このシリーズの前回の投稿では、すべてのクエリシナリオがインメモリOLTPテクノロジの恩恵を受けるとは限らないことを示しました。実際、特定のユースケースでHekatonを使用すると、パフォーマンスに悪影響を与える可能性があります(クリックして拡大):

ただし、そのシナリオでは、2つの方法でデッキをHekatonに対してスタックした可能性があります。
- 作成したメモリ最適化テーブルタイプのバケット数は256でしたが、比較するために最大2,000個の値を渡していました。 SQL Serverチームからの最近のブログ投稿で、バケット数のサイズを大きくする方がサイズを小さくするよりも優れていると説明しました。これは一般的には知っていましたが、テーブル変数にも大きな影響があることに気づいていませんでした。ハッシュインデックスの場合、bucket_countは予想される一意のインデックスキーの数の約1〜2倍である必要があることに注意してください。通常、サイズを大きくする方がサイズを小さくするよりも優れています。変数に2つの値のみを挿入する場合もあれば、最大1000の値を挿入する場合もある場合は、通常、
BUCKET_COUNT=1000を指定することをお勧めします。 。彼らはこれの実際の理由を明確に議論しておらず、私たちが掘り下げることができる技術的な詳細はたくさんあると確信していますが、規範的なガイダンスは大きすぎるようです。
- 主キーは2つの列のハッシュインデックスでしたが、テーブル値パラメーターはこれらの列の1つの値とのみ一致しようとしていました。簡単に言うと、これはハッシュインデックスを使用できないことを意味します。 Tony Rogersonは、最近のブログ投稿でこれについてもう少し詳しく説明しています。ハッシュは、インデックスに含まれるすべての列にわたって生成されます。また、等価性チェック式でハッシュインデックスのすべての列を指定する必要があります。そうしないと、インデックスを使用できません。 。
以前は表示しませんでしたが、2列のハッシュインデックスを使用したメモリ最適化テーブルに対する計画では、非クラスター化ハッシュインデックスに対して期待されるインデックスシークではなく、実際にテーブルスキャンが実行されることに注意してください(列は
SalesOrderIDでした ):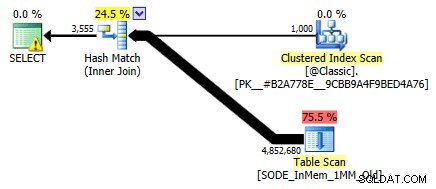
2列のメモリ内テーブルを含むクエリプランハッシュインデックス具体的には、ハッシュインデックスの先頭の列は、それ自体が豆の山を意味するものではありません。ハッシュは引き続きすべての列で一致するため、従来のBツリーインデックスのようには機能しません(従来のインデックスでは、先頭の列のみを含む述語は、行を削除するのに非常に役立ちます)。
何をしますか?
まず、SalesOrderIDのみにセカンダリハッシュインデックスを作成しました 桁。 100万個のバケットを持つそのようなテーブルの例:
CREATE TABLE [dbo].[SODE_InMem_1MM]
(
[SalesOrderID] [int] NOT NULL,
[SalesOrderDetailID] [int] NOT NULL,
[CarrierTrackingNumber] [nvarchar](25) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[OrderQty] [smallint] NOT NULL,
[ProductID] [int] NOT NULL,
[SpecialOfferID] [int] NOT NULL,
[UnitPrice] [money] NOT NULL,
[UnitPriceDiscount] [money] NOT NULL,
[LineTotal] [numeric](38, 6) NOT NULL,
[rowguid] [uniqueidentifier] NOT NULL,
[ModifiedDate] [datetime] NOT NULL
PRIMARY KEY NONCLUSTERED HASH
(
[SalesOrderID],
[SalesOrderDetailID]
) WITH (BUCKET_COUNT = 1048576),
/* I added this secondary non-clustered hash index: */
INDEX x NONCLUSTERED HASH
(
[SalesOrderID]
) WITH (BUCKET_COUNT = 1048576)
/* I used the same bucket count to minimize testing permutations */
) WITH (MEMORY_OPTIMIZED = ON, DURABILITY = SCHEMA_AND_DATA); テーブルタイプは次のように設定されていることに注意してください。
CREATE TYPE dbo.ClassicTVP AS TABLE ( Item INT PRIMARY KEY ); CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 256) ) WITH (MEMORY_OPTIMIZED = ON);
新しいテーブルにデータを入力し、新しいテーブルを参照するための新しいストアドプロシージャを作成すると、取得したプランには、単一列のハッシュインデックスに対するインデックスシークが正しく表示されます。

単一列のハッシュインデックスを使用した計画の改善
しかし、それはパフォーマンスにとって本当に何を意味するのでしょうか?同じ一連のテストを再度実行しました。バケット数が16K、131K、1MMのこのテーブルに対するクエリです。 100、1,000、および2,000の値を持つクラシックTVPとメモリ内TVPの両方を使用します。インメモリTVPの場合、従来のストアドプロシージャとネイティブにコンパイルされたストアドプロシージャの両方を使用します。組み合わせごとに10,000回の反復でパフォーマンスがどのように変化したかを次に示します。

単一列のハッシュインデックスに対する10,000回の反復のパフォーマンスプロファイル、 256バケットのTVPを使用する
パフォーマンスプロファイルはそれほど見栄えが良くないと思うかもしれません。それどころか、先月の前回のテストよりもはるかに優れています。これは、テーブルのバケット数が、ハッシュインデックスを効果的に使用するSQLServerの機能に大きな影響を与える可能性があることを示しています。この場合、16Kのバケット数を使用することは、これらのいずれの場合にも明らかに最適ではなく、TVPの値の数が増えるにつれて指数関数的に悪化します。
さて、TVPのバケット数は256だったことを思い出してください。Microsoftのガイダンスに従って、これを増やしたらどうなるでしょうか。より適切なバケットサイズで2番目のテーブルタイプを作成しました。 100、1,000、および2,000の値をテストしていたので、バケット数(2,048)に次の2の累乗を使用しました:
CREATE TYPE dbo.InMemoryTVP AS TABLE ( Item INT NOT NULL PRIMARY KEY NONCLUSTERED HASH WITH (BUCKET_COUNT = 2048) ) WITH (MEMORY_OPTIMIZED = ON);
このためのサポート手順を作成し、同じ一連のテストを再度実行しました。パフォーマンスプロファイルを並べて示します:

256バケットおよび2,048バケットのTVPとのパフォーマンスプロファイルの比較
サイズに関するMicrosoftの声明を考えると、テーブルタイプのバケット数の変更は、私が期待したような影響はありませんでした。それは実際にはあまり良い効果はありませんでした。実際、一部のシナリオでは、少し悪化しました。ただし、全体的なパフォーマンスプロファイルは、すべての目的と目的で同じです。
ただし、大きな効果があったのは、クエリパターンをサポートするための*正しい*ハッシュインデックスを作成することでした。以前のテストで別のことを示していたにもかかわらず、メモリ内のテーブルとメモリ内のTVPが、同じことを達成するための古い方法を打ち負かすことができることを実証できたことに感謝しました。前の例から最も極端なケースを取り上げましょう。テーブルに2列のハッシュインデックスしかない場合:

2列のハッシュインデックスに対する10回の反復のパフォーマンスプロファイル
右端のバーは、不適切なハッシュインデックスと照合するネイティブストアドプロシージャの10回の反復の期間を示しています。クエリ時間は、735〜1,601ミリ秒の範囲です。ただし、適切なハッシュインデックスが設定されているため、同じクエリが0.076ミリ秒から51.55ミリ秒までのはるかに狭い範囲で実行されています。最悪のケース(16Kバケットカウント)を除外すると、不一致はさらに顕著になります。すべての場合において、これは、同じメモリ最適化テーブルに対して、単純にコンパイルされたストアドプロシージャがない場合、どちらの方法よりも少なくとも2倍効率的です(少なくとも期間に関して)。また、2列のハッシュインデックスのみを使用する古いメモリ最適化テーブルに対するどのアプローチよりも数百倍優れています。
結論
あらゆるタイプのメモリ最適化テーブルを実装する場合は細心の注意を払う必要があり、多くの場合、メモリ最適化TVPを単独で使用しても最大のパフォーマンス向上が得られない可能性があることを示したことを願っています。ネイティブにコンパイルされたストアドプロシージャを使用してコストを最大限に活用することを検討する必要があります。また、最適なスケールでは、メモリ最適化テーブルのハッシュインデックスのバケット数に注意を払う必要があります(ただし、おそらくそうではありません)。メモリに最適化されたテーブルタイプに非常に注意してください。
インメモリOLTPテクノロジ全般の詳細については、次のリソースを確認してください。
- SQL Serverチームのブログ(タグ:Hekatonおよびタグ:インメモリOLTP –コードネームは面白くないですか?)
- ボブ・ボーシュマンのブログ
- KlausAschenbrennerのブログ