パーティショニングは、管理性、メンテナンスタスク、またはロックとブロックに関連する課題を軽減するために実装されることが多いSQLServerの機能です。大きなテーブルの管理は、パーティション化によって簡単になり、スケーラビリティーと可用性を向上させることができます。さらに、パーティショニングの副産物により、クエリのパフォーマンスを向上させることができます。これは保証でも与えられたものでもありません。また、パーティショニングを実装する原動力となる理由でもありませんが、大きなテーブルをパーティショニングする場合は確認する価値があります。
背景
簡単に説明すると、SQLServerのパーティション分割機能はEnterpriseEditionとDeveloperEditionでのみ使用できます。パーティショニングは、データベースの初期設計時に実装することも、テーブルにデータがすでに含まれている後に配置することもできます。データを含む既存のテーブルをパーティション化されたテーブルに変更することは必ずしも迅速かつ簡単ではないことを理解してください。ただし、適切な計画を立てることで非常に実現可能であり、メリットをすばやく実現できます。
パーティションテーブルとは、特定の列(パーティション関数で定義されるパーティション列と呼ばれる)の値に基づいて、データがより小さな物理構造に分割されるテーブルです。データを年ごとに分離する場合は、DateSoldという列をパーティション化列として使用すると、2013年のすべてのデータが1つの構造に存在し、2012年のすべてのデータが別の構造に存在するなどです。これらの別々のデータセット集中的なメンテナンス(インデックス全体ではなく、インデックスのパーティションのみを再構築できます)を可能にし、データをテーブルに実際に追加またはテーブルから削除する前にステージングできるため、データをすばやく追加および削除できます。
セットアップ
パーティション化されたテーブルとパーティション化されていないテーブルのクエリパフォーマンスの違いを調べるために、AdventureWorks2012データベースからSales.SalesOrderHeaderテーブルのコピーを2つ作成しました。パーティション化されていないテーブルは、テーブルの従来の主キーであるSalesOrderIDのクラスター化インデックスのみを使用して作成されました。 2番目のテーブルはOrderDateで分割され、OrderDateとSalesOrderIDがクラスタリングキーとして使用され、追加のインデックスはありませんでした。パーティショニングに使用する列を決定する際に考慮すべき要素が多数あることに注意してください。パーティション化は、常にではありませんが、多くの場合、日付フィールドを使用してパーティションの境界を定義します。そのため、この例ではOrderDateが選択され、サンプルクエリを使用してSalesOrderHeaderテーブルに対する一般的なアクティビティをシミュレートしました。両方のテーブルを作成してデータを入力するためのステートメントは、ここからダウンロードできます。
テーブルを作成してデータを追加した後、既存のインデックスが検証され、統計がFULLSCANで更新されました:
EXEC sp_helpindex 'Sales.Big_SalesOrderHeader'; GO EXEC sp_helpindex 'Sales.Part_SalesOrderHeader'; GO UPDATE STATISTICS [Sales].[Big_SalesOrderHeader] WITH FULLSCAN; GO UPDATE STATISTICS [Sales].[Part_SalesOrderHeader] WITH FULLSCAN; GO SELECT sch.name + '.' + so.name AS [Table], ss.name AS [Statistic], sp.last_updated AS [Stats Last Updated], sp.rows AS [Rows], sp.rows_sampled AS [Rows Sampled], sp.modification_counter AS [Row Modifications] FROM sys.stats AS ss INNER JOIN sys.objects AS so ON ss.[object_id] = so.[object_id] INNER JOIN sys.schemas AS sch ON so.[schema_id] = sch.[schema_id] OUTER APPLY sys.dm_db_stats_properties(so.[object_id], ss.stats_id) AS sp WHERE so.[object_id] IN (OBJECT_ID(N'Sales.Big_SalesOrderHeader'), OBJECT_ID(N'Sales.Part_SalesOrderHeader')) AND ss.stats_id = 1;>
さらに、両方のテーブルのデータの分布はまったく同じであり、断片化は最小限に抑えられています。
単純なクエリのパフォーマンス
追加のインデックスを追加する前に、両方のテーブルに対して基本的なクエリを実行して、2012年12月に発注された注文に対して営業担当者が獲得した合計を計算しました。
SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Big_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO SELECT [SalesPersonID], SUM([TotalDue]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' GROUP BY [SalesPersonID]; GO統計IO出力
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Big_SalesOrderHeader'。スキャンカウント9、論理読み取り2710440、物理読み取り2226、先読み読み取り2658769、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Part_SalesOrderHeader'。スキャンカウント9、論理読み取り248128、物理読み取り3、先読み読み取り245030、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。

12月の営業担当者別の合計–パーティション化されていないテーブル
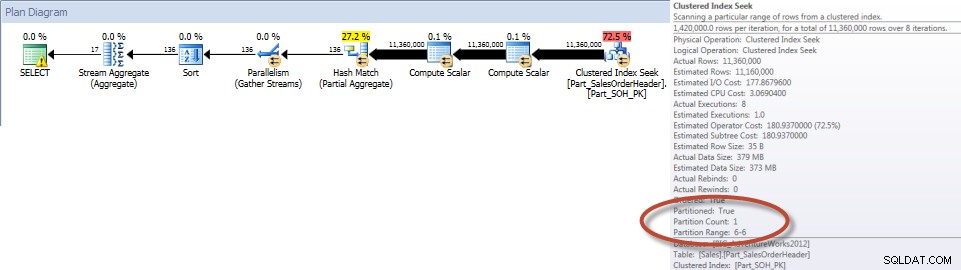
12月の営業担当者別の合計–パーティションテーブル
予想どおり、パーティション化されていないテーブルに対するクエリでは、テーブルをサポートするインデックスがなかったため、テーブルのフルスキャンを実行する必要がありました。対照的に、パーティション化されたテーブルに対するクエリは、テーブルの1つのパーティションにアクセスするためだけに必要でした。
公平を期すために、これが異なる日付範囲で繰り返し実行されるクエリである場合、適切な非クラスター化インデックスが存在します。例:
CREATE NONCLUSTERED INDEX [Big_SalesOrderHeader_SalesPersonID] ON [Sales].[Big_SalesOrderHeader] ([OrderDate]) INCLUDE ([SalesPersonID], [TotalDue]);
このインデックスが作成された状態でクエリを再実行すると、I / O統計が削除され、非クラスター化インデックスを使用するようにプランが変更されます。
統計IO出力
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Big_SalesOrderHeader'。スキャンカウント9、論理読み取り42901、物理読み取り3、先読み読み取り42346、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。

12月の営業担当者別の合計–非パーティションテーブルのNCI
サポートインデックスを使用すると、Sales.Big_SalesOrderHeaderに対するクエリは、Sales.Part_SalesOrderHeaderに対するクラスター化インデックススキャンよりも大幅に少ない読み取りで済みます。これは、クラスター化インデックスの幅がはるかに広いため、予期しないことではありません。 Sales.Part_SalesOrderHeaderに同等の非クラスター化インデックスを作成すると、同様のI/O番号が表示されます。
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_SalesPersonID] ON [Sales].[Part_SalesOrderHeader]([SalesPersonID]) INCLUDE ([TotalDue]);統計IO出力
テーブル'Part_SalesOrderHeader'。スキャンカウント9、論理読み取り42894、物理読み取り1、先読み読み取り42378、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
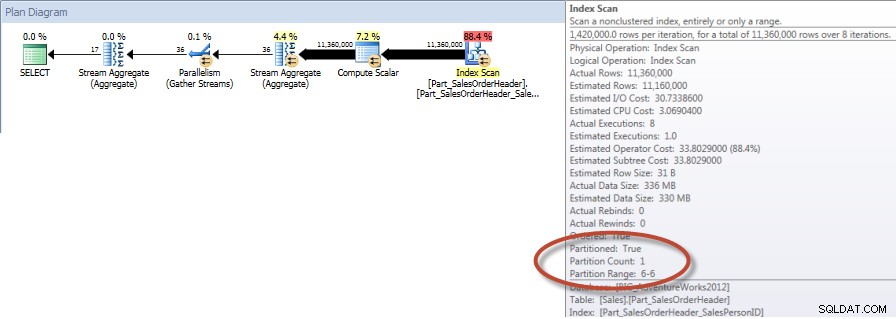
12月の営業担当者別の合計–削除されたパーティションテーブルのNCI
また、非クラスター化インデックススキャンのプロパティを見ると、エンジンが1つのパーティションにのみアクセスしたことを確認できます(6)。
最初に述べたように、パーティショニングは通常、パフォーマンスを向上させるために実装されていません。上記の例では、適切な非クラスター化インデックスが存在する限り、パーティションテーブルに対するクエリのパフォーマンスは大幅に向上しません。
アドホッククエリのパフォーマンス
パーティションテーブルに対するクエリはできます クエリがクラスター化インデックスを使用する必要がある場合など、場合によっては、パーティション化されていないテーブルに対して同じクエリよりもパフォーマンスが優れています。クエリの大部分を非クラスタ化インデックスでサポートするのが理想的ですが、一部のシステムではユーザーからのアドホッククエリを許可し、その他のシステムでは実行頻度が非常に低いため、インデックスのサポートを保証しません。 SalesOrderHeaderテーブルに対して、ユーザーは次のクエリを実行して、特定の顧客セットに対して、TotalDueが$ 1000を超える、年末までに出荷する必要があるが出荷しなかった2012年12月の注文を見つけることができます。
>SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Big_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO SELECT [SalesOrderID], [OrderDate], [DueDate], [ShipDate], [AccountNumber], [CustomerID], [SalesPersonID], [SubTotal], [TotalDue] FROM [Sales].[Part_SalesOrderHeader] WHERE [TotalDue] > 1000 AND [CustomerID] BETWEEN 10000 AND 20000 AND [OrderDate] BETWEEN '2012-12-01' AND '2012-12-31' AND [DueDate] < '2012-12-31' AND [ShipDate] > '2012-12-31'; GO統計IO出力
テーブル'Big_SalesOrderHeader'。スキャンカウント9、論理読み取り2711220、物理読み取り8386、先読み読み取り2662400、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Part_SalesOrderHeader'。スキャンカウント9、論理読み取り248128、物理読み取り0、先読み読み取り243792、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
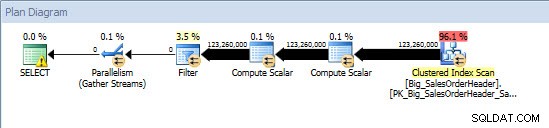
アドホッククエリ–非パーティションテーブル
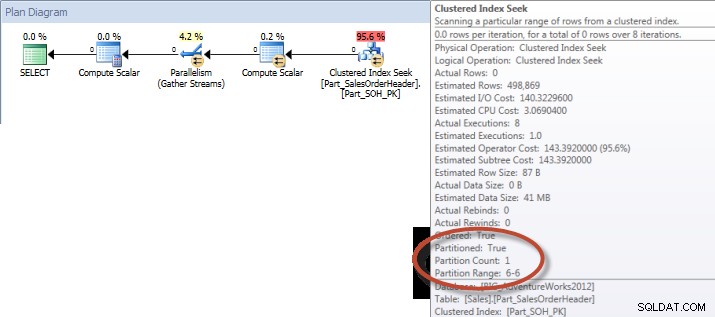
アドホッククエリ–パーティションテーブル
パーティション化されていないテーブルに対しては、クエリはクラスター化インデックスに対してフルスキャンを必要としましたが、エンジンはパーティションの削除を使用し、絶対に必要なデータのみを読み取るため、クエリはクラスター化インデックスのインデックスシークを実行しました。この例では、I / Oの点で大きな違いがあり、ハードウェアによっては、実行時間に劇的な違いが生じる可能性があります。適切なインデックスを追加することでクエリを最適化できますが、通常、すべてのインデックスを作成することはできません。 シングル クエリ。特に、アドホッククエリを可能にするソリューションの場合、ユーザーが何をしようとしているのかわからないと言っても過言ではありません。クエリは一度実行されても二度と実行されない場合があり、事後にインデックスを作成しても無駄です。したがって、パーティション化されていないテーブルからパーティション化されたテーブルに変更する場合は、通常のインデックス調整と同じ努力とアプローチを適用することが重要です。大部分のクエリをサポートするための適切なインデックスが存在することを確認する必要があります。
パフォーマンスとインデックスの調整
パーティション表の索引を作成するときに考慮すべき追加の要素は、索引を整列させるかどうかです。データをパーティションに切り替えたり、パーティションから切り替えたりする場合は、インデックスをテーブルに合わせる必要があります。パーティション化されたテーブルに非クラスター化インデックスを作成すると、デフォルトで整列インデックスが作成され、パーティション化列がインクルード列としてインデックスに追加されます。
非整列インデックスは、別のパーティションスキームまたは別のファイルグループを指定することによって作成されます。パーティション化列は、キー列またはインクルード列としてインデックスの一部にすることができますが、テーブルのパーティションスキームが使用されていない場合、または別のファイルグループが使用されている場合、インデックスは整列されません。
整列されたインデックスは、テーブルと同じようにパーティション化されます(データは別々の構造で存在するため)。したがって、パーティションの削除が発生する可能性があります。アラインされていないインデックスは1つの物理構造として存在し、述語によっては、クエリに期待されるメリットが得られない場合があります。月ごとにグループ化された、アカウント番号ごとの売上をカウントするクエリについて考えてみます。
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);
パーティショニングにあまり詳しくない場合は、クエリをサポートするために次のようなインデックスを作成できます(PRIMARYファイルグループが指定されていることに注意してください):
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_NotAL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]) ON [PRIMARY];
このインデックスは主キーの一部であるため、OrderDateが含まれていても、整列されていません。整列されたインデックスを作成する場合も列が含まれますが、構文の違いに注意してください。
CREATE NONCLUSTERED INDEX [Part_SalesOrderHeader_AccountNumber_AL] ON [Sales].[Part_SalesOrderHeader]([AccountNumber]);
Kimberly Trippのsp_helpindexを使用して、インデックスにどの列が存在するかを確認できます:
EXEC sp_SQLskills_SQL2008_helpindex 'Sales.Part_SalesOrderHeader’;

sp_helpindex for Sales.Part_SalesOrderHeader
クエリを実行して、整列されていないインデックスを使用するように強制すると、インデックス全体がスキャンされます。 OrderDateはインデックスの一部ですが、先頭の列ではないため、エンジンはすべてのAccountNumberのOrderDate値をチェックして、2013年1月1日から2013年7月31日までの間にあるかどうかを確認する必要があります。
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_NotAL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);統計IO出力
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Part_SalesOrderHeader'。スキャンカウント9、論理読み取り786861、物理読み取り1、先読み読み取り770929、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
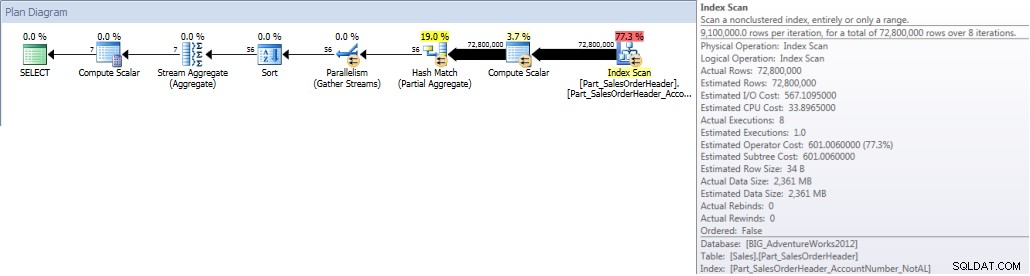
月別のアカウント合計(2013年1月から7月)調整されたNCI(強制)
対照的に、クエリで整列されたインデックスを使用するように強制されると、パーティションの削除を使用でき、OrderDateがインデックスの先頭の列でなくても、必要なI/Oが少なくなります。
SELECT DATEPART(MONTH,[OrderDate]),COUNT([AccountNumber]) FROM [Sales].[Part_SalesOrderHeader] WITH(INDEX([Part_SalesOrderHeader_AccountNumber_AL])) WHERE [OrderDate] BETWEEN '2013-01-01' AND '2013-07-31' GROUP BY DATEPART(MONTH,[OrderDate]) ORDER BY DATEPART(MONTH,[OrderDate]);統計IO出力
テーブル'Worktable'。スキャンカウント0、論理読み取り0、物理読み取り0、先読み読み取り0、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
テーブル'Part_SalesOrderHeader'。スキャンカウント9、論理読み取り456258、物理読み取り16、先読み読み取り453241、lob論理読み取り0、lob物理読み取り0、lob先読み読み取り0。
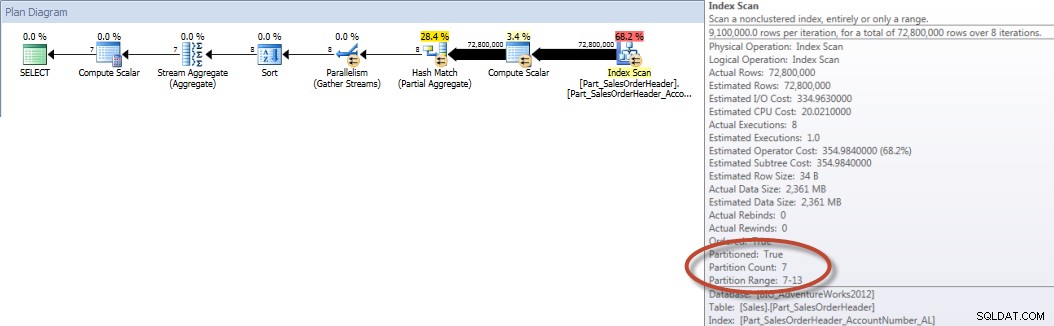
月別のアカウント合計(2013年1月から7月)整列されたNCIの使用(強制)
概要
パーティショニングを実装する決定は、十分な検討と計画が必要です。テーブルをパーティション化する一般的な理由は、管理のしやすさ、スケーラビリティと可用性の向上、およびブロッキングの削減です。クエリのパフォーマンスを向上させることは、パーティショニングを採用する理由ではありませんが、場合によっては有益な副作用になる可能性があります。パフォーマンスの観点から、実装計画にクエリパフォーマンスのレビューが含まれていることを確認することが重要です。インデックスが後のクエリを適切にサポートし続けることを確認します テーブルはパーティション化されており、クラスター化インデックスと非クラスター化インデックスを使用するクエリが、該当する場合はパーティションの削除の恩恵を受けることを確認します。