注:この記事では、Eclipse IDE for Voracity(およびその付属製品)であるIRI Workbenchを使用して、リレーショナルデータベース(RDB)モデルをスタースキーマに移行し、両方のアーキテクチャを紹介します。 RDBまたはデータをDataVault2.0モデルに移行することに関心がある場合は、新しいWorkbenchウィザードが2019年5月にWorld WideDataVaultコンソーシアムでデビューします。 IRIブログを購読して、公開されたらすぐに手順を追って説明してください。
データウェアハウス(DW)は、ビジネスの運用システムまたはトランザクションシステムから抽出され、不整合をクリーンアップするために変換され、迅速な分析やレポートをサポートするように配置されたデータのコレクションです。 DWには、運用データベースのスキーマ、または論理的な説明とグラフィック表現が必要です。この記事では、これらのトピックに触れながら、従来のリレーショナルデータベーススキーマからスタースキーマと呼ばれる一般的なDWスキーマに移行するためのハウツーガイドを提供します。
スタースキーマとリレーショナル
ほとんどのリレーショナルデータ構造は、実体関連(ER)図に示されています。 ERダイアグラムは、オンライントランザクション処理(OLTP)データベース管理システムの概念モデルの開発に使用されます。これは、テーブル構造が変換されるソースです。
ただし、スタースキーマは、データウェアハウスの基盤となるテーブル構造の標準として広く受け入れられています。その単純な星型(ER図の場合)は、中央にファクトテーブル(トランザクション値またはメジャーを含む)と、そこから放射状に広がるディメンションテーブル(記述値または属性値を含む)を示しています。通常、ファクトテーブルは第3正規形(3NF)ですが、ディメンションテーブルは非正規化されています。
実体関連(ER)モデルとスターモデルの基本的な違いは次のとおりです。
- ERモデルは、正規化されたデータベース設計に論理的および物理的構造を使用します
- ディメンションモデルは、非正規化されたデータベース設計に物理構造を使用します
IRIソフトウェアが行と列のピボットを介してデータを非正規化/正規化する方法を確認するには、ここをクリックしてください。
変換プロセスの背景
この記事では、多かれ少なかれ手動で定義する必要があるが、自動的に作成および実行でき、簡単に変更できるジョブを使用して、リレーショナルモデルからスターにデータを変換する方法を示します。
ここに表示されるのは、IRIの4GLデータとジョブ仕様(「SortCL」スクリプト[1]で表される)であり、データをディメンションテーブルにマッピングし、データを中央のファクトテーブルに結合します。 SortCLは、IRIVoracityデータ管理およびETLプラットフォームのコアデータ操作およびマッピングプログラムです。ただし、ここでは、スクリプト構文ではなく、SortCLジョブの方法論とマッピングを理解することが重要です。
無料のEclipseGUIであるIRIWorkbenchは、構文に対応したSortCLエディター、グラフィカルアウトラインとダイアログ、ワークフローとマッピングダイアグラム、直感的なジョブウィザードを提供し、必要がない場合にこれらのスクリプトを自動的に構築または変更します。手で。参考までに、IRIは、DBのプロファイリングとダイアグラム作成、テストデータの生成、ETLの実行、レポートのフォーマット、PIIのマスキング、変更されたデータのキャプチャ、データの移行と複製、データのクレンジングと検証などに同じメタデータとGUIを使用します。
Workbenchは、Eclipse用の拡張バージョンのData Tools Platform(DTP)プラグインを使用して、JDBCを介してデータベースに接続し、データソースエクスプローラー(DSE)ビューでSQL操作とIRIメタデータ交換を有効にします。この場合、Workbenchは以下をサポートしています:
- SortCL(またはこの記事ではIRI RowGenジョブ)を介した制約付きOracleテスト(ソース)テーブルの作成と作成
- SortCLを介したエンティティテーブルデータのディメンションテーブルへのマッピング
- プリンシパルディメンションテーブルを関連付けるためのn-ary関係としてのファクト要素のマッピング。つまり、SortCLでマルチテーブル結合を実行して、ファクトテーブルを作成します
- すべてのターゲット(スタースキーマ)テーブルの作成
- ソーススキーマとターゲットスキーマのER図
元のリレーショナルモデルのエンティティタイプは、Dept、Emp、Project、Category、Item、Item_Use、Sale:
です。
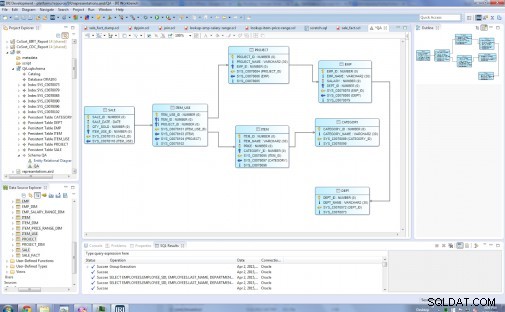
前…
次の図は、8つのディメンションテーブルと1つのファクトテーブルを持つ最終的なスターモデルを示しています。ディメンションテーブルは、Dept_Dim、Emp_Dim、Emp_Salary_Range_Dim、Project_Dim、Category_Dim、Item_Price_Range_Dim、Item_Dimです。中央のファクトテーブルはSale_Factで、すべてのディメンションテーブルへのキーが含まれています。

…後
変換手順
- ファクトテーブルを定義して作成する
このドキュメントでは、Sale_Factテーブルの構造を示しています。主キーはsale_idで、残りの属性はDimensionテーブルから継承された外部キーです。データ変換とマッピングにWorkbench DSE(JDBC経由)およびSortCLに接続されたOracleデータベース(RDBは機能しますが)を使用しています( ODBC経由)。 DSEのSQLスクラップブックで編集され、Workbenchで実行されたSQLスクリプトでテーブルを作成しました。
- ディメンションテーブルを定義して作成する
上記と同じ手法とメタデータを使用して、次のステップでSortCLジョブからマッピングされたリレーショナルデータを受け取るディメンションテーブルを作成します:Category_Dim table、Dept to Dept_Dim、Project to Project_Dim、Item to Item_Dim、Emp to Emp_Dim。その.SQLプログラムをすべてのCREATEロジックで一度に実行して、テーブルを作成できます。
- 元のエンティティテーブルデータをディメンションテーブルに移動します
ここに示すSortCLジョブを定義して実行し、(RowGenで作成されたテスト)データをリレーショナルスキーマからスタースキーマのディメンションテーブルにマッピングします。具体的には、これらのスクリプトは、CategoryテーブルからCategory_Dimテーブル、DeptからDept_Dim、ProjectからProject_Dim、ItemからItem_Dim、EmpからEmp_Dimにデータをロードします。
- ファクトテーブルにデータを入力する
SortCLを使用して、元のSale、Emp、Project、Item_Use、Item、Categoryエンティティテーブルのデータを結合し、新しいSale_Factテーブルのデータを準備します。ここで2番目の(ジョブに参加する)スクリプトを使用します。
この例を拡張するために、SortCLを使用して、ファクトテーブルも依存するスタースキーマに新しいディメンションデータを導入します。上記のスター図には、私のリレーショナルスキーマにはなかったこれらの追加のテーブルEmp_Salary_Range_DimとItem_Price_Range_Dimが表示されます。これらのテーブルは、ファクトテーブルと他のディメンションテーブルの同じ.SQLファイルに作成されます。
ファクトテーブルには、これらのディメンションテーブルの値の範囲を表すために、これらのテーブルのemp_salary_range_idデータとitem_price_range_idデータが必要です。たとえば、ディメンションの価格値をデータウェアハウスにロードするときに、それらを価格範囲に割り当てたいと思います。
| Item_Price | Range_Id | Range_Name | Range_End |
|---|---|---|---|
| 1 | 1 | 100 | |
| 2 | 101 | 500 | |
| 3 | 501 | 999 |
ジョブスクリプト(つまり、Sale_Factテーブルのデータを準備する)で範囲IDを割り当てる最も簡単な方法は、出力セクションでIF-THEN-ELSEステートメントを使用することです。背景のバケット値については、この記事を参照してください。
とにかく、私はCoSort New Join Jobを使用してこのジョブ全体を作成しました ワークベンチのウィザード。そして、それを実行すると、ファクトテーブルにデータが入力されました:
 IRIWorkbenchDSEでのSale_Factテーブルの表示
IRIWorkbenchDSEでのSale_Factテーブルの表示
結論
次元データ表現の主な利点は、データベース構造の複雑さを軽減することです。これにより、テーブルの数、つまり必要な結合の数を最小限に抑えることで、データベースを理解しやすくし、クエリを記述しやすくなります。前述のように、ディメンションモデルはクエリのパフォーマンスも最適化します。しかし、それは強さだけでなく弱さも持っています。スタースキーマの固定構造により、クエリが制限されます。そのため、最も一般的なクエリを簡単に記述できるため、データの分析方法も制限されます。
IRI Workbench GUI for Voracityには、データウェアハウスの作成、保守、拡張など、データ統合を簡素化する強力で包括的なツールセットがあります。この直感的で使いやすいインターフェースにより、Voracityは、異なるプラットフォーム間でのデータ構造を含む、高速で柔軟なエンドツーエンドのETL(抽出、変換、読み込み)プロセスの作成を容易にします。
ETL操作では、データはさまざまなソースから抽出され、個別に変換されて、データウェアハウスや場合によっては他のターゲットに読み込まれます。 ETLプロセスの構築は、潜在的に、倉庫を構築する最大のタスクの1つです。複雑で時間がかかります。 IRIのETLアプローチは、ファイルシステムですべてのデータ統合とステージングを実行することにより、非常に効率的でデータベースに依存しない方法でこのプロセスをサポートします。
[1]構文ハウンドの場合、IRICoSort製品またはIRIVoracityプラットフォームで使用されるSortCLスクリプトは、テストデータ生成用のIRI RowGen、データ移行用のIRI NextForm、およびIRIと同じ構文とデータ定義をサポートしていることに注意してください。データマスキング用のFieldShield。これらのツールはすべてIRIWorkbenchGUIでサポートされており、それらのメタデータを共有してチームで管理し、バージョン管理、ジョブ/データの系統、クラウドのセキュリティを確保することもできます。
[2] IRI WorkbenchでE-R図を表示するには:
- 新しいIRIプロジェクトを選択し、新しいフォルダを作成します
- そのフォルダを選択し、データソースエクスプローラで該当するすべてのデータベーステーブルを強調表示します。次に、IRI、新しいER図を右クリックします
- ファイル(Schema.QA)が作成されます
- そのファイルを右クリックして、[新しい表現]、[新しいエンティティ関係図]を選択します。
[3]このようなモデルを説明するERダイアグラムの要素には、次のものがあります。
- 定義されたエンティティタイプ
- 定義された属性
- エンティティタイプ間の関係
- 全体像または概念図
[4]IRIFACTとSQL*Loaderは、それぞれ一括抽出と読み込みのオプションです。