生命保険は私たち全員が必要としないことを望んでいるものですが、私たちが知っているように、生命は予測不可能です。この記事では、生命保険会社が情報を保存するために使用できるデータモデルの作成に焦点を当てます。
概念としての生命保険
生命保険会社の実際のデータモデルについて説明する前に、保険とは何か、保険がどのように機能するかを簡単に思い出して、何を扱っているかをよりよく理解できるようにします。
保険は非常に古い概念であり、多くのギルドが予期しない状況でメンバーを保護するためのポリシーを提供した中世以前にまでさかのぼります。有名な天文学者、数学者、科学者、発明家であるエドモンドハレーでさえ、保険に手を出し、現代の保険モデルのバックボーンを形成する統計と死亡率に取り組んでいました。
なぜあなたは保険にお金を払わなければならないのですか?考え方は非常に単純です。保険会社があなたやあなたの財産に予期しないことが起こった場合にあなたやあなたの家族が金銭的に補償されるという保証と引き換えに、一定の金額(保険料)を支払います。生命保険の場合は、死亡した場合にその金額(給付金)を受け取る受益者を指定します。アイデアは、特にあなたの死が経済的な問題を引き起こす場合、このお金は彼らが彼らの損失から回復するのを助けるということです。
もちろん、保険会社は通常、保険料や、たとえば株式市場への投資から得られるよりもはるかに少ない給付金を支払います。そうでなければ、彼らは破産し、システム全体が崩壊するでしょう!
それがその要点です。これで問題が解決したので、次に、一般的な生命保険会社のデータモデルを見てみましょう。
データモデル:概要
使用するデータモデルは、5つのサブジェクト領域で構成されています。
- 従業員
- 製品
- クライアント
- オファー
- 支払い
これらの各セクションについて、上記の順序で詳しく説明します。
サブジェクトエリア#1:従業員
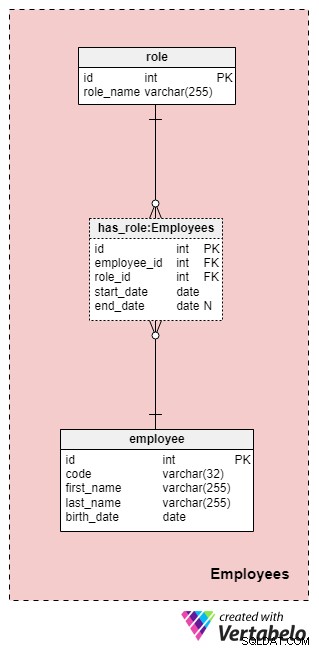
この領域は必ずしもこのデータモデルに固有ではありませんが、ここに含まれるテーブルは他のサブジェクト領域によって参照されるため、依然として非常に重要です。もちろん、保険会社のデータモデルの目的のために、誰がどのアクションを実行したかを知る必要があります(たとえば、顧客/クライアントと協力するときに誰が会社を代表したか、ポリシーに署名したかなど)。
>
会社の全従業員のリストは、従業員に保存されます。 テーブル。従業員ごとに、次の情報を保存します:
コード —1人の従業員を識別する一意のキー。コードは他のテーブルの属性として使用されるため、このテーブルの代替キーとして機能します。-
first_nameおよびlast_name—それぞれ従業員の名前と名前。 -
birth_date—従業員の生年月日。
もちろん、この表には他の多くの従業員関連の属性を含めることもできますが、現時点ではこれら4つで十分です。記事全体を通してこのパターンに従い、可能な限りシンプルに保つように努めますが、このデータモデルを確実に拡張して追加情報を含めることができることに注意してください。
従業員は会社での役割をいつでも変更できるため、会社の役割を表す辞書テーブルと値を格納するテーブルが必要になります。生命保険会社で従業員が引き受けることができるすべての可能な役割のリストは、 roleに保存されています。 辞書。 role_nameという名前の属性が1つだけあります 一意に識別できる値が含まれています。
has_roleを使用して従業員と役割を関連付けます テーブル。外部キーに加えてemployee_id およびrole_id 、2つの値を保存します: start_date およびend_date 。これらの2つの値は、この会社の役割が特定の従業員に対してアクティブであった範囲を示します。 end_date この従業員の役割の終了日が決定されるまで、nullの値が含まれます。このテーブルの代替キーは、 employee_idの組み合わせです。 、 role_id 、および start_date 。同じ従業員に同じ役割が重複しないようにするには、テーブルに新しいレコードを追加したり、既存のレコードを更新したりするたびに、重複がないかプログラムで確認する必要があります。
サブジェクトエリア#2:製品
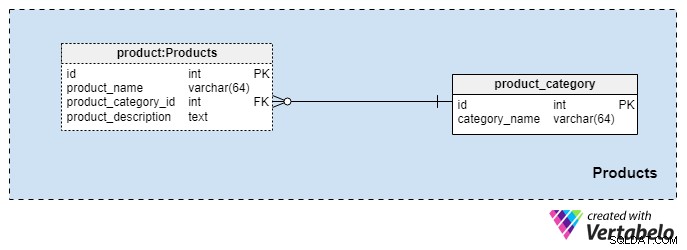
このサブジェクトエリアは非常に小さく、2つのテーブルしか含まれていません。これらの表の値は、他の主題分野の前提条件であるため、これらについて簡単に説明します。
product_category 辞書には、クライアントに提供する予定の製品の最も一般的なカテゴリが格納されています。このテーブルに保存する唯一の値は、一意の category_nameです。 私たちが提供する保険の種類を示すために、個人生命保険、家族生命保険などがあります。
product を使用して、製品をさらに分類します テーブル。この表は、当社が販売する実際の製品を表しており、カテゴリーではありません。ご想像のとおり、製品を期間(たとえば、10年または20年、さらにはライフタイム)でグループ化できます。そうすることを選択した場合、同じ product_category_idの商品が含まれる可能性があります しかし、異なる名前と説明。製品ごとに、次の基本情報を保存します。
-
product_name—この製品の名前。これは、product_category_idと組み合わせてこのテーブルの代替キーとして使用されます。 属性。同じ名前の2つの製品が異なるカテゴリに属する可能性は低いですが、それでも可能性はあります。 -
product_category_id—この製品が属するカテゴリを識別します。 -
product_description—この製品のテキストによる説明。
サブジェクトエリア#3:クライアント
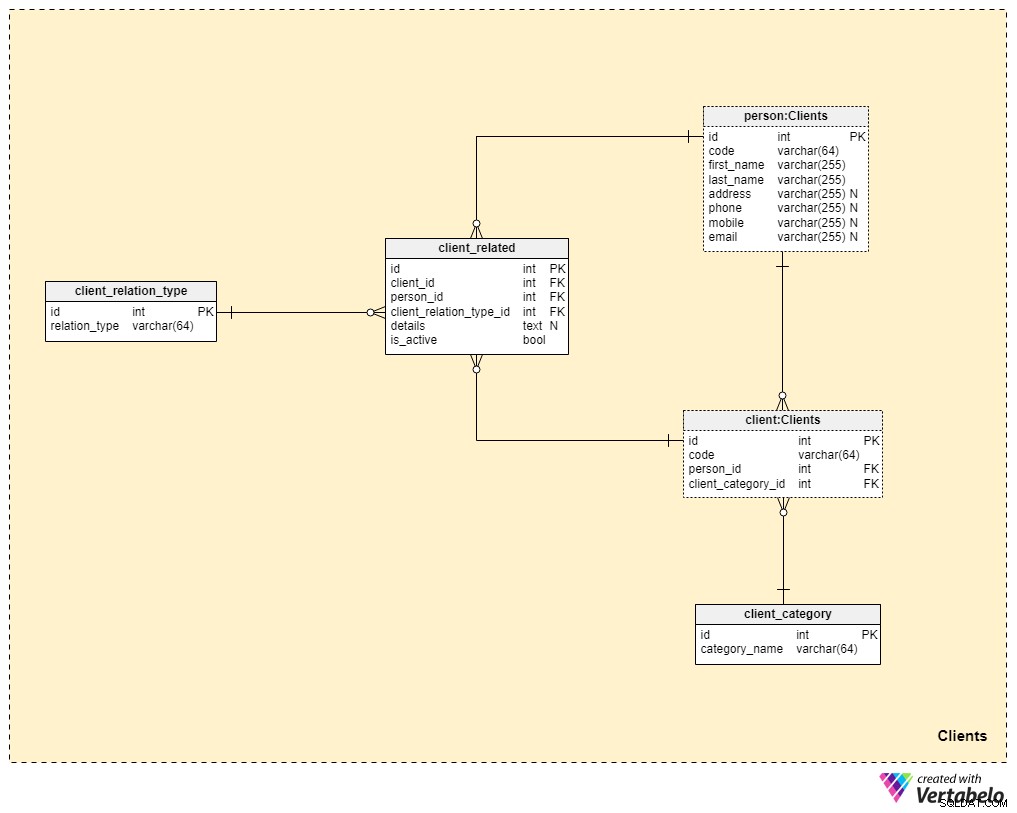
現在、データモデルのコアにかなり近づいていますが、まだ完全には到達していません。生命保険は、家族や他の人に保険を譲渡できるのに対し、他の形態の保険(健康保険や自動車保険など)は単一の顧客に属し、譲渡できないという点で独特です。このため、ポリシーが属するクライアントに関する情報だけでなく、関係者とクライアントとの関係に関する情報も保存する必要があります。
クライアントから始めましょう テーブル。クライアントごとに、そのクライアント用に生成または手動で挿入された一意のコードと、テーブルを参照する外部キーとその個人データ( person_id )を保存します。 )および内部分類を含むテーブル( client_category_id )。
client_category 辞書を使用すると、人口統計と財務の詳細に基づいてクライアントをグループ化できます。次に、クライアントカテゴリを使用して、特定のクライアントに提供する準備ができている保険契約を決定します。ここでは、クライアントに割り当てる一意の値のリストのみを保存します。
生命保険について話しているので、クライアントは1人の個人であると想定します。ただし、前述したように、クライアントに関連する他の人がポリシーを転送したり、クライアントの死亡時にポリシーの特典を受け取ったりする場合があります。このため、別の person を作成しました テーブル。この表の各レコードについて、次の情報を保存します。
コード —関係者を一意に識別するために使用される、自動生成または手動で挿入された値。-
first_nameおよびlast_name—それぞれの人の名前と名前。 アドレス、phone、mobileおよびemail—この人物の連絡先の詳細。すべてに任意の値が含まれています。
この主題分野の残りの2つの表は、クライアントと他の人々との関係の性質を説明するために必要です。
可能なすべての関係タイプのリストは、 client_relation_typeに保存されます。 辞書。他の辞書と同様に、これには、後で特定のクライアントと別の人との関係を説明するときに使用する一意の名前のリストが含まれます。
実際の関係データはclient_relatedに保存されます テーブル。このテーブルのレコードごとに、クライアント( client_id )への参照を保存します )、関係者( person_id )、その関係の性質( client_relation_type_id )、すべての追加の詳細( details )(存在する場合)、およびリレーションが現在アクティブであるかどうかを示すフラグ( is_active )。このテーブルの代替キーは、 client_idの組み合わせによって定義されます。 、 person_id 、および client_relation_type_id 。
サブジェクトエリア#4:オファー
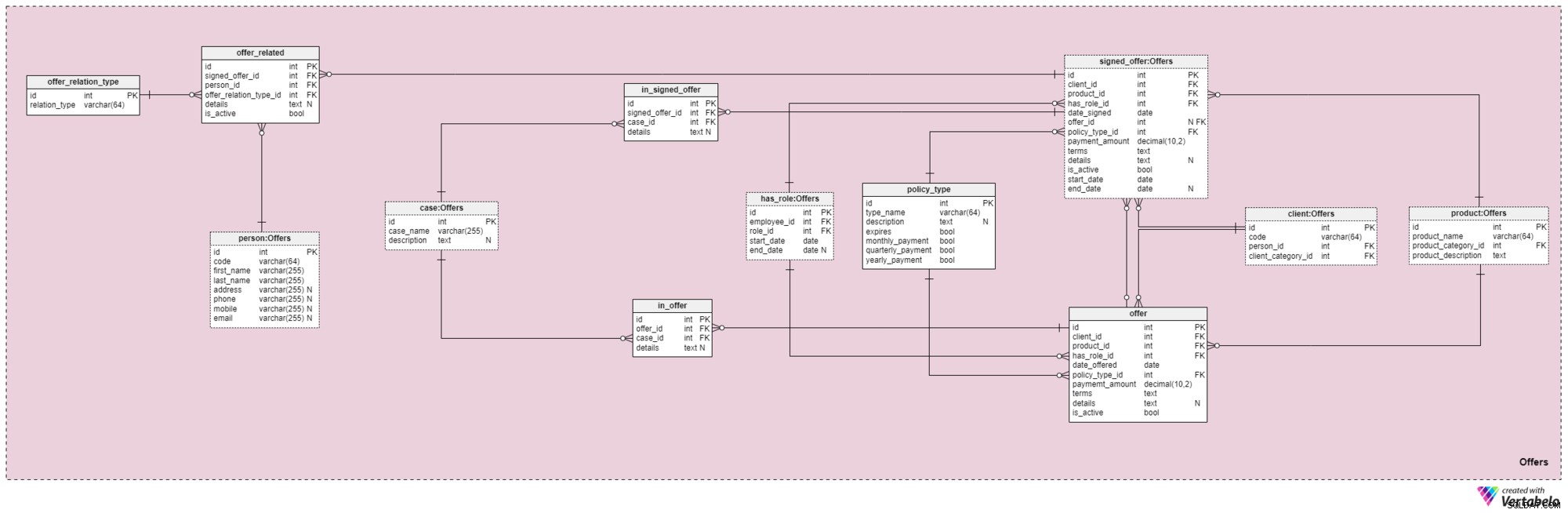
このサブジェクトエリアとそれに続くサブジェクトエリアは、このデータモデルの中心です。それらは、オファーと署名されたポリシー、およびオファーに関連する支払いをカバーします。まず、オファーのサブジェクトエリアについて説明します。 12個のテーブルが含まれているため、複雑に見える場合があります。ただし、これら12個のうち4個( has_role 、製品 、クライアント 、および person )は以前の主題分野で説明されていたため、ここでは繰り返し説明しません。
オファー およびsigned_offer テーブルは、モデルに非常に類似したデータを格納するために使用されるため、類似した構造を持っています。ただし、提供 主に、クライアントに提供したポリシー(およびその詳細)を保存するために使用されます。 signed_offer テーブルは、当社と実際にポリシーに署名したクライアントに関する情報を格納するために厳密に使用されます。これらの表をまとめて説明し、表示される場所の違いに注意します。これら2つの表の属性は次のとおりです。
-
client_id—特定のオファーに署名したクライアントの一意の識別子への参照。 -
product_id—署名されたオファーに含まれていた製品の一意の識別子への参照。 -
has_role_id—従業員のIDと、オファーが提示/署名されたときに彼らが果たした役割への参照。 -
date_offeredおよびdate_signed—このオファーがクライアントに提示されたのはいつか、署名されたのはいつかを示す実際の日付。 -
offer_id—このクライアントの以前のオファーへの参照。これにはnullの値が含まれる可能性があります。これは、クライアントが会社からの以前のオファーがなくてもポリシーに署名した可能性があるためです。この属性は厳密にsigned_offerに属しますテーブル。 -
policy_type_id—クライアントに提供した、またはクライアントに署名させたポリシーのタイプを示すポリシータイプディクショナリへの参照。 -
payment_amount—クライアントがポリシーに対して定期的に支払う必要のある金額。 用語—テキスト(XML)形式の契約のすべての条件。アイデアは、この属性にポリシーの財務部分に関するすべての重要な詳細を保存することです。保存できるテキストの例としては、ポリシーの合計金額、クライアントが支払う必要のある支払いの数などがあります。詳細 —テキスト形式の追加の詳細。-
is_active—レコードがまだアクティブかどうかを示すフラグ。 -
start_dateおよびend_date—このポリシーがアクティブであった/アクティブだった時間範囲を示します。ポリシーが有効期間にわたって署名されている場合、end_dateにはnullの値が含まれます。
policy_typeもあります 前に簡単に触れた辞書。年齢、健康状態、結婚歴、信用リスクなどの要因に基づいて、同じ製品をさまざまなクライアントに提供する方法にある程度の柔軟性が必要です。ポリシータイプごとに、 type_nameを保存します 識別子、追加のテキスト description 、expiresという名前のフラグは、ポリシーが期限切れになる可能性があるかどうかを示し、別のフラグは、このポリシータイプのプレミアムを毎月、四半期ごと、または毎年支払う必要があるかどうかを示します。予想される保険の種類には、定期保険、終身保険、ユニバーサル保険、保証付き保険、変額保険、変額保険、退職後の生命保険などがあります。
次に、特定のポリシーでカバーできるすべてのケースと状況を定義する必要があります。これらのケースを特定のオファーおよび署名されたオファーに関連付ける必要があります。
ポリシーがカバーする可能性のあるすべてのケースのリストは、 caseに保存されています 辞書。このテーブルの各レコードは、その case_nameによって一意に識別できます。 追加のdescriptionがあります 、必要な場合。
in_offer およびin_signed_offer テーブルは同じデータを格納するため、同じ構造を共有します。 2つの違いは、最初の1つは単にクライアントに提供されたポリシーでカバーされたケースを格納するのに対し、2つ目はクライアントが署名したポリシーでケースを格納することです。これら2つのテーブルのレコードごとに、 offer_idの一意のペアを保存します / signed_offer_id およびcase_id 、後者は、ポリシーの対象となるケースまたはインシデントを示します。他のすべての詳細は、必要に応じてテキスト属性に保存されます。
前述したように、生命保険はほとんどの場合、顧客だけでなく、その家族や親戚にも関係しています。これらの関係もこの領域に保存する必要があります。これらはポリシーの署名時に定義されますが、ポリシーの期間中に変更することもできます。
最初に行う必要があるのは、リレーションに割り当てることができるすべての可能な値を含むディクショナリを作成することです。私たちのモデルでは、これは offer_relation_type 辞書。主キーを除いて、このテーブルには1つの属性( ratio_type )のみが含まれています。 –一意の値のみを保持できます。
もうすぐだ!このサブジェクトエリアの最後のテーブルのタイトルは、 offer_related 。これは、署名されたオファーをクライアントに関連するすべての人に関連付けます。したがって、署名されたポリシー( signed_offer_id )への参照を保存する必要があります )および関係者( person_id )また、その関係の性質を指定します( offer_relation_type_id )。さらに、 detailsを保存する必要があります このレコードに関連し、フラグを作成して、システムでまだ有効かどうかを確認します。
サブジェクトエリア#5:支払い
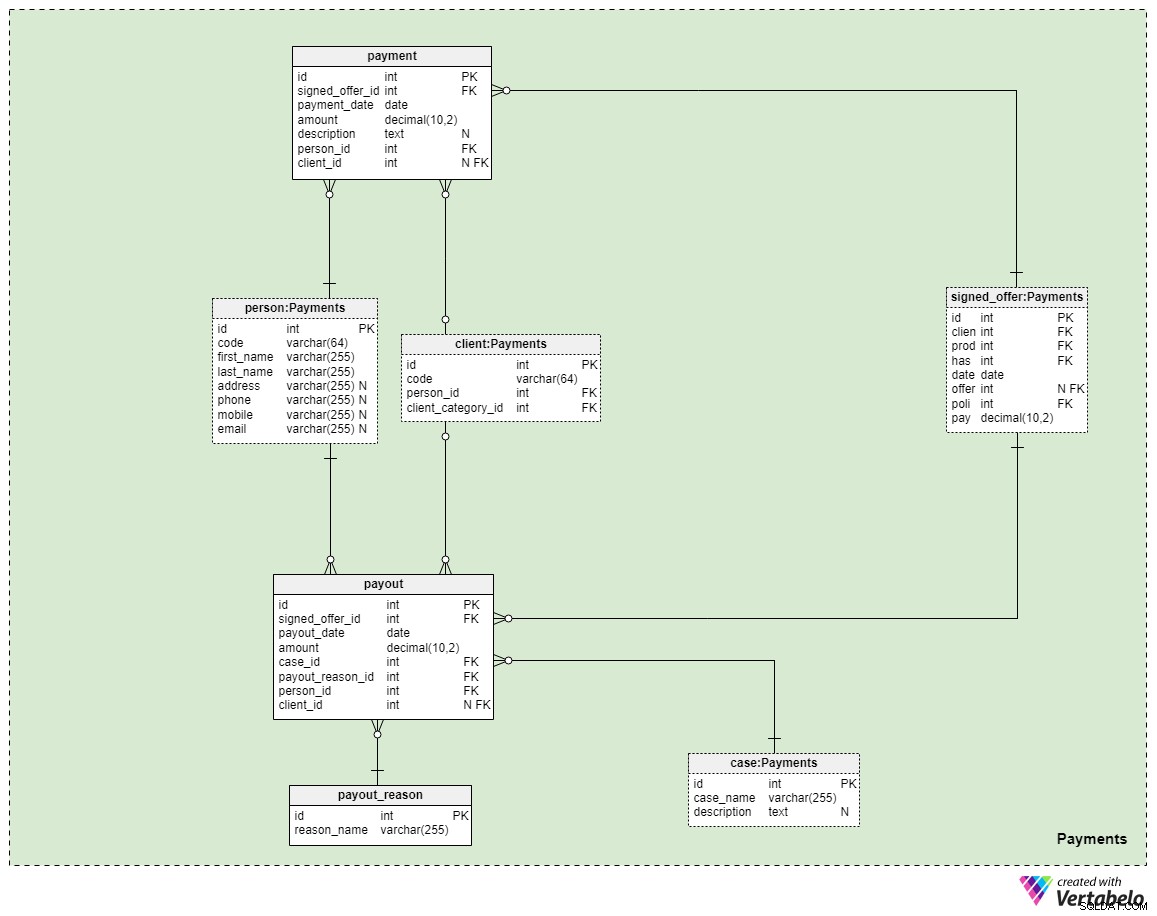
モデルの最後の主題領域は支払いに関するものです。ここでは、3つの新しいテーブルのみを紹介します:支払い 、 payout_reason 、および支払い 。
ポリシーに関連するすべての支払いは、支払いに保存されます テーブル。ここには最も重要な属性のみを含めました:
-
signed_offer_id—署名されたオファー(ポリシー)の一意の識別子への参照。 -
payment_date—この支払いが行われた日付。 金額—実際に支払われた金額。説明—テキスト形式での支払いのオプションの説明。-
person_id—支払いを行った人の一意の識別子への参照。オファーに署名したクライアントだけが支払いを行うことができるとは限らないことに注意してください。 -
client_id—支払いを行ったクライアントの一意の識別子への参照。この属性には、クライアント自身が支払いを行った場合にのみ値が含まれます。
残りの2つの表は、生命保険に支払う最も重要な理由を表しています。何かが起こった場合に、家族または生命/ビジネスパートナーに支払いが行われます。これがどのように発生するかは、状況と署名した特定のポリシーの条件によって異なります。これらのケースをカバーするために、2つの簡単な表を使用します。
1つ目は、 payout_reasonというタイトルの辞書です。 古典的な辞書構造を備えています。主キー属性を除いて、属性は reason_nameの1つだけです。 –この支払いが行われた理由を示す一意の値のリストが保存されます。
モデルの最後のテーブルはpayout テーブル。 支払いと非常によく似ています 表ですが、最も重要な違いを以下に示します:
-
payout_date—支払いが行われた日付。 -
case_id—支払いをトリガーした関連するケースまたはインシデントの一意の識別子への参照。これは、ポリシーに含まれているIDの1つと一致する必要があります。 -
payout_reason_id—支払いの理由をより詳細に説明している辞書への参照。支払いのケースはより短く、より一般的ですが、支払いの理由により、何が起こったのかについてより具体的な詳細が提供されます。 -
person_idおよびclient_id—支払いに関連する個人とクライアントをそれぞれ参照します。
概要
素晴らしい!生命保険データモデルの構築に成功しました。議論を締めくくる前に、このモデルでカバーできるものがもっとたくさんあることに注意する価値があります。この記事では、モデルの外観と機能を理解するために、主にモデルの基本について説明しました。このようなデータモデルに組み込むことができる詳細は次のとおりです。
- 追加のポリシーのアップグレードは、現在のモデルではカバーされていません(たとえば、既存のポリシーに対して毎年オファーを行いたい場合、この構造ではそれを行うことはできません)。提示/署名されたオファーのすべてのポリシー変更を保存するために、さらにいくつかのテーブルを追加する必要があります。
- すべての事務処理は意図的に省略されています。もちろん、特定の生命保険契約に関連する事務処理は、特に署名プロセスと支払いに関して非常に多くなります。ポリシーに署名した時点でのクライアントのステータスとその過程での変更を説明するドキュメント、および支払いに関連するドキュメントを添付することができます。
- このモデルには、ポリシーリスクの計算に必要な構造が組み込まれていません。テストする必要のあるすべてのパラメータと、クライアントの値が全体的な計算にどのように影響するかを決定する範囲が必要です。これらの計算の結果は、オファーおよび署名されたポリシーごとに保存する必要があります。
- 実際の請求書の構造は、支払いの対象分野で取り上げたものよりもはるかに複雑です。モデルのどこにも金融口座については触れていません。
明らかに、保険事業は非常に複雑です。この記事では、生命保険のデータモデルについてのみ説明しました。さまざまな種類の保険を提供する会社を運営する場合、このデータモデルがどのように進化するか想像できますか?そのような会社の組織化されたデータモデルを提示するには、確かに多くの計画と思考が必要です。
データモデルを改善するための提案やアイデアがあれば、下のコメントでお気軽にお知らせください!