インフルエンザの予防接種を受けたことがないすべての患者を見つけたいとしましょう。または、 AdventureWorks2012 、同様の質問は、「注文したことのないすべての顧客を見せてください」というものかもしれません。 NOT INを使用して表現 、私がよく目にするパターンは、次のようになります(Jonathan Kehayias(@SQLPoolBoy)によるこのスクリプトの拡大されたヘッダーと詳細テーブルを使用しています):
SELECT CustomerID FROM Sales.Customer WHERE CustomerID NOT IN ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged );
このパターンを見ると、しわがれます。ただし、パフォーマンス上の理由ではありません。結局のところ、この場合は十分に適切な計画が作成されます。
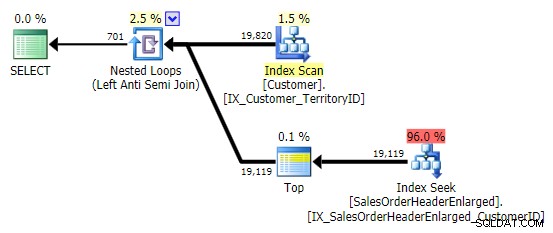
主な問題は、ターゲット列がNULL可能である場合、結果が驚くべきものになる可能性があることです(SQL Serverはこれを左の反半結合として処理しますが、右側のNULLが等しいか等しくないかを確実に判断することはできません) –左側の参照)。また、列にNULL値が含まれていない場合でも、列がNULL可能である場合、最適化の動作が異なる可能性があります(Gail Shawは2010年にこれについて話しました)。
この場合、ターゲット列はnull許容ではありませんが、 NOT INに関する潜在的な問題について言及したいと思います。 –今後の投稿で、これらの問題をさらに徹底的に調査する可能性があります。
TL;DRバージョン
NOT INの代わりに 、相関のある NOT EXISTSを使用します このクエリパターンの場合。いつも。他のすべての変数が同じである場合、他の方法はパフォーマンスの点でそれに匹敵する可能性がありますが、他のすべての方法はパフォーマンスの問題または他の課題のいずれかをもたらします。
代替案
では、このクエリを他にどのように書くことができますか?
外部適用
この結果を表現する1つの方法は、相関のある OUTER APPLYを使用することです。 。
SELECT c.CustomerID FROM Sales.Customer AS c OUTER APPLY ( SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged WHERE CustomerID = c.CustomerID ) AS h WHERE h.CustomerID IS NULL;
論理的には、これも左反半結合ですが、結果の計画には左反半結合演算子がなく、 NOT INよりもかなり高価なようです。 同等。これは、左のアンチセミジョインではなくなったためです。実際には別の方法で処理されます。外部結合により、一致する行と一致しない行がすべて取り込まれ、*次に*フィルターが適用されて一致が削除されます。
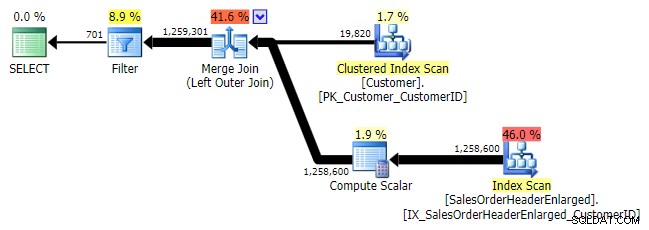
左外側の結合
より一般的な代替手段は、 LEFT OUTER JOINです。 ここで、右側は NULLです。 。この場合、クエリは次のようになります。
SELECT c.CustomerID FROM Sales.Customer AS c LEFT OUTER JOIN Sales.SalesOrderHeaderEnlarged AS h ON c.CustomerID = h.CustomerID WHERE h.CustomerID IS NULL;
これは同じ結果を返します。ただし、OUTER APPLYと同様に、すべての行を結合し、一致を削除するという同じ手法を使用します。
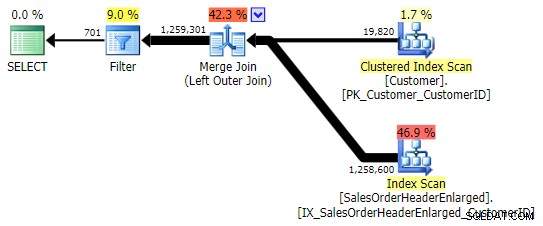
ただし、 NULLをチェックする列については注意が必要です。 。この場合、 CustomerID 結合列であるため、論理的な選択です。また、インデックスが作成されます。 SalesOrderIDを選ぶこともできます 、これはクラスタリングキーであるため、 CustomerIDのインデックスにも含まれています。 。しかし、結合に使用されたインデックスに含まれていない(または後で削除される)別の列を選択して、別の計画に導くこともできます。または、NULL可能列でさえ、不正確な(または少なくとも予期しない)結果につながります。存在しない行と存在するがその列が NULL> 。そして、これが事実であることは、読者/開発者/トラブルシューティング担当者には明らかではないかもしれません。したがって、これら3つの WHEREもテストします。 条項:
WHERE h.SalesOrderID IS NULL; -- clustered, so part of index WHERE h.SubTotal IS NULL; -- not nullable, not part of the index WHERE h.Comment IS NULL; -- nullable, not part of the index
最初のバリエーションは、上記と同じ計画を作成します。他の2つは、マージ結合の代わりにハッシュ結合を選択し、 Customerでより狭いインデックスを選択します クエリが最終的にまったく同じページ数とデータ量を読み取ることになったとしても、テーブル。ただし、 h.SubTotal バリエーションは正しい結果を生成します:
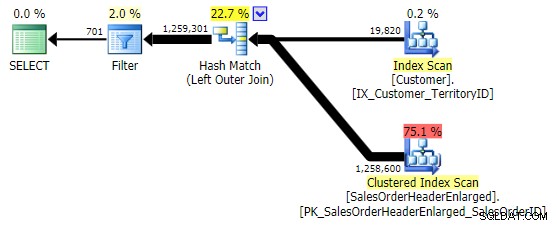
h.Comment h.Comment IS NULL のすべての行が含まれているため、バリエーションは含まれません。 、およびどの顧客にも存在しなかったすべての行。フィルタを適用した後の出力の行数の微妙な違いを強調しました:
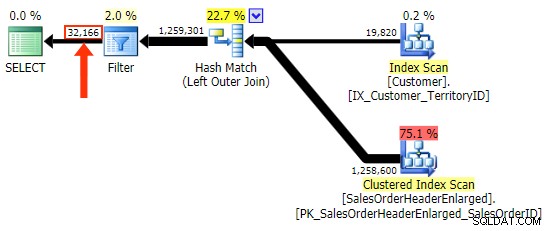
フィルタでの列の選択に注意する必要があることに加えて、 LEFT OUTER JOINで私が抱えているもう1つの問題があります。 形式は、 FROM dbo.table_a、dbo.table_b WHERE ... の「古いスタイル」形式の内部結合と同じように、自己文書化ではないということです。 自己文書化ではありません。つまり、 WHERE にプッシュされると、結合基準を忘れがちです。 句、またはそれが他のフィルター基準と混ざり合うために。これはかなり主観的なことだと思いますが、あります。
例外
関心があるのが結合列(定義上、両方のテーブルにある)だけの場合は、 EXCEPTを使用できます。 –これらの会話ではあまり出てこないように見える代替手段(おそらく–通常–比較していない列を含めるためにクエリを拡張する必要があるため):
SELECT CustomerID FROM Sales.Customer AS c EXCEPT SELECT CustomerID FROM Sales.SalesOrderHeaderEnlarged;
これは、 NOT INとまったく同じ計画を立てます 上記のバリエーション:
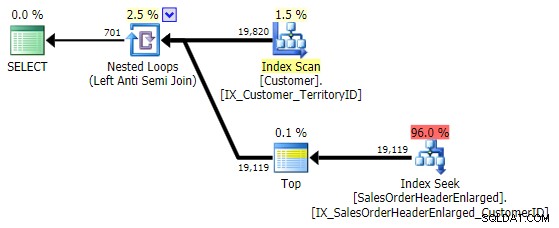
覚えておくべきことの1つは、 EXCEPTということです。 暗黙のDISTINCTが含まれています –したがって、「左」テーブルに同じ値を持つ複数の行が必要な場合は、このフォームでそれらの重複を排除します。この特定のケースでは問題ではありません。UNIONのように、覚えておくべきことがあります。 対UNIONALL 。
存在しません
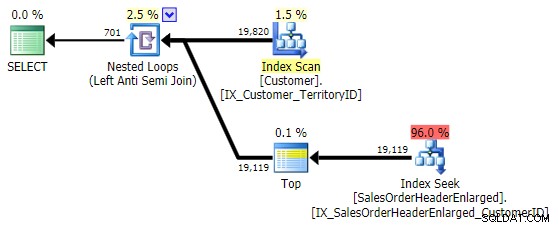
このパターンに対する私の好みは間違いなくNOTEXISTS :
SELECT CustomerID
FROM Sales.Customer AS c
WHERE NOT EXISTS
(
SELECT 1
FROM Sales.SalesOrderHeaderEnlarged
WHERE CustomerID = c.CustomerID
);
(はい、 SELECT 1を使用します SELECT *の代わりに …パフォーマンス上の理由ではありません。SQLServerは、 EXISTS内で使用する列を気にしないためです。 そしてそれらを最適化しますが、単に意図を明確にするためです。これは、この「サブクエリ」が実際にはデータを返さないことを思い出させます。)
そのパフォーマンスはNOTINに似ています およびEXCEPT 、そしてそれは同一の計画を作成しますが、NULLまたは重複によって引き起こされる潜在的な問題の傾向はありません:
パフォーマンステスト
コールドキャッシュとウォームキャッシュの両方を使用して多数のテストを実行し、 NOT EXISTSに関する長年の認識を検証しました。 正しい選択であることは真実のままでした。典型的な出力は次のようになりました:
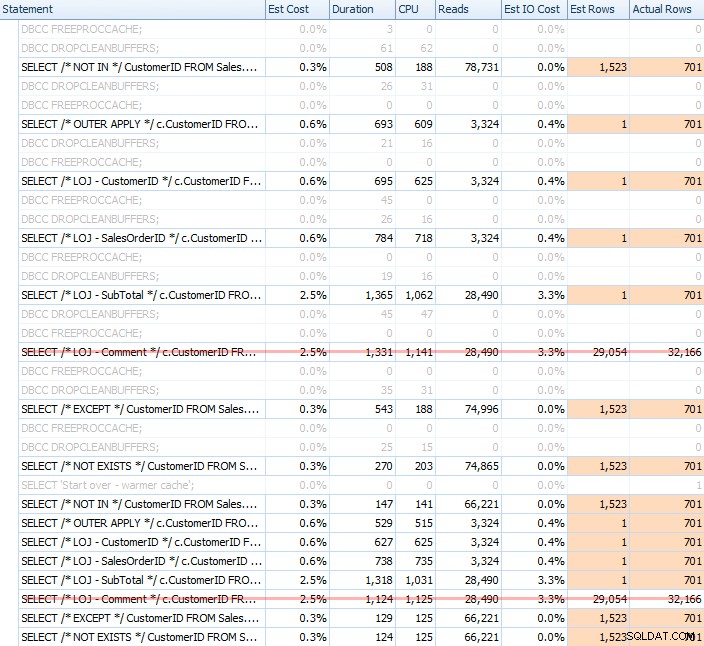
グラフに20回の実行の平均パフォーマンスを表示するときに、誤った結果をミックスから除外し(結果がどれほど間違っているかを示すためにのみ含めました)、テスト全体で異なる順序でクエリを実行して、その1つのクエリは、前のクエリの作業から一貫して恩恵を受けていませんでした。期間に焦点を当てて、結果は次のとおりです。
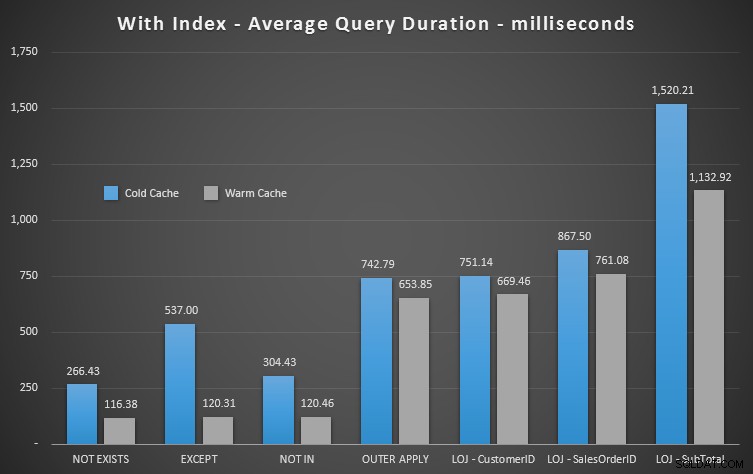
期間を調べて読み取りを無視すると、NOT EXISTSが勝者になりますが、それほど多くはありません。 EXCEPTとNOTINはそれほど遅れていませんが、パフォーマンス以上のものを調べて、これらのオプションが有効かどうかを判断し、シナリオでテストする必要があります。
サポートするインデックスがない場合はどうなりますか?
もちろん、上記のクエリは、 Sales.SalesOrderHeaderEnlarged.CustomerIDのインデックスから恩恵を受けます。 。このインデックスを削除すると、これらの結果はどのように変化しますか?インデックスを削除した後、同じ一連のテストを再度実行しました:
DROP INDEX [IX_SalesOrderHeaderEnlarged_CustomerID] ON [Sales].[SalesOrderHeaderEnlarged];
今回は、異なるメソッド間のパフォーマンスの点ではるかに少ない偏差がありました。最初に、各メソッドの計画を示します(そのほとんどは、当然のことながら、削除したばかりの欠落しているインデックスの有用性を示しています)。次に、コールドキャッシュとウォームキャッシュの両方を使用したパフォーマンスプロファイルを示す新しいグラフを表示します。
存在しない、存在しない(3つすべてが同一)
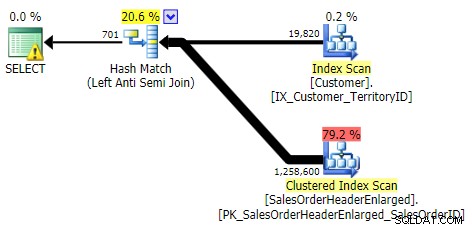
外部適用
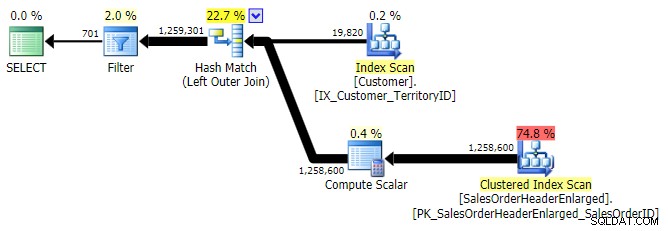
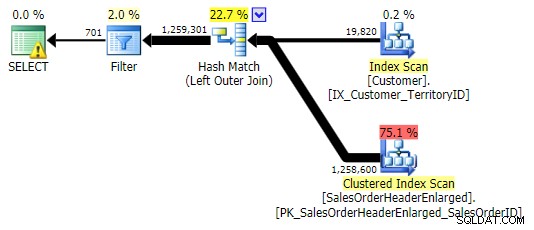
LEFT OUTER JOIN(行数を除いて3つすべてが同一でした)
パフォーマンス結果
これらの新しい結果を見ると、インデックスがどれほど有用であるかがすぐにわかります。 1つの場合(とにかくインデックスの外側にある左外側の結合)を除いて、インデックスを削除すると、結果は明らかに悪化します:
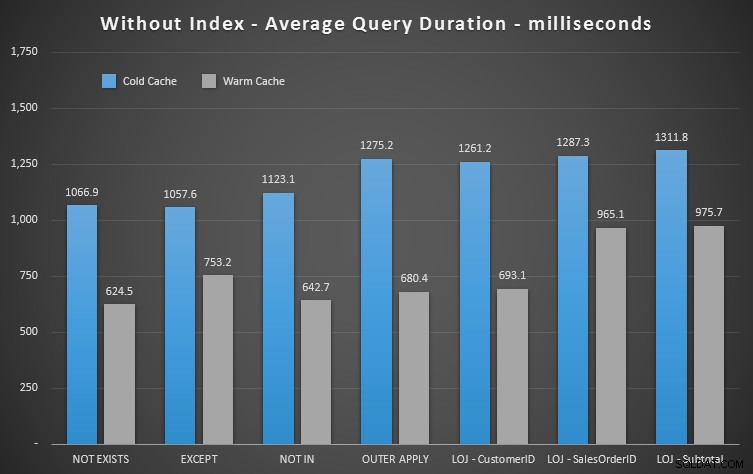
したがって、目立った影響は少ないものの、 NOT EXISTS であることがわかります。 期間の点でまだあなたの限界勝者です。また、他のアプローチがスキーマの変動の影響を受けやすい状況では、それも最も安全な選択です。
結論
これは、テーブルBに何らかの条件が存在しないテーブルAのすべての行を検索するパターンの場合、 NOT EXISTS であることを伝えるための非常に長い方法でした。 通常、最良の選択になります。ただし、いつものように、スキーマ、データ、ハードウェアを使用して、独自の環境でこれらのパターンをテストし、独自のワークロードと混合する必要があります。