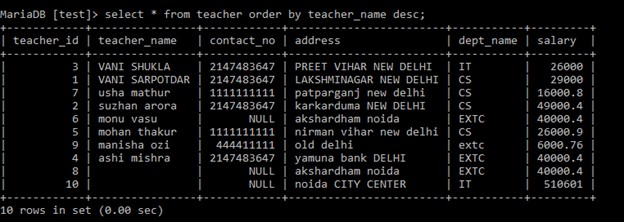
ここでは、出力は同じです。例: select *
from teacher
order by teacher_name desc;
 例:
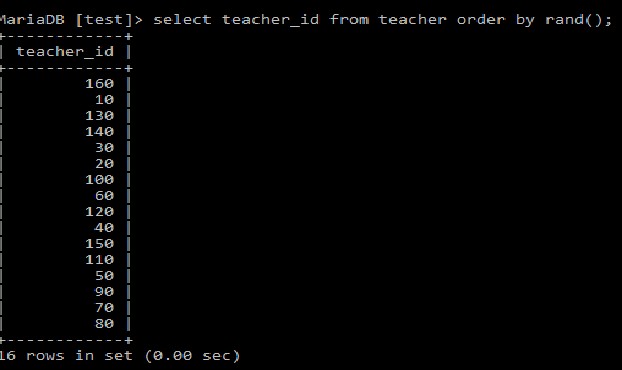
例: Select Teacher_id
from teacher
order by rand();
 制限 Limitキーワードは、有限数のレコードを取得するために使用されます。 Limitは、1つのパラメーターまたは2つのパラメーターで使用できます。 このパラメーターは、表示するレコードの数を決定します。
制限 Limitキーワードは、有限数のレコードを取得するために使用されます。 Limitは、1つのパラメーターまたは2つのパラメーターで使用できます。 このパラメーターは、表示するレコードの数を決定します。 - [最初のパラメータ、2番目のパラメータ]を制限する
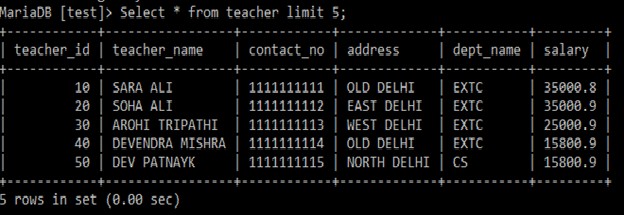
ここで、最初のパラメーターはスキップするレコードの数を示し、2番目のパラメーターは表示するレコードの数を示します。例: Select *
from teacher
limit 5;
 例:
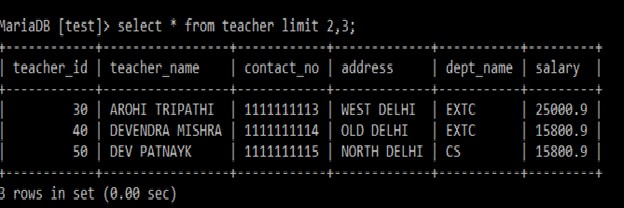
例: Select *
from teacher
limit 2,3;
グループ化
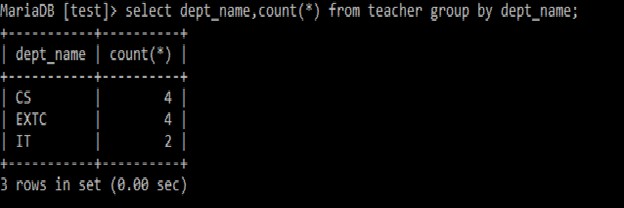
GROUP BY句は、同じ値を持つ行をまとめるために使用されます。主に、データベースから要約レポートを生成するために集計関数で使用されるGROUPBY句。select dept_name, count(*)
from teacher
group by dept_name;
条項があります
have句は、where句の代わりに集計関数と組み合わせて使用されます。これは、句と集計関数が同じクエリで使用できない場所を意味するものではありません。 where句と集計関数を同じクエリで使用できます。注: have句はレコードのグループに適用されますが、where句は各単一レコードに適用されます。where句とhaving句は同じクエリで使用できます。構文: Select function_name(column_name)
From table_name
Group by (column_name)
Having (condition)
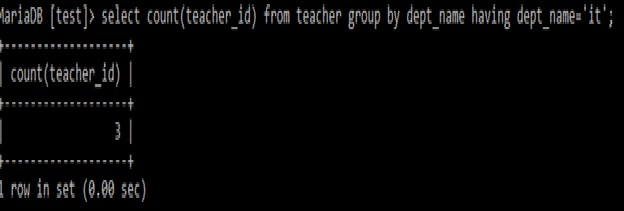
例: select count(teacher_id)
from teacher
group by dept_name
having dept_name='it';
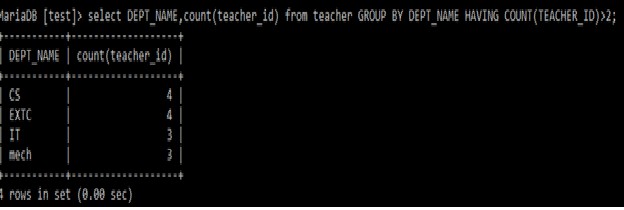
Select dept_name, count(teacher_id)
from teacher
group by dept_name
having count(teacher_id)>2;
SQL結合
部門テーブル 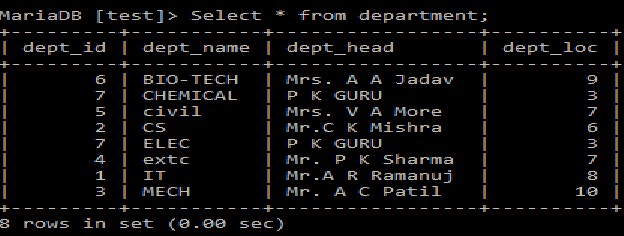 教師用テーブル
教師用テーブル 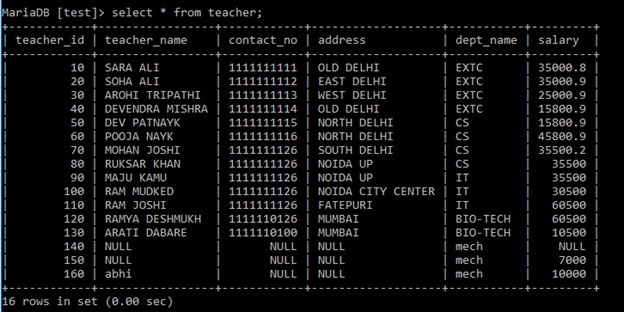 例: 部門名と各部門で働いている教師の数を表示するクエリを記述します。
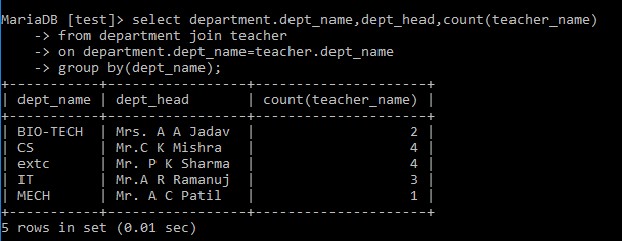
例: 部門名と各部門で働いている教師の数を表示するクエリを記述します。select department.dept_name,dept_head,count(teacher_name)
from department join teacher
on department.dept_name=teacher.dept_name
group by(dept_name);
 表A および表B
表A および表B 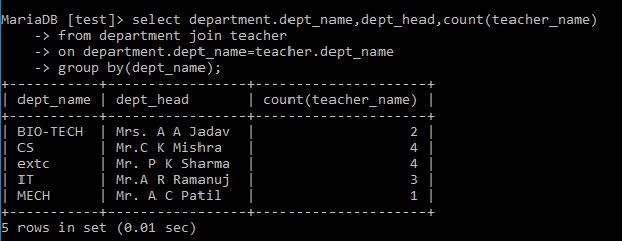 参加 Joinは、それぞれのON条件で両方のテーブルから一致値を返します。
参加 Joinは、それぞれのON条件で両方のテーブルから一致値を返します。 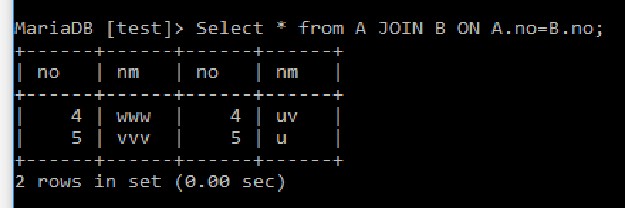
Select *
from A JOIN B
ON A.no=B.no;
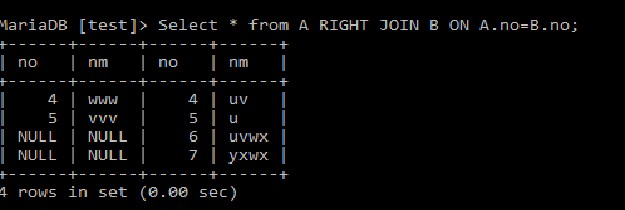
右参加 SQL右結合は、右テーブルからのすべてのレコードと一致した値も返します。他のテーブルに一致する値がない場合は、nullが返されます。Select *
From A RIGHT JOIN B
ON A.no=B.no;
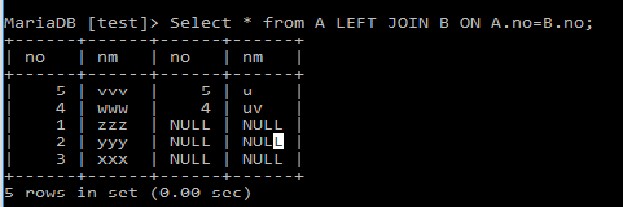
 左参加 SQL左結合は、左テーブルのすべてのレコードと一致した値を返します。他のテーブルに一致する値がない場合は、nullが返されます。
左参加 SQL左結合は、左テーブルのすべてのレコードと一致した値を返します。他のテーブルに一致する値がない場合は、nullが返されます。Select *
from A LEFT JOIN B
ON A.no=B.no;
表示
ビューはデータベースのテーブルと同じです。テーブルは物理エンティティですが、ビューは物理エンティティではありません。ビューはSQLクエリの結果セットに基づく仮想テーブルです。ユーザーは1つ以上のテーブルを使用してSQLクエリを記述し、ビューを作成できます。つまり、ビューにはさまざまなテーブルの列/フィールド/属性を含めることができます。構文: create view view_name as
Select column1,column2,….
From table_name
Where condition;
例: Create view view_student as
Select student_id,student_name,dept_name
From student
Where student_id<10;
を作成します 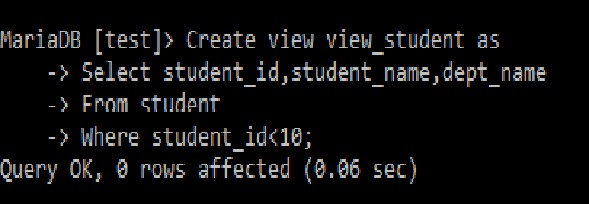
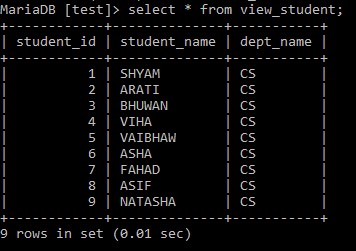
select *
from view_student;
 次の出力画面は、ビューに存在するデータが単一のテーブルからのものである場合に、ユーザーがビューでSQL関数を実行できることを示しています。 WHEREとJOINの場合も同様です。
次の出力画面は、ビューに存在するデータが単一のテーブルからのものである場合に、ユーザーがビューでSQL関数を実行できることを示しています。 WHEREとJOINの場合も同様です。  #ビューを置き換える ビューの置換では、ユーザーはビュー内のクエリを変更することでビュー名またはビューの内容を変更できます。構文:
#ビューを置き換える ビューの置換では、ユーザーはビュー内のクエリを変更することでビュー名またはビューの内容を変更できます。構文: Create or Replace view view_name as
Select column1,column2,……
From student
Where condition;
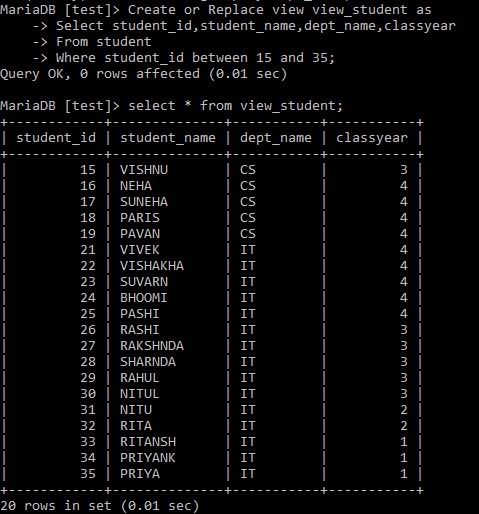
例: Create or Replace view view_student as
Select student_id,student_name,dept_name,classyear
From student
Where student_id between 15 and 35;
 #ドロップビュー ユーザーはDROPVIEWコマンドを使用してビューをドロップできます。構文:
#ドロップビュー ユーザーはDROPVIEWコマンドを使用してビューをドロップできます。構文: Drop view
view_name;
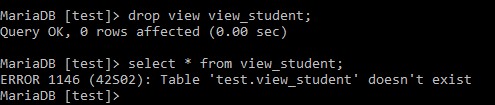
例: Drop view
view_student;
 ネストされたクエリ 別のクエリ内のクエリ ネストされたクエリと呼ばれます。 ユーザーはそれらを外部クエリと内部クエリを参照できます。 サブクエリという名前の内部クエリ 。サブクエリは、単一行の出力または複数行の出力になります。ユーザーは、select句またはwhere句の前にサブクエリを配置できます。構文:
ネストされたクエリ 別のクエリ内のクエリ ネストされたクエリと呼ばれます。 ユーザーはそれらを外部クエリと内部クエリを参照できます。 サブクエリという名前の内部クエリ 。サブクエリは、単一行の出力または複数行の出力になります。ユーザーは、select句またはwhere句の前にサブクエリを配置できます。構文: Select columns
From table_name
Where condition In( select column_name
From table_name
Where condition);
Select column_name =(select column_name
From table_name
Where condition),columns
From table_name
Where condition;
例: Q1 給与が「IT」部門の平均給与よりも高い「IT」部門の教師名を表示します。Select teacher_name
From teacher
Where salary>(select avg(salary)
From teacher where dept_name=’IT’);
SQL シーケンス MySQLでは、AUTO_INCREMENTキーワードを使用してシーケンスを生成します。各レコードを一意に識別するために使用される一連の数値を生成します。これを列に適用すると、新しいレコードをテーブルに挿入するときに列の値が1ずつ増加します。Auto_incrementフィールドがキーである必要があります。構文: Create table table_name
(column1 data type AUTO_INCREMENT,
column2 data type,…,
column1 Primary key);
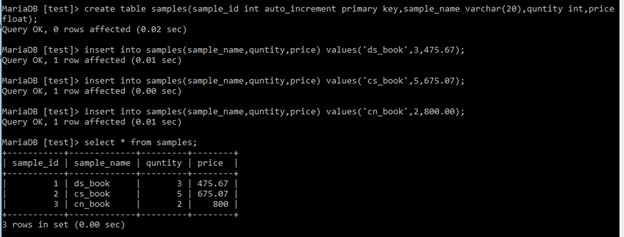
例: create table samples
(sample_id int auto_increment primary key,
sample_name varchar(20),
quntity int,price float);
テーブル作成後にAUTO_INCREMENTを適用します
構文: Alter table table_name
modify column
colmn_name data type primary key auto_increment;
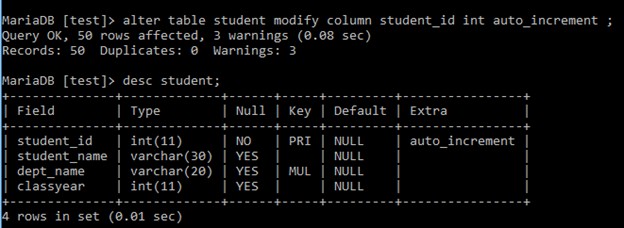
例: alter table student
modify column
student_id int auto_increment ;
インデックス
ユーザーはインデックスを作成できます。データはインデックスの助けを借りてデータベースから非常に高速に取得されます。ユーザーはインデックスを見ることができません。インデックスは、検索またはクエリの目的でのみ使用されます。構文 Create Index index_name
On table_name (column_name);
例: create index stud_index
on student (student_name);
ドロップインデックス
構文: Alter table table_name
Drop index index_name;
例: alter table student
drop index stud_index;
例
Q1Teacher_idベースでTeacherテーブルから最高の給与を見つけます。 回答: Teacher_id desc limit 1による教師の順序からteacher_idを選択します; //表示するレコードの数、またはselect max(teacher_id) from teacher;
Q2 Teacher_idに基づいて、教師のテーブルから2番目に高い給与を調べます。 回答 :teacher_id desc limit 1,1による教師の順序からteacher_idを選択します; // 1レコードをスキップし、1レコードを表示しますQ3teacher_idベースで教師テーブルから3番目に高い給与を見つけます。 回答: Teacher_id desc limit 2,1;Q3による教師の順序からteacher_idを選択します。teacher_idベースで教師テーブルからn番目の最高給与を見つけます。 回答: Teacher_id desc limit n-1,1;による教師の順序からteacher_idを選択します。