注:この投稿は元々、eBook、SQLServerの高性能テクニック第3巻でのみ公開されていました。eBookについてはこちらをご覧ください。
私が時々目にする要件の1つは、顧客ごとにグループ化された注文でクエリを返し、これまでの注文の最大合計額(「実行中の最大値」)を表示することです。したがって、これらのサンプル行を想像してみてください:
| SalesOrderID | CustomerID | OrderDate | TotalDue |
|---|---|---|---|
| 12 | 2 | 2014-01-01 | 37.55 |
| 23 | 1 | 2014-01-02 | 45.29 |
| 31 | 2 | 2014-01-03 | 24.56 |
| 32 | 2 | 2014-01-04 | 89.84 |
| 37 | 1 | 2014-01-05 | 32.56 |
| 44 | 2 | 2014-01-06 | 45.54 |
| 55 | 1 | 2014-01-07 | 99.24 |
| 62 | 2 | 2014-01-08 | 12.55 |
数行のサンプルデータ
記載されている要件からの望ましい結果は次のとおりです。簡単に言えば、各顧客の注文を日付で並べ替え、各注文を一覧表示します。それがその日付までに表示されたすべての注文の最高のTotalDue値である場合は、その注文の合計を印刷します。それ以外の場合は、以前のすべての注文の最高のTotalDue値を印刷します。
| SalesOrderID | CustomerID | OrderDate | TotalDue | MaxTotalDue |
|---|---|---|---|---|
| 12 | 1 | 2014-01-02 | 45.29 | 45.29 |
| 23 | 1 | 2014-01-05 | 32.56 | 45.29 |
| 31 | 1 | 2014-01-07 | 99.24 | 99.24 |
| 32 | 2 | 2014-01-01 | 37.55 | 37.55 |
| 37 | 2 | 2014-01-03 | 24.56 | 37.55 |
| 44 | 2 | 2014-01-04 | 89.84 | 89.84 |
| 55 | 2 | 2014-01-06 | 45.54 | 89.84 |
| 62 | 2 | 2014-01-08 | 12.55 | 89.84 |
希望する結果のサンプル
多くの人は、これを達成するために本能的にカーソルまたはwhileループを使用したいと思うでしょうが、これらの構成を含まないいくつかのアプローチがあります。
相関サブクエリ
このアプローチは、問題に対する最も単純で最も簡単なアプローチのようですが、テーブルが大きくなるにつれて読み取りが指数関数的に増加するため、スケーリングしないことが何度も証明されています。
SELECT /* Correlated Subquery */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = (SELECT MAX(TotalDue)
FROM Sales.SalesOrderHeader
WHERE CustomerID = h.CustomerID
AND SalesOrderID <= h.SalesOrderID)
FROM Sales.SalesOrderHeader AS h
ORDER BY CustomerID, SalesOrderID; SQL SentryPlanExplorerを使用したAdventureWorks2014に対する計画は次のとおりです。
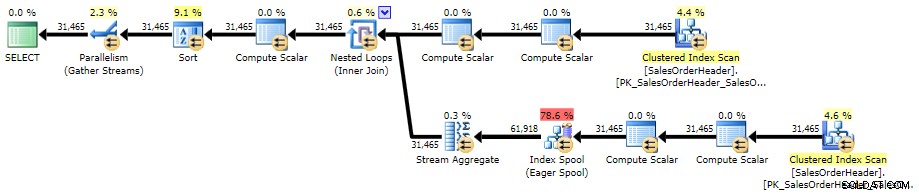 相関サブクエリの実行プラン(クリックして拡大)
相関サブクエリの実行プラン(クリックして拡大)
自己参照CROSSAPPLY
このアプローチは、構文、計画の形、および大規模なパフォーマンスの点で、相関サブクエリアプローチとほぼ同じです。
SELECT /* CROSS APPLY */ h.SalesOrderID, h.CustomerID, h.OrderDate, h.TotalDue, x.MaxTotalDue
FROM Sales.SalesOrderHeader AS h
CROSS APPLY
(
SELECT MaxTotalDue = MAX(TotalDue)
FROM Sales.SalesOrderHeader AS i
WHERE i.CustomerID = h.CustomerID
AND i.SalesOrderID <= h.SalesOrderID
) AS x
ORDER BY h.CustomerID, h.SalesOrderID; このプランは、相関サブクエリプランと非常によく似ていますが、唯一の違いは、並べ替えの場所です。
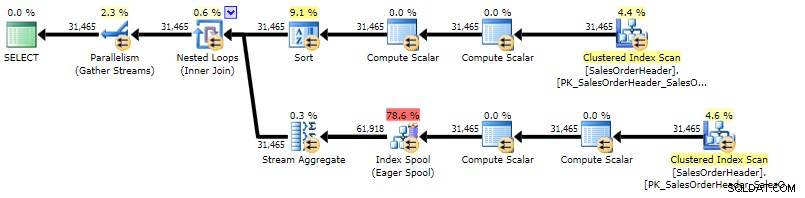 CROSS APPLYの実行プラン(クリックして拡大)
CROSS APPLYの実行プラン(クリックして拡大)
再帰CTE
舞台裏では、これはループを使用しますが、実際に実行するまでは、ループを実行しないふりをすることができます(ただし、この特定の問題を解決するために作成したいコードの中で最も複雑な部分です):
;WITH /* Recursive CTE */ cte AS
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue = TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader
) AS x
WHERE rn = 1
UNION ALL
SELECT r.SalesOrderID, r.CustomerID, r.OrderDate, r.TotalDue,
MaxTotalDue = CASE
WHEN r.TotalDue > cte.MaxTotalDue THEN r.TotalDue
ELSE cte.MaxTotalDue
END
FROM cte
CROSS APPLY
(
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue,
rn = ROW_NUMBER() OVER (PARTITION BY CustomerID ORDER BY SalesOrderID)
FROM Sales.SalesOrderHeader AS h
WHERE h.CustomerID = cte.CustomerID
AND h.SalesOrderID > cte.SalesOrderID
) AS r
WHERE r.rn = 1
)
SELECT SalesOrderID, CustomerID, OrderDate, TotalDue, MaxTotalDue
FROM cte
ORDER BY CustomerID, SalesOrderID
OPTION (MAXRECURSION 0); 計画が前の2つよりも複雑であることがすぐにわかります。これは、より複雑なクエリを考えると驚くことではありません。
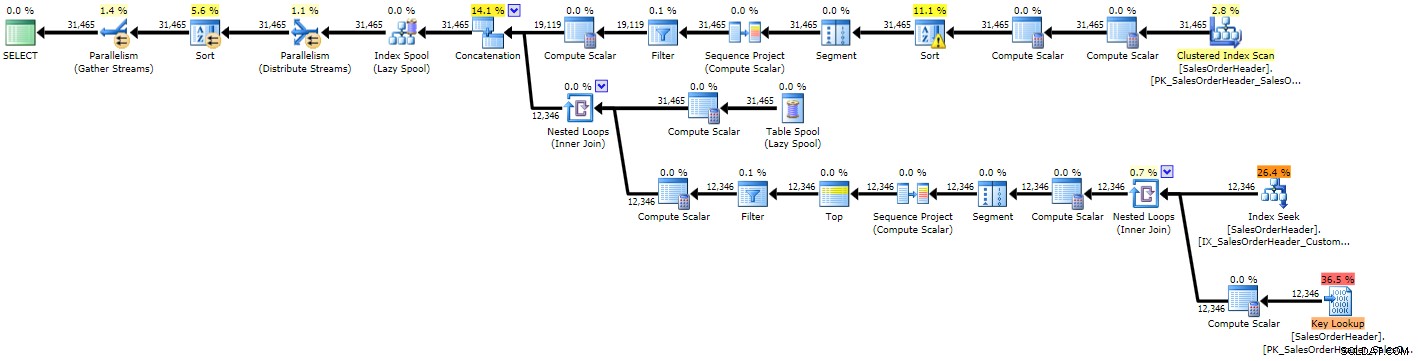 再帰CTEの実行プラン(クリックして拡大)
再帰CTEの実行プラン(クリックして拡大)
いくつかの悪い見積もりのために、おそらく両方を単一のスキャンで置き換える必要があるキールックアップを伴うインデックスシークが表示され、最終的にtempdbにスピルする必要があるソート操作も取得されます(これはツールチップで確認できます)警告アイコンが付いた並べ替え演算子にカーソルを合わせると):

MAX()OVER(ROWS UNBOUNDED)
これは、ウィンドウ関数に新しく導入された拡張機能を使用するため、SQLServer2012以降でのみ使用可能なソリューションです。
SELECT /* MAX() OVER() */ SalesOrderID, CustomerID, OrderDate, TotalDue,
MaxTotalDue = MAX(TotalDue) OVER
(
PARTITION BY CustomerID ORDER BY SalesOrderID
ROWS UNBOUNDED PRECEDING
)
FROM Sales.SalesOrderHeader
ORDER BY CustomerID, SalesOrderID; この計画は、他のすべての計画よりも拡張性が高い理由を正確に示しています。 2つ(または再帰CTEの場合はスキャンとシーク+ルックアップの不適切な選択)ではなく、1つのクラスター化インデックススキャン操作しかありません:
 MAX()OVER()の実行プラン(クリックして拡大)>
MAX()OVER()の実行プラン(クリックして拡大)>
パフォーマンスの比較
計画は確かに私たちに新しいMAX() OVER() SQL Server 2012の機能は真の勝者ですが、具体的なランタイムメトリックについてはどうでしょうか。実行の比較は次のとおりです。

最初の2つのクエリはほとんど同じでした。この場合、CROSS APPLY 全体的な継続時間の点でわずかな差で優れていましたが、相関サブクエリは、代わりに少しだけそれを打ち負かすことがあります。再帰CTEは毎回大幅に遅くなり、それに寄与する要因、つまり、不正な見積もり、大量の読み取り、キールックアップ、および追加の並べ替え操作を確認できます。また、前に累計で示したように、SQLServer2012ソリューションはほぼすべての面で優れています。
結論
SQL Server 2012以降を使用している場合は、SQL Server 2005で最初に導入されたウィンドウ関数のすべての拡張機能に精通する必要があります。これらの拡張機能を使用すると、まだ実行中のコードを再検討するときに、パフォーマンスが大幅に向上する可能性があります。古い方法です。」これらの新機能のいくつかについて詳しく知りたい場合は、Itzik Ben-Ganの著書、ウィンドウ関数を使用したMicrosoft SQLServer2012高性能T-SQLを強くお勧めします。
SQL Server 2012をまだ使用していない場合は、少なくともこのテストでは、CROSS APPLYから選択できます。 および相関サブクエリ。いつものように、ハードウェア上のデータに対してさまざまな方法をテストする必要があります。