SQL Serverクエリ実行エンジンには、連結およびマージ結合連結の物理演算子を使用して、論理的な「すべての和集合」操作を実装する2つの方法があります。論理演算は同じですが、2つの物理演算子の間には重要な違いがあり、実行計画の効率に大きな違いをもたらす可能性があります。
クエリオプティマイザは、多くの場合、2つのオプションのどちらかを選択するという合理的な仕事をしますが、この分野で完璧とは程遠いものです。この記事では、Merge Join Concatenationによって提示されるクエリ調整の機会について説明し、それを最大限に活用するために知っておく必要のある内部動作と考慮事項について詳しく説明します。
連結

連結演算子は比較的単純です。その出力は、各入力から順番に完全に読み取った結果です。連結演算子はn-ary 物理演算子。つまり、「2…n」の入力を持つことができます。説明のために、前回の記事「パフォーマンスを向上させるためのクエリの書き換え」のAdventureWorksベースの例をもう一度見てみましょう。
SELECT * INTO dbo.TH FROM Production.TransactionHistory; CREATE UNIQUE CLUSTERED INDEX CUQ_TransactionID ON dbo.TH (TransactionID); CREATE NONCLUSTERED INDEX IX_ProductID ON dbo.TH (ProductID);
次のクエリは、6つの特定の製品の製品IDとトランザクションIDを一覧表示します。
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711;
SQL Sentry Plan Explorerに見られるように、6つの入力を持つ連結演算子を特徴とする実行プランを生成します。
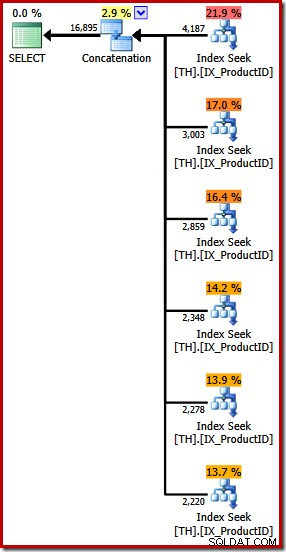
上記のプランは、クエリで指定されたのと同じ順序で(トップダウンで読み取る)、リストされた製品IDごとに個別のインデックスシークを備えています。一番上のインデックスシークは製品870用で、次のインデックスシークは製品873用、次に921などです。もちろん、そのいずれも動作が保証されているわけではありません。観察するのは興味深いことです。
連結演算子は、入力から順番に読み取ることによって出力を形成することを前述しました。このプランを実行すると、結果セットに最初に製品870、次に873、921、712、707、最後に製品711の行が表示される可能性が高くなります。ここでも、ORDERを指定しなかったため、これは保証されません。 BY句ですが、連結が内部でどのように機能するかを示しています。
SSIS「実行計画」
すぐに理解できる理由から、同じタスクを実行するためにSSISパッケージを設計する方法を検討してください。確かに、すべてをSSISで単一のT-SQLステートメントとして記述することもできますが、より興味深いオプションは、製品ごとに個別のデータソースを作成し、SQLServer連結の代わりにSSIS「UnionAll」コンポーネントを使用することです。演算子:
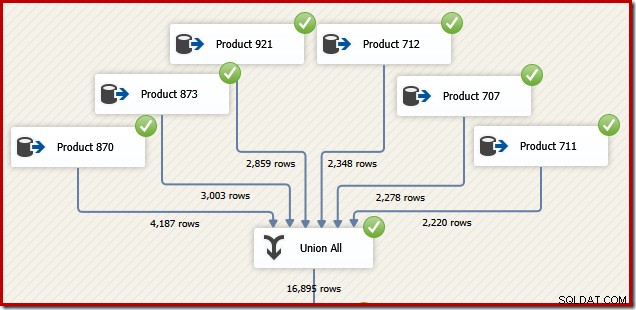
ここで、トランザクションIDの順序でそのデータフローからの最終出力が必要であると想像してください。 1つのオプションは、UnionAllの後に明示的なSortコンポーネントを追加することです。
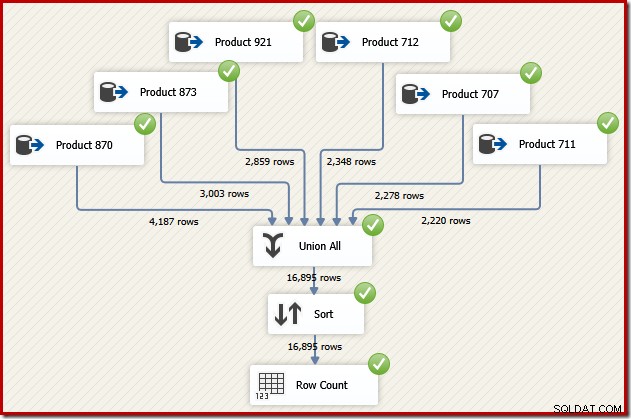
それは確かに仕事をしますが、熟練した経験豊富なSSIS設計者は、より良いオプションがあることに気付くでしょう:トランザクションIDの順序で各製品のソースデータを読み取り(インデックスを利用)、次に順序保存操作を使用してセットを結合します。
SSISでは、2つのソートされたデータフローからの行を1つのソートされたデータフローに結合するコンポーネントは、「マージ」と呼ばれます。マージを使用してトランザクションIDの順序で目的の行を返す再設計されたSSISデータフローは次のとおりです。
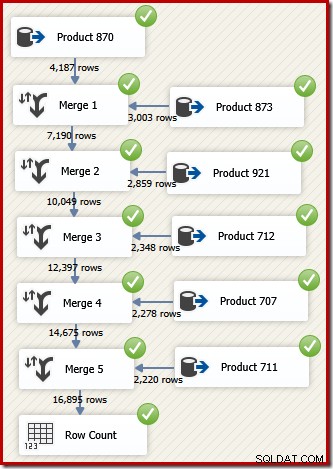
n-ary であったSSISの「UnionAll」コンポーネントとは異なり、Mergeはバイナリコンポーネントであるため、5つの個別のMergeコンポーネントが必要であることに注意してください。 。新しいマージフローは、高価な(そしてブロックする)ソートコンポーネントを必要とせずに、トランザクションIDの順序で結果を生成します。実際、最後のマージ後にトランザクションIDで並べ替えを追加しようとすると、SSISは警告を表示して、ストリームが既に目的の方法で並べ替えられていることを通知します。
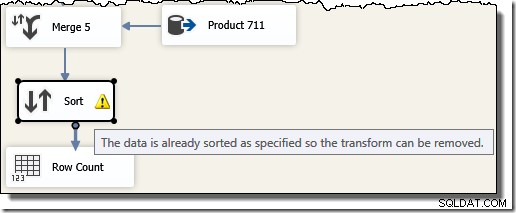
これで、SSISの例のポイントを明らかにすることができます。元のT-SQLクエリ結果をトランザクションIDの順序で返すように要求するときにSQLServerクエリオプティマイザーによって選択された実行プランを確認します(ORDER BY句を追加することにより):
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 870 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 873 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 921 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 712 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 707 UNION ALL SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID = 711 ORDER BY TransactionID;
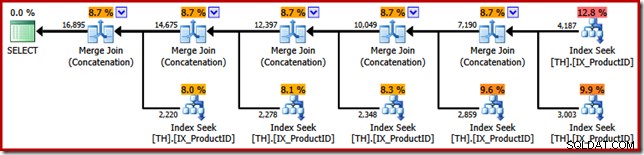
SSISマージパッケージとの類似点は目を見張るものがあります。 5つのバイナリ「マージ」演算子が必要になるまでです。重要な違いの1つは、SSISには「マージ結合」と「マージ」に別々のコンポーネントがあるのに対し、SQLServerは両方に同じコア演算子を使用することです。
明確にするために、SQL Server実行プランのマージ結合(連結)演算子はではありません 結合を実行します。エンジンは、同じ物理演算子を再利用して、順序を維持するすべてのユニオンを実装するだけです。
SQLServerでの実行プランの記述
SSISには、データフロー仕様言語も、そのような仕様を実行可能なデータフロータスクに変換するためのオプティマイザーもありません。順序を保持するマージが可能であることを認識し、コンポーネントのプロパティ(ソートキーなど)を適切に設定してから、パフォーマンスを比較するのは、SSISパッケージ設計者の責任です。これには、設計者側でより多くの労力(およびスキル)が必要ですが、非常に細かい制御が可能です。
SQLServerの状況は逆です。クエリを仕様で記述します。 T-SQL言語を使用してから、クエリオプティマイザに依存して実装オプションを調べ、効率的なオプションを選択します。実行計画を直接作成するオプションはありません。ほとんどの場合、これは非常に望ましいことです。すべてのクエリでSSISスタイルのパッケージを作成する必要がある場合、SQLServerの人気はかなり低くなるでしょう。
それでも(以前の投稿で説明したように)、オプティマイザーによって選択されたプランは、目的の結果を記述するために使用されるT-SQLに敏感である可能性があります。その記事の例を繰り返すと、別の構文を使用して元のT-SQLクエリを作成できます。
SELECT ProductID, TransactionID FROM dbo.TH WHERE ProductID IN (870, 873, 921, 712, 707, 711) ORDER BY TransactionID;
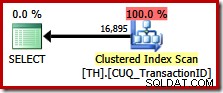
このクエリは以前とまったく同じ結果セットを指定しますが、オプティマイザーは順序を保持する(連結のマージ)プランを考慮せず、代わりにクラスター化インデックスをスキャンすることを選択します(はるかに効率の悪いオプション):
SQLServerでの順序保存の活用
SSISまたはSQLServerのどちらについて話している場合でも、不要な並べ替えを回避すると、効率が大幅に向上する可能性があります。 SQL Serverでは、実行プランをこれほどきめ細かく制御できないため、この目標を達成することはより複雑で困難になる可能性がありますが、まだできることがあります。
具体的には、SQL Serverのマージ結合連結演算子が内部でどのように機能するかを理解することで、クエリオプティマイザーが適切な場合に順序を保持する(マージする)処理オプションを検討するように促しながら、明確なリレーショナルT-SQLを記述し続けることができます。
マージ結合連結の仕組み

通常のマージ結合では、両方の入力を結合キーでソートする必要があります。一方、結合結合連結は、すでに順序付けされた2つのストリームを単一の順序付けられたストリームにマージするだけです。結合自体はありません。
これは疑問を投げかけます:保存される「順序」とは正確には何ですか?
SSISでは、順序を定義するために、マージ入力にソートキープロパティを設定する必要があります。 SQLServerにはこれに相当するものはありません。上記の質問に対する答えは少し複雑なので、段階的に説明します。
インデックス付けされていない2つのヒープテーブルのマージ連結を要求する次の例を考えてみます(最も単純なケース):
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (MERGE UNION);
これらの2つのテーブルにはインデックスがなく、ORDERBY句もありません。マージ結合連結「保持」はどのような順序になりますか?それについて考える時間を与えるために、まず、SQLServerのバージョンbeforeで上記のクエリに対して作成された実行プランを見てみましょう。 2012:
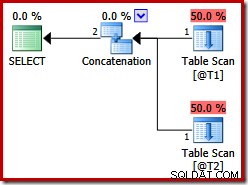
クエリのヒントにもかかわらず、マージ結合の連結はありません。SQLServer 2012より前では、このヒントはUNIONでのみ機能し、UNIONALLでは機能しません。目的のマージ演算子を使用してプランを取得するには、連結(CON)物理演算子を使用して論理UNION ALL(UNIA)の実装を無効にする必要があります。以下は文書化されておらず、本番環境での使用はサポートされていないことに注意してください。
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT * FROM @T1 AS T1 UNION ALL SELECT * FROM @T2 AS T2 OPTION (QUERYRULEOFF UNIAtoCON);
このクエリは、SQLServer2012および2014がMERGEUNIONクエリヒントのみを使用して行うのと同じプランを生成します。
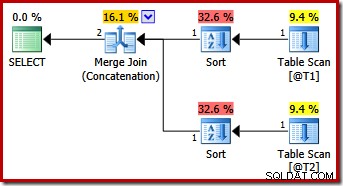
おそらく予期しないことに、実行プランは、マージへの両方の入力で明示的な並べ替えを特徴としています。並べ替えのプロパティは次のとおりです。
順序を保持するマージには一貫した入力順序が必要ですが、なぜ(c3、c1、c2)や(c2、c3、c1)ではなく(c1、c2、c3)を選択したのでしょうか。開始点として、マージ連結入力は出力プロジェクションリストでソートされます。クエリのselect-starは(c1、c2、c3)に展開されるため、選択された順序になります。
マージ出力プロジェクションリストによる並べ替え
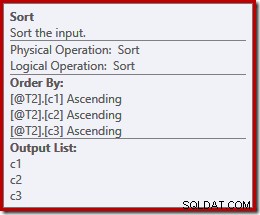
この点をさらに詳しく説明するために、(必要に応じて)select-starを拡張して、別の順序(c3、c2、c1)を選択することができます。
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
並べ替えが(c3、c2、c1)に一致するように変更されます:
繰り返しますが、クエリ output ORDER BY句がないため、order(テーブルにデータを追加すると仮定)は、示されているようにソートされることが保証されません。これらの例は、他に並べ替える理由がない場合に、オプティマイザーが最初の入力並べ替え順序を選択する方法を示すことを目的としています。
競合する並べ替え順序
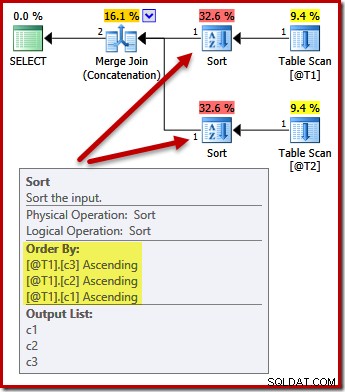
ここで、射影リストを(c3、c2、c1)のままにして、クエリ結果を(c1、c2、c3)で並べ替える要件を追加するとどうなるかを考えてみましょう。マージへの入力は引き続き(c3、c2、c1)でソートされ、マージ後のソートは(c1、c2、c3)でソートされ、ORDER BYを満たしますか?
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int); SELECT c3, c2, c1 FROM @T1 AS T1 UNION ALL SELECT c3, c2, c1 FROM @T2 AS T2 ORDER BY c1, c2, c3 OPTION (MERGE UNION);
いいえ。オプティマイザーは、2回の並べ替えを回避できるほど賢いです:
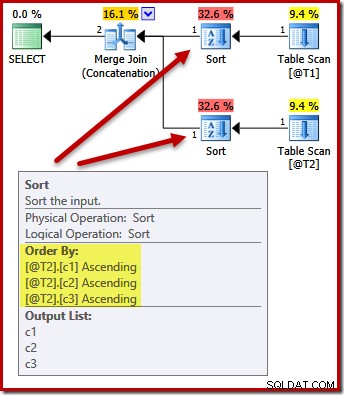
(c1、c2、c3)で両方の入力を並べ替えることは、マージ連結に完全に受け入れられるため、二重並べ替えは必要ありません。
この計画は行うことに注意してください 結果の順序が(c1、c2、c3)になることを保証します。プランはORDERBYのない以前のプランと同じように見えますが、すべての内部詳細がユーザーに表示される実行プランに表示されるわけではありません。
独自性の効果
マージ入力のソート順を選択する場合、オプティマイザーは、存在する一意性の保証の影響も受けます。次の例を考えてみましょう。5つの列がありますが、UNIONALL操作の列の順序が異なることに注意してください。
DECLARE @T1 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
実行計画には、テーブル@ T1の場合は(c5、c1、c2、c4、c3)、テーブル@ T2の場合は(c5、c4、c3、c2、c1)の並べ替えが含まれます。
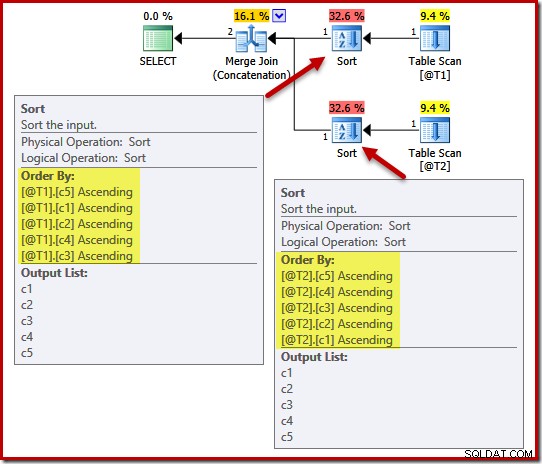
これらの並べ替えに対する一意性の効果を示すために、テーブルT1の列c1とテーブルT2の列c4にUNIQUE制約を追加します。
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION);
一意性についてのポイントは、オプティマイザーが、一意であることが保証されている列に遭遇するとすぐにソートを停止できることを知っているということです。一意のキーが検出された後に追加の列で並べ替えても、定義上、最終的な並べ替え順序には影響しません。
UNIQUE制約を設定すると、オプティマイザはT1の(c5、c1、c2、c4、c3)ソートリストを(c5、c1)に簡略化できます。これは、c1が一意であるためです。同様に、T2の(c5、c4、c3、c2、c1)ソートリストは、c4がキーであるため、(c5、c4)に簡略化されます。
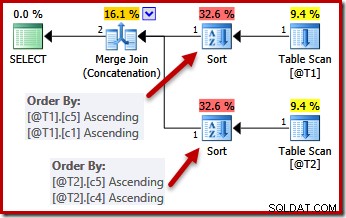
並列処理
一意キーによる単純化は完全には実装されていません。並列プランでは、ストリームはパーティション化されているため、マージの同じインスタンスのすべての行が同じスレッドになります。このデータセットのパーティション分割は、マージ列に基づいており、キーの存在によって単純化されていません。
次のスクリプトは、サポートされていないトレースフラグ8649を使用して、前のクエリの並列プランを生成します(それ以外の場合は変更されません)。
DECLARE @T1 AS TABLE (c1 int UNIQUE, c2 int, c3 int, c4 int, c5 int); DECLARE @T2 AS TABLE (c1 int, c2 int, c3 int, c4 int UNIQUE, c5 int); SELECT c5, c1, c2, c4, c3 FROM @T1 AS T1 UNION ALL SELECT c5, c4, c3, c2, c1 FROM @T2 AS T2 OPTION (MERGE UNION, QUERYTRACEON 8649);
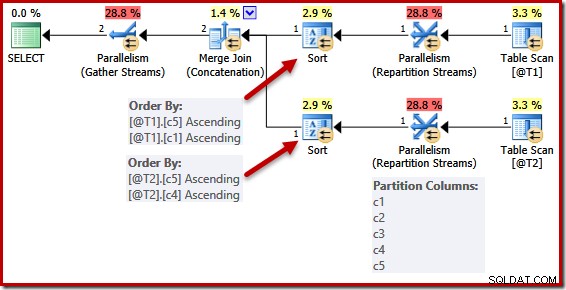
ソートリストは以前と同じように簡略化されていますが、RepartitionStreamsオペレーターは引き続きすべての列にパーティションを作成します。この簡略化が一貫して実装されている場合、再パーティション化演算子は(c5、c1)および(c5、c4)のみでも動作します。
一意でないインデックスの問題
次の例に示すように、オプティマイザがマージ連結の並べ替え要件について推論する方法により、不要な並べ替えの問題が発生する可能性があります。
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
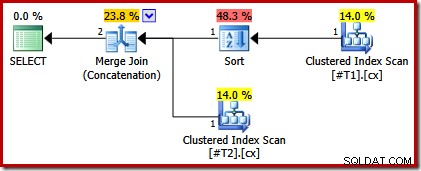
クエリと使用可能なインデックスを見ると、並べ替えの必要性を回避するためにマージ結合連結を使用して、クラスター化インデックスの順序付きスキャンを実行する実行プランが期待されます。クラスタ化インデックスはORDERBY句で指定された順序を提供するため、この期待は完全に正当化されます。残念ながら、実際に取得するプランには2つの種類が含まれています。
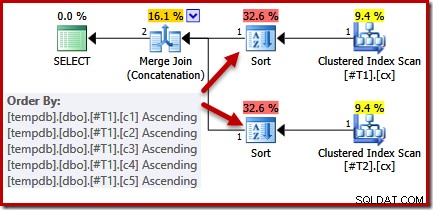
これらの種類の正当な理由はありません。クエリオプティマイザのロジックが不完全であるためにのみ表示されます。マージ出力列リスト(c1、c2、c3、c4、c5)はORDER BYのスーパーセットですが、一意のはありません。 そのリストを単純化するためのキー。オプティマイザーの推論におけるこのギャップの結果として、マージには入力を(c1、c2、c3、c4、c5)でソートする必要があると結論付けます。
スクリプトを変更して、クラスター化インデックスの1つを一意にすることで、この分析を検証できます。
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1 OPTION (MERGE UNION); DROP TABLE #T1, #T2;
実行プランには、一意でないインデックスを持つテーブルの上にのみ並べ替えがあります:
両方を作成すると クラスタ化インデックスは一意であり、並べ替えは表示されません:
CREATE TABLE #T1 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE TABLE #T2 (c1 int, c2 int, c3 int, c4 int, c5 int); CREATE UNIQUE CLUSTERED INDEX cx ON #T1 (c1); CREATE UNIQUE CLUSTERED INDEX cx ON #T2 (c1); SELECT * FROM #T1 AS T1 UNION ALL SELECT * FROM #T2 AS T2 ORDER BY c1; DROP TABLE #T1, #T2;
両方のインデックスが一意であるため、最初のマージ入力ソートリストを列c1のみに簡略化できます。簡略化されたリストはORDERBY句と完全に一致するため、最終的な計画では並べ替えは必要ありません。
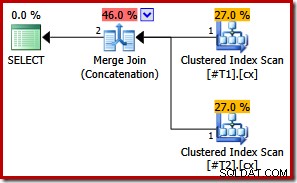
この最後の例では、最適な実行プランを取得するためにクエリヒントも必要ないことに注意してください。
最終的な考え
実行プランでソートを削除するのは難しい場合があります。場合によっては、既存のインデックスを変更する(または新しいインデックスを提供する)だけで、必要な順序で行を配信できます。適切なインデックスが利用可能な場合、クエリオプティマイザは全体的に妥当な仕事をします。
ただし、(多くの)他のケースでは、並べ替えを回避するには、実行エンジン、クエリオプティマイザー、およびプランオペレーター自体をより深く理解する必要があります。並べ替えを回避することは、間違いなく高度なクエリチューニングのトピックですが、すべてがうまくいったときに非常にやりがいのあるトピックでもあります。