数日前に、ClusterControlの新しいバージョンである1.7.2がリリースされました。ここでは、いくつかの新機能を確認できます。主な機能の1つは、TimescaleDBのサポートです。
TimescaleDBは、完全なSQLをサポートする、高速な取り込みと複雑なクエリ用に最適化されたオープンソースの時系列データベースです。これはPostgreSQLに基づいており、時系列データに最高のNoSQLとリレーショナルの世界を提供します。 TimescaleDBは、高可用性セットアップで使用できるレプリケーションの主要な方法としてストリーミングレプリケーションをサポートしています。ただし、PostgreSQLには自動フェイルオーバーが付属していないため、これは高可用性の本番環境では問題になります。手動フェイルオーバーは通常、フェイルオーバー手順を開始する前に、人間がページングされ、コンピューターを見つけてシステムにログインし、何が起こっているのかを理解する必要があることを意味します。これは、長いダウンタイム期間につながります。幸い、TimescaleDBをサポートするようになったClusterControlを使用してフェイルオーバーを自動化する方法があります。
このブログでは、ClusterControlを使用して、数回クリックするだけで自動フェイルオーバーを備えた複製されたTimescaleDBセットアップを展開する方法を説明します。また、HAProxyを介してアプリケーション用の単一のデータベースエンドポイントを追加する方法についても説明します。前提条件として、1.7.2バージョンのClusterControlを専用のホストまたはVMにインストールする必要があります。
TimescaleDBのデプロイ
ClusterControlからTimescaleDBの新規インストールを実行するには、[展開]オプションを選択し、表示される指示に従います。すでにTimescaleDBインスタンスを実行している場合は、代わりに[既存のサーバー/データベースのインポート]を選択する必要があることに注意してください。
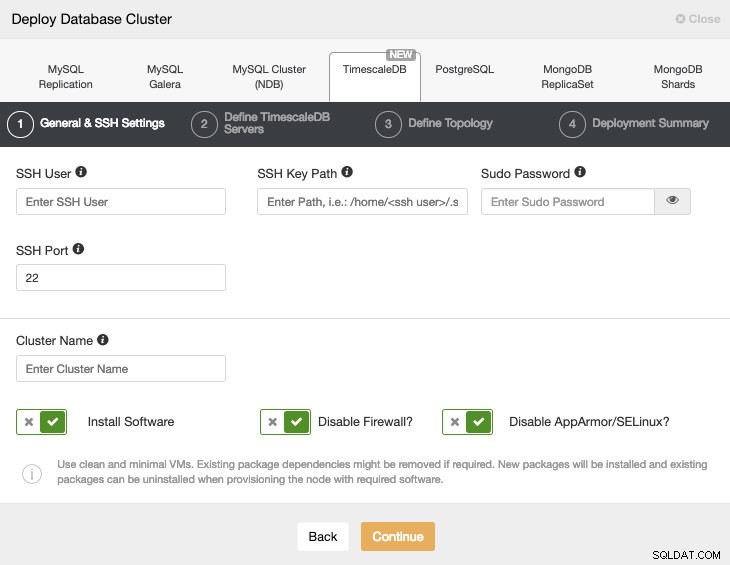
TimescaleDBを選択するときは、SSHでTimescaleDBホストに接続するためのユーザー、キー、またはパスワードとポートを指定する必要があります。また、新しいクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合も必要です。
このタスクのClusterControlユーザー要件をここで確認してください。
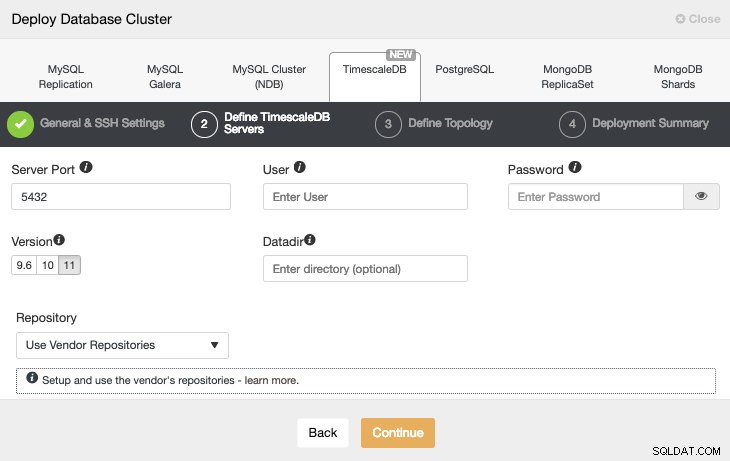
SSHアクセス情報を設定した後、データベースユーザー、バージョン、およびdatadir(オプション)を定義する必要があります。使用するリポジトリを指定することもできます。
次のステップでは、作成するクラスターにサーバーを追加する必要があります。
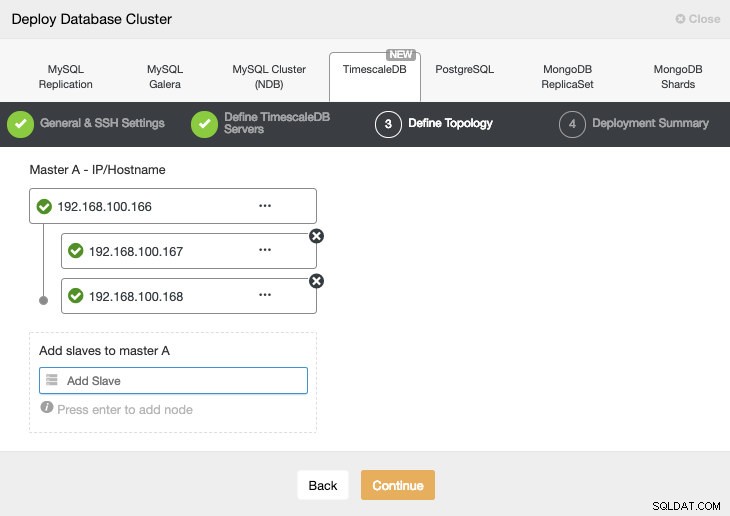
サーバーを追加するときに、IPまたはホスト名を入力できます。
最後のステップで、レプリケーションを同期にするか非同期にするかを選択できます。
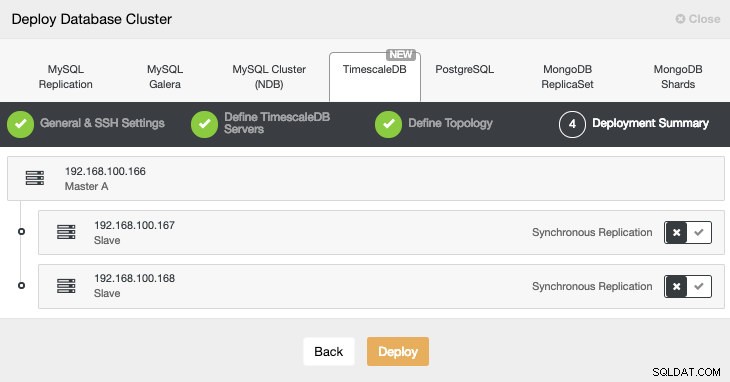
ClusterControlアクティビティモニターから新しいクラスターの作成ステータスを監視できます。
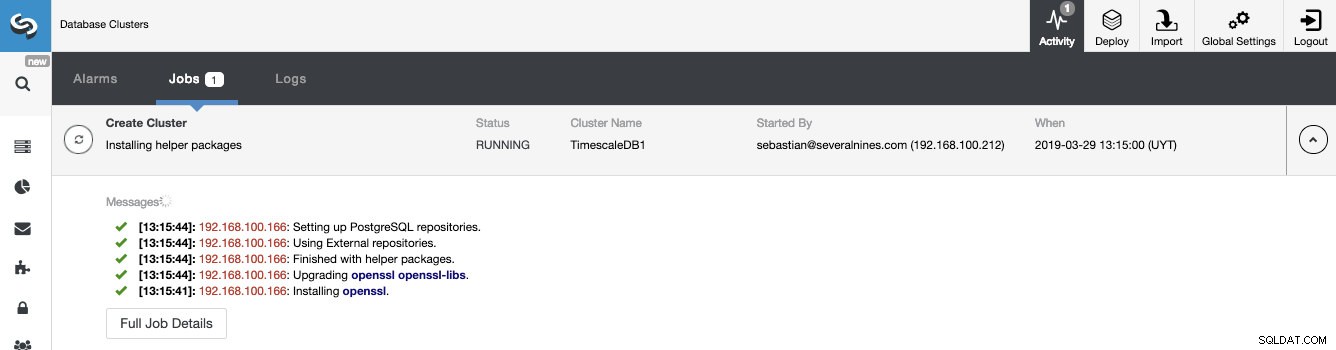
タスクが完了すると、ClusterControlのメイン画面に新しいTimescaleDBクラスターが表示されます。

クラスタを作成したら、ロードバランサ(HAProxy)や新しいレプリカの追加など、いくつかのタスクを実行できます。
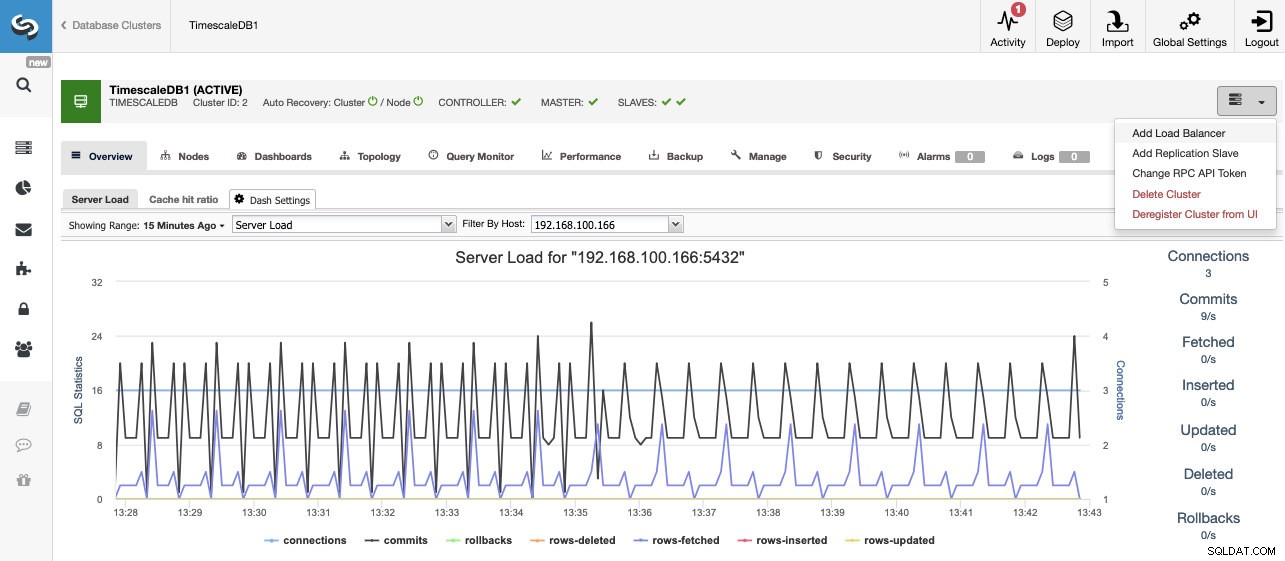
TimescaleDBのスケーリング
クラスタアクションに移動して[レプリケーションスレーブの追加]を選択すると、新しいレプリカを最初から作成するか、既存のTimescaleDBデータベースをレプリカとして追加できます。
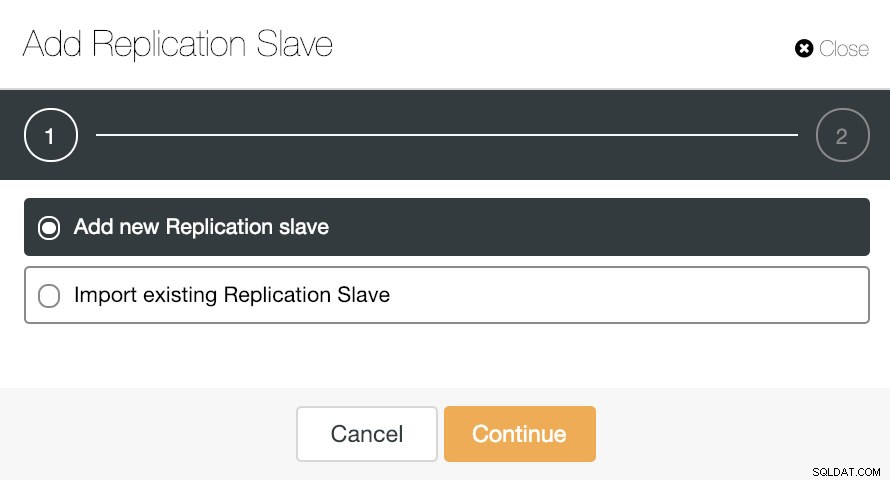
新しいレプリケーションスレーブを追加することが本当に簡単な作業になる方法を見てみましょう。
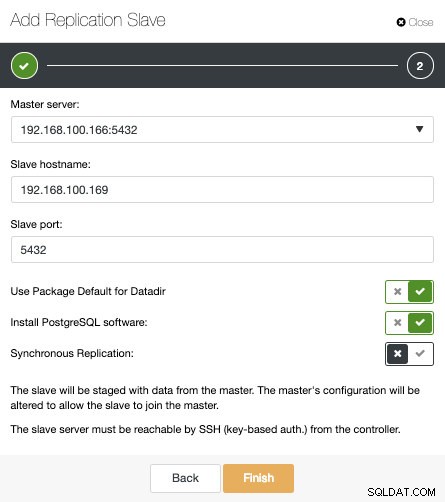
画像でわかるように、マスターサーバーを選択し、新しいスレーブサーバーのIPアドレスとデータベースポートを入力するだけです。次に、ClusterControlにソフトウェアをインストールさせるかどうか、およびレプリケーションスレーブを同期にするか非同期にするかを選択できます。
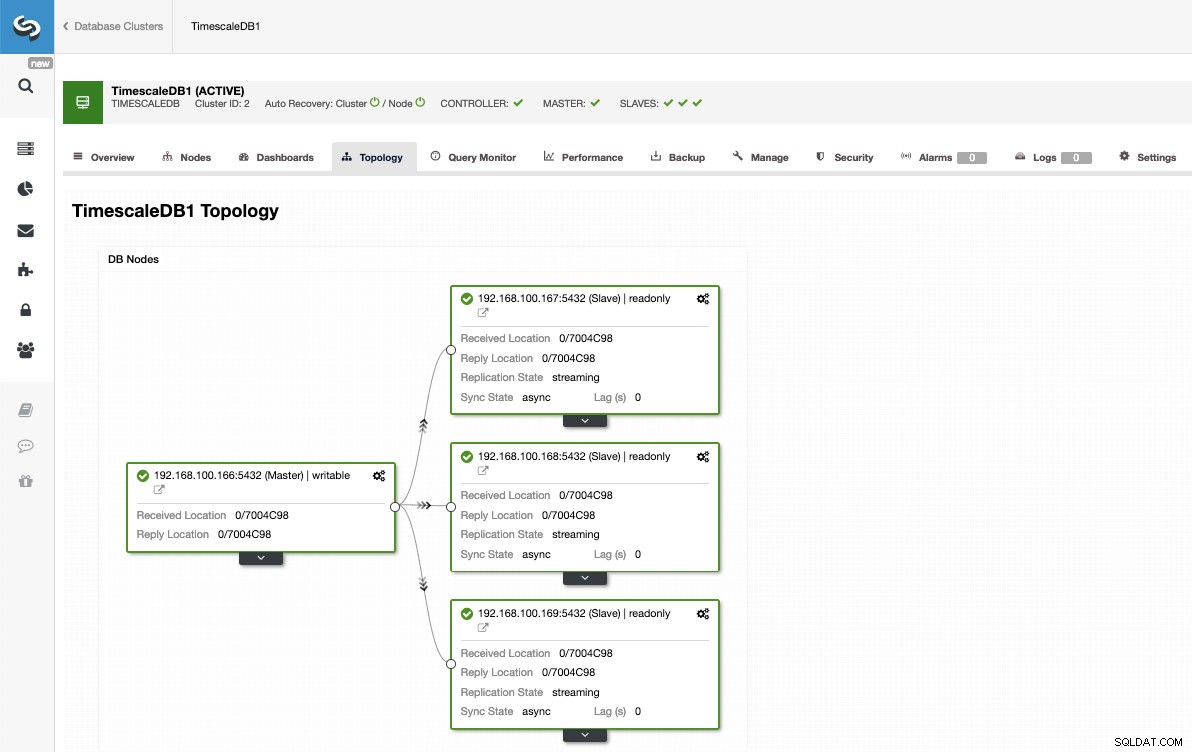
このようにして、必要な数のレプリカを追加し、ロードバランサーを使用してそれらの間で読み取りトラフィックを分散できます。これはClusterControlでも実装できます。
ClusterControlから、ワンクリックで、ホストの再起動、レプリケーションスレーブの再構築、スレーブのプロモートなどのさまざまな管理タスクを実行することもできます。
結論
上で見たように、ClusterControlを使用してTimescaleDBをデプロイできるようになりました。 ClusterControlを導入すると、監視、アラート、自動フェイルオーバー、バックアップ、ポイントインタイムリカバリ、バックアップ検証から、リードレプリカのスケーリングまで、あらゆる機能が提供されます。これは、TimescaleDBをフレンドリーで直感的な方法で管理するのに役立ちます。