[パート1|パート2|パート3|パート4]
SELECTの理解と最適化については、何年にもわたって多くのことが書かれてきました。 クエリですが、データの変更についてはあまりありません。この一連の投稿では、INSERTに固有の問題について説明します。 、UPDATE 、DELETE およびMERGE クエリ–ハロウィーンの問題。
「HalloweenProblem」というフレーズは、もともとSQL UPDATEを参照して造られました。 収益が25,000ドル未満のすべての従業員に10%の昇給を与えることになっているクエリ。問題は、クエリが全員まで10%のレイズを出し続けることでした。 少なくとも25,000ドルを稼いだ。このシリーズの後半で、根本的な問題がINSERTにも当てはまることがわかります。 、DELETE およびMERGE クエリですが、この最初のエントリについては、UPDATEを調べると役立ちます。 少し詳細に問題があります。
背景
SQL言語は、ユーザーがUPDATEを使用してデータベースの変更を指定する方法を提供します。 ステートメントですが、構文は方法については何も述べていません。 データベースエンジンが変更を実行する必要があります。一方、SQL標準では、UPDATEの結果が指定されています。 必須 重複しない3つの別々のフェーズで実行された場合と同じである:
- 読み取り専用検索により、変更するレコードと新しい列の値が決定されます
- 変更は影響を受けるレコードに適用されます
- データベースの整合性の制約が検証されます
これらの3つのフェーズを文字通りデータベースエンジンに実装すると、正しい結果が得られますが、パフォーマンスはあまり良くない可能性があります。各段階の中間結果にはシステムメモリが必要であり、システムが同時に実行できるクエリの数が減ります。必要なメモリも使用可能なメモリを超える可能性があり、更新セットの少なくとも一部をディスクストレージに書き出して、後で再度読み取る必要があります。最後になりましたが、この実行モデルでは、テーブルの各行を複数回タッチする必要があります。
別の戦略は、UPDATEを処理することです 一度に1行。これには、各行に1回だけ触れるという利点があり、通常、ストレージ用のメモリは必要ありません(ただし、完全な並べ替えなどの一部の操作では、出力の最初の行を生成する前に完全な入力セットを処理する必要があります)。この反復モデルは、SQLServerクエリ実行エンジンで使用されるモデルです。
クエリオプティマイザの課題は、UPDATEを満たす反復(行ごと)の実行プランを見つけることです。 パイプライン実行のパフォーマンスと同時実行性の利点を維持しながら、SQL標準に必要なセマンティクス。
更新処理
元の問題を説明するために、Employeesを使用して、収益が25,000ドル未満の各従業員に10%の昇給を適用します。 以下の表:

CREATE TABLE dbo.Employees
(
Name nvarchar(50) NOT NULL,
Salary money NOT NULL
);
INSERT dbo.Employees
(Name, Salary)
VALUES
('Brown', $22000),
('Smith', $21000),
('Jones', $25000);
UPDATE e
SET Salary = Salary * $1.1
FROM dbo.Employees AS e
WHERE Salary < $25000; 3フェーズの更新戦略
読み取り専用の最初のフェーズでは、WHEREを満たすすべてのレコードが検索されます 節の述語であり、第2フェーズがその作業を行うために十分な情報を保存します。実際には、これは、適格な行ごとに一意の識別子(クラスター化されたインデックスキーまたはヒープ行識別子)と新しい給与値を記録することを意味します。フェーズ1が完了すると、更新情報のセット全体が2番目のフェーズに渡されます。このフェーズでは、一意の識別子を使用して更新する各レコードを検索し、給与を新しい値に変更します。次に、第3フェーズでは、データベースの整合性制約がテーブルの最終状態によって違反されていないことを確認します。
反復戦略
このアプローチでは、ソーステーブルから一度に1行ずつ読み取ります。行がWHEREを満たす場合 節の述語、昇給が適用されます。このプロセスは、すべての行がソースから処理されるまで繰り返されます。このモデルを使用した実行計画の例を以下に示します。

SQL Serverのデマンドドリブンパイプラインでは通常どおり、実行は左端の演算子であるUPDATEから開始されます。 この場合。これは、Compute Scalarからの行を要求するテーブル更新からの行を要求し、テーブルスキャンへのチェーンをたどります:
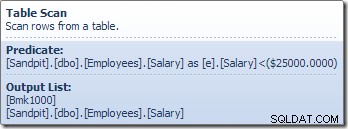
テーブルスキャンオペレータは、給与述語を満たす行が見つかるまで、ストレージエンジンから一度に1行ずつ読み取ります。上の図の出力リストは、行IDとこの行のSalary列の現在の値を返すテーブルスキャン演算子を示しています。これら2つの情報への参照を含む単一の行がComputeScalarに渡されます:
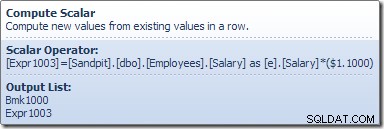
Compute Scalarは、昇給を現在の行に適用する式を定義します。行識別子への参照と変更された給与を含む行をテーブル更新に返します。テーブル更新は、ストレージエンジンを呼び出してデータ変更を実行します。この反復プロセスは、テーブルスキャンの行がなくなるまで続きます。テーブルにクラスター化されたインデックスがある場合も、同じ基本的なプロセスに従います。
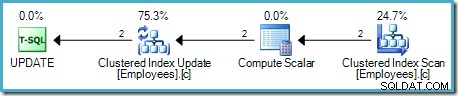
主な違いは、クラスター化されたインデックスキーと一意化子(存在する場合)がヒープRIDの代わりに行識別子として使用されることです。
問題
SQL標準で定義されている論理的な3フェーズ操作から物理的な反復実行モデルへの変更により、いくつかの微妙な変更が導入されましたが、本日はそのうちの1つのみを取り上げます。実行中の例では、Salary列に非クラスター化インデックスがあり、クエリオプティマイザーがこれを使用して適格な行を検索することを決定した場合に問題が発生する可能性があります(Salary <$ 25,000):
CREATE NONCLUSTERED INDEX nc1 ON dbo.Employees (Salary);
行ごとの実行モデルは、誤った結果を生成したり、無限ループに陥ったりする可能性があります。給与インデックスを探し、一度に1行ずつCompute Scalarに返し、最終的にはUpdate演算子に返す(架空の)反復実行プランについて考えてみます。

このプランには、給与値が変更されていない場合に非クラスター化インデックスのメンテナンスをスキップする最適化のために、追加のCompute Scalarがいくつかあります(この場合、給与がゼロの場合にのみ可能です)。
これを無視すると、このプランの重要な機能は、同じインデックスを変更するオペレーターに一度に1行ずつ渡す順序付き部分インデックススキャンがあることです(上のSQL Sentryプランエクスプローラーの図の緑色のハイライトにより、クラスター化が明確になります)インデックス更新演算子は、ベーステーブルと非クラスター化インデックスの両方を維持します。
とにかく、問題は、一度に1行を処理することにより、更新が現在の行をインデックスシークが変更する行を見つけるために使用するスキャン位置の前に移動できることです。例を実行すると、そのステートメントが少し明確になるはずです。
非クラスター化インデックスは、給与値に基づいてキーが付けられ、昇順で並べ替えられます。インデックスには、ベーステーブルの親行へのポインタも含まれます(ヒープRIDまたはクラスター化インデックスキーと必要に応じて一意化子のいずれか)。例をわかりやすくするために、ベーステーブルの[名前]列に一意のクラスター化インデックスがあると仮定します。したがって、更新処理の開始時の非クラスター化インデックスの内容は次のとおりです。
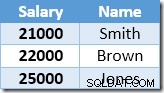
Index Seekによって返される最初の行は、Smithの21,000ドルの給与です。この値は、クラスター化インデックス演算子によってベーステーブルと非クラスター化インデックスで$23,100に更新されます。非クラスター化インデックスには、次のものが含まれるようになりました。
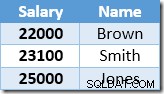
Index Seekによって返される次の行は、Brownの$ 22,000エントリで、$24,200に更新されます。
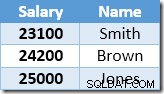
これで、インデックスシークはスミスの23,100ドルの値を見つけます。これは、もう一度更新されます。 、$25,410まで。このプロセスは、すべての従業員の給与が25,000ドル以上になるまで続きます。これは、特定のUPDATEの正しい結果ではありません。 クエリ。他の状況での同じ影響により、サーバーがログスペースを使い果たした場合、またはオーバーフローエラーが発生した場合にのみ終了する暴走更新が発生する可能性があります(この場合、給与がゼロの場合に発生する可能性があります)。 これはアップデートに適用されるハロウィーンの問題です。
更新のためのハロウィーンの問題の回避
イーグルアイの読者は、架空のインデックスシークプランの推定コストパーセンテージが100%にならないことに気付くでしょう。これはプランエクスプローラーの問題ではありません。プランからキーオペレーターを意図的に削除しました:

クエリオプティマイザは、このパイプライン更新プランがハロウィーンの問題に対して脆弱であることを認識し、それが発生しないようにEagerテーブルスプールを導入します。正確さのために必要であるため、この実行プランにスプールが含まれないようにするためのヒントまたはトレースフラグはありません。
その名前が示すように、スプールは、親のCompute Scalarに行を返す前に、子演算子(Index Seek)からのすべての行を熱心に消費します。これの効果は、完全な相分離を導入することです。 –更新が実行される前に、対象となるすべての行が読み取られ、一時ストレージに保存されます。
これにより、SQL標準の3フェーズの論理セマンティクスに近づきますが、プランの実行は基本的に反復的であり、スプールの右側の演算子が読み取りカーソルを形成することに注意してください。 、および左側の演算子は書き込みカーソルを形成します 。スプールの内容は引き続き読み取られ、行ごとに処理されます(一括は渡されません) SQL標準との比較により、信じられないかもしれません。
相分離の欠点は前述と同じです。テーブルスプールはtempdbを消費します スペース(バッファプール内のページ)であり、メモリ不足下でディスクへの物理的な読み取りと書き込みが必要になる場合があります。クエリオプティマイザは、見積もりコストをスプールに割り当て(見積もりに関する通常のすべての警告に従います)、ハロウィーンの問題に対する保護が必要なプランと、通常の見積もりコストに基づいていないプランのどちらかを選択します。当然、オプティマイザは通常の理由でオプションを誤って選択する可能性があります。
この場合、トレードオフは、適格なレコード(給与が25,000ドル未満のレコード)を直接検索することによる効率の向上と、ハロウィーンの問題を回避するために必要なスプールの推定コストとの間です。別の計画(この特定の場合)は、クラスター化されたインデックス(またはヒープ)のフルスキャンです。 キーのため、この戦略では同じハロウィーン保護は必要ありません。 クラスタ化されたインデックスのは変更されません:

インデックスキーは安定しているため、行は反復間でインデックス内の位置を移動できず、この場合のハロウィーンの問題を回避できます。以前に見たインデックスシークとイーガーテーブルスプールの組み合わせと比較したクラスター化インデックススキャンの実行時コストによっては、一方のプランがもう一方のプランよりも高速に実行される場合があります。もう1つの考慮事項は、Halloween Protectionを使用したプランでは、完全にパイプライン化されたプランよりも多くのロックが取得され、ロックがより長く保持されることです。
最終的な考え
ハロウィーンの問題とそれがデータ変更クエリプランに与える影響を理解することは、データを変更する実行プランを分析するのに役立ち、代替手段が利用可能な場合に不要な保護のコストと副作用を回避する機会を提供できます。
ハロウィーンの問題にはいくつかの形式がありますが、すべてが共通のインデックスのキーの読み取りと書き込みによって引き起こされるわけではありません。ハロウィーンの問題もUPDATEに限定されません クエリ。クエリオプティマイザには、熱心なテーブルスプールを使用したブルートフォースの相分離以外に、ハロウィーンの問題を回避するためのより多くのトリックがあります。これらのポイント(およびそれ以上)については、このシリーズの次回の記事で説明します。
[パート1|パート2|パート3|パート4]