この記事では、単純なクエリを使用して、更新クエリに関するいくつかの詳細な内部を調べます。
サンプルデータと構成
以下のサンプルデータ作成スクリプトには、数値の表が必要です。これらのいずれかをまだお持ちでない場合は、以下のスクリプトを使用して効率的に作成できます。結果の数値テーブルには、100万から100万までの数値を含む単一の整数列が含まれます。
WITH Ten(N) AS
(
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL
SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1 UNION ALL SELECT 1
)
SELECT TOP (1000000)
n = IDENTITY(int, 1, 1)
INTO dbo.Numbers
FROM Ten T10,
Ten T100,
Ten T1000,
Ten T10000,
Ten T100000,
Ten T1000000;
ALTER TABLE dbo.Numbers
ADD CONSTRAINT PK_dbo_Numbers_n
PRIMARY KEY CLUSTERED (n)
WITH (SORT_IN_TEMPDB = ON, MAXDOP = 1, FILLFACTOR = 100); 以下のスクリプトは、IDごとに約100の異なる開始日を持つ、10,000のIDを持つクラスター化されたサンプルデータテーブルを作成します。終了日列は、最初は固定値「99991231」に設定されています。
CREATE TABLE dbo.Example
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
EndDate date NOT NULL
);
GO
INSERT dbo.Example WITH (TABLOCKX)
(SomeID, StartDate, EndDate)
SELECT DISTINCT
1 + (N.n % 10000),
DATEADD(DAY, 50000 * RAND(CHECKSUM(NEWID())), '20010101'),
CONVERT(date, '99991231', 112)
FROM dbo.Numbers AS N
WHERE
N.n >= 1
AND N.n <= 1000000
OPTION (MAXDOP 1);
CREATE CLUSTERED INDEX
CX_Example_SomeID_StartDate
ON dbo.Example
(SomeID, StartDate)
WITH (MAXDOP = 1, SORT_IN_TEMPDB = ON); この記事で指摘した点は、SQL Serverの現在のすべてのバージョンにほぼ一般的に当てはまりますが、以下の構成情報を使用して、同様の実行プランとパフォーマンスへの影響を確認できます。
- SQL Server 2012 Service Pack 3 x64 Developer Edition
- 最大サーバーメモリを2048MBに設定
- インスタンスで使用可能な4つの論理プロセッサ
- トレースフラグが有効になっていません
- デフォルトの読み取りコミット分離レベル
- RCSIおよびSIデータベースオプションが無効になっています
骨材流出のハッシュ
実際の実行計画を有効にして上記のデータ作成スクリプトを実行すると、ハッシュ集計がtempdbに流出し、警告アイコンが生成される場合があります。

SQL Server 2012 Service Pack 3で実行すると、流出に関する追加情報がツールチップに表示されます。
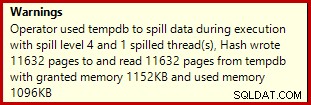
ハッシュ一致の入力行の推定値が正確に正しいことを考えると、この流出は驚くべきことかもしれません:
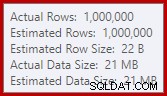
入力の推定値を比較することに慣れています ソートとハッシュ結合(ビルド入力のみ)の場合ですが、熱心なハッシュ集計は異なります。ハッシュ集計は、グループ化された結果行をハッシュテーブルに累積することで機能するため、出力の数になります。 重要な行:
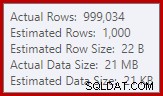
SQL Server 2012のカーディナリティ推定器は、予想される個別の値の数を推測しません(1,000対実際の999,034)。結果として、ハッシュアグリゲートは実行時にレベル4に再帰的にスピルします。 SQL Server 2014以降で利用可能な「新しい」カーディナリティ推定器は、このクエリのハッシュ出力のより正確な推定値を生成するため、その場合はハッシュスピルは表示されません。

スクリプトで疑似乱数ジェネレーターを使用している場合、実際の行の数はわずかに異なる場合があります。重要な点は、ハッシュ集計の流出は、入力サイズではなく、出力される一意の値の数に依存するということです。
更新仕様
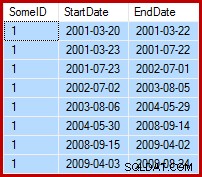
手元のタスクは、終了日が次の開始日の前日に設定されるようにサンプルデータを更新することです(SomeIDごと)。たとえば、サンプルデータの最初の数行は、更新前は次のようになります(すべての終了日は9999-12-31に設定されています):

更新後は次のようになります:
1。ベースライン更新クエリ
T-SQLで必要な更新を表現するための合理的に自然な方法の1つは、次のとおりです。
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate =
ISNULL
(
(
SELECT TOP (1)
DATEADD(DAY, -1, E2.StartDate)
FROM dbo.Example AS E2 WITH (TABLOCK)
WHERE
E2.SomeID = dbo.Example.SomeID
AND E2.StartDate > dbo.Example.StartDate
ORDER BY
E2.StartDate ASC
),
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); 実行後(実際の)実行計画は次のとおりです。
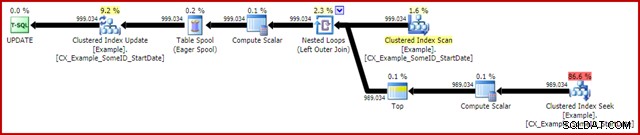
最も注目すべき機能は、HalloweenProtectionを提供するためのEagerTableSpoolの使用です。これは、更新対象テーブルの自己結合のため、ここで正しく動作するために必要です。その結果、スプールの右側のすべてが完了するまで実行され、変更を加えるために必要なすべての情報がtempdb作業テーブルに格納されます。読み取り操作が完了すると、作業テーブルの内容が再生され、クラスター化インデックス更新イテレーターで変更が適用されます。
パフォーマンス
この実行プランの潜在的な最大パフォーマンスに焦点を合わせるために、同じ更新クエリを複数回実行できます。明らかに、最初の実行のみでデータが変更されますが、これは小さな考慮事項であることがわかります。これが気になる場合は、次のコードを使用して、各実行の前に終了日の列をリセットしてください。私が行う大まかなポイントは、実際に行われたデータ変更の数に依存しません。
UPDATE dbo.Example WITH (TABLOCKX) SET EndDate = CONVERT(date, '99991231', 112);
実行計画の収集が無効になり、バッファプールに必要なすべてのページがあり、実行間で終了日の値がリセットされない場合、このクエリは通常、約5700ミリ秒で実行されます。 私のラップトップで。統計IO出力は次のとおりです:(先読み読み取りとLOBカウンターはゼロであり、スペース上の理由で省略されています)
Table 'Example'. Scan count 999035, logical reads 6186219, physical reads 0 Table 'Worktable'. Scan count 1, logical reads 2895875, physical reads 0
スキャンカウントは、スキャン操作が開始された回数を表します。例の表の場合、これはクラスター化インデックススキャンの場合は1であり、相関クラスター化インデックスシークがリバウンドされるたびに999,034です。 Eager Spoolが使用する作業テーブルでは、スキャン操作が1回だけ開始されます。
論理読み取り
IO出力でさらに興味深い情報は、論理読み取りの数です:600万 例の表の場合、ほぼ300万 作業台用。
サンプルテーブルの論理読み取りは、主にSeekとUpdateに関連付けられています。シークでは、反復ごとに3つの論理読み取りが発生します。インデックスのルート、中間、およびリーフレベルにそれぞれ1つです。同様に、更新には行ごとに3回の読み取りが必要です。 エンジンがbツリーを下に移動してターゲット行を見つけると、が更新されます。 Clustered Index Scanは、ページごとに1回、数千回の読み取りのみを処理します。 読む。
スプール作業テーブルも内部的にbツリーとして構造化されており、スプールが入力を消費しながら挿入位置を特定するときに、複数の読み取りをカウントします。おそらく直感に反して、スプールは、クラスター化インデックス更新を駆動するために読み取られている間、論理読み取りをカウントしません。これは単に実装の結果です。コードがBPool::Get を実行するたびに、論理読み取りがカウントされます。 方法。スプールに書き込むと、インデックスの各レベルでこのメソッドが呼び出されます。スプールからの読み取りは、 BPool ::Getを呼び出さない別のコードパスに従います。 まったく。
統計IO出力は、実行プラン内の3つの異なるイテレーター(スキャン、シーク、および更新)によってアクセスされているにもかかわらず、サンプルテーブルの単一の合計を報告することにも注意してください。この後者の事実により、論理読み取りをそれらを引き起こしたイテレータに関連付けることが困難になります。この制限が製品の将来のバージョンで解決されることを願っています。
2。行番号を使用して更新
更新クエリを表現する別の方法には、IDごとに行に番号を付けて結合することが含まれます。
WITH Numbered AS
(
SELECT
E.SomeID,
E.StartDate,
E.EndDate,
rn = ROW_NUMBER() OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate ASC)
FROM dbo.Example AS E
)
UPDATE This WITH (TABLOCKX)
SET EndDate =
ISNULL
(
DATEADD(DAY, -1, NextRow.StartDate),
CONVERT(date, '99991231', 112)
)
FROM Numbered AS This
LEFT JOIN Numbered AS NextRow WITH (TABLOCK)
ON NextRow.SomeID = This.SomeID
AND NextRow.rn = This.rn + 1
OPTION (MAXDOP 1, MERGE JOIN); 実行後の計画は次のとおりです。
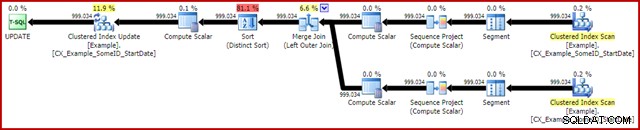
このクエリは通常、2950ミリ秒で実行されます 私のラップトップでは、元の更新ステートメントで見られた5700ms(同じ状況で)と比べて遜色ありません。統計IO出力は次のとおりです。
Table 'Example'. Scan count 2, logical reads 3001808, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
これは、Exampleテーブルに対して開始された2つのスキャンを示しています(クラスター化インデックススキャンイテレーターごとに1つ)。論理読み取りも、クエリプランでこのテーブルにアクセスするすべてのイテレータの集計です。以前と同様に、内訳がないため、(2つのスキャンと更新の)どのイテレータが300万回の読み取りの原因であるかを特定できません。
それでも、クラスター化インデックススキャンはそれぞれ数千の論理読み取りしかカウントしないと言えます。論理読み取りの大部分は、クラスター化インデックスの更新がインデックスbツリーをナビゲートして、処理する各行の更新位置を見つけることによって発生します。今のところ、私の言葉を信じる必要があります。詳細については、まもなく説明します。
欠点
これで、この形式のクエリの朗報はほぼ終わりです。オリジナルよりもはるかに優れたパフォーマンスを発揮しますが、他の多くの理由から満足のいくものではありません。主な問題はオプティマイザの制限が原因です。つまり、行番号付け操作によって、SomeIDパーティション内の各行に一意の番号が生成されることを認識しません。
この単純な事実は、多くの望ましくない結果につながります。 1つには、マージ結合は多対多結合モードで実行するように構成されています。これが、統計IOの(未使用の)作業テーブルの理由です(多対多のマージには、重複した結合キーの巻き戻しのための作業テーブルが必要です)。多対多の結合を期待することは、結合出力のカーディナリティ推定が絶望的に間違っていることも意味します:
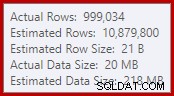
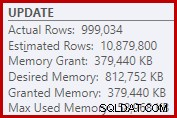
その結果として、Sortは非常に多くのメモリ許可を要求します。ルートノードのプロパティは、Sortが812,752 KBのメモリを必要としていたことを示していますが、サーバーの最大メモリ設定が制限されているため(2048 MB)、379,440KBしか許可されていませんでした。ソートでは、実行時に最大58,968 KBが実際に使用されました:
過剰なメモリは、他の生産的な使用からメモリを盗むことを許可し、メモリが利用可能になるまで待機するクエリにつながる可能性があります。多くの点で、過剰なメモリの付与は、過小評価するよりも問題になる可能性があります。
オプティマイザの制限は、最高のパフォーマンスを得るためにクエリでマージ結合ヒントが必要だった理由も説明しています。このヒントがないと、オプティマイザは、ハッシュ結合が多対多のマージ結合よりも安価であると誤って評価します。ハッシュ結合プランは平均3350ミリ秒で実行されます。
最後のマイナスの結果として、プランの並べ替えが個別の並べ替えであることに注意してください。現在、その並べ替えにはいくつかの理由があります(特に、必要なハロウィーン保護を提供できるため)が、それは個別にすぎません。 オプティマイザーが一意性情報を見逃しているため、ソートします。全体として、パフォーマンス以外にこの実行計画について多くを好むことは困難です。
3。 LEAD分析関数を使用して更新する
この記事は主にSQLServer2012以降を対象としているため、LEAD分析関数を使用して更新クエリを非常に自然に表現できます。理想的な世界では、次のような非常にコンパクトな構文を使用できます。
-- Not allowed
UPDATE dbo.Example WITH (TABLOCKX)
SET EndDate = LEAD(StartDate) OVER (
PARTITION BY SomeID ORDER BY StartDate); 残念ながら、これは合法ではありません。その結果、エラーメッセージ4108「ウィンドウ関数はSELECT句またはORDERBY句にのみ表示されます」が表示されます。自己参加(および関連する更新Halloween Protection)を回避できる実行プランを期待していたため、これは少しイライラします。
良いニュースは、共通テーブル式または派生テーブルを使用して自己結合を回避できることです。構文はもう少し冗長ですが、考え方はほとんど同じです:
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1); 実行後の計画は次のとおりです。

これは通常、約 3400msで実行されます 私のラップトップでは、行番号ソリューション(2950ms)よりも低速ですが、元のソリューション(5700ms)よりもはるかに高速です。実行計画から際立っていることの1つは、ソートスピルです(ここでも、SP3の改善による追加のスピル情報):
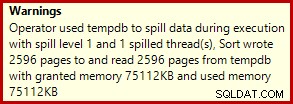
これはごくわずかな流出ですが、それでもある程度パフォーマンスに影響を与える可能性があります。それについての奇妙なことは、ソートへの入力推定が正確に正しいことです:
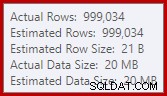
幸い、SQL Server 2012 SP2 CU8(およびその他のリリース–詳細についてはKBの記事を参照)には、この特定の状態に対する「修正」があります。修正と必要なトレースフラグ7470を有効にしてクエリを実行すると、ソートは、推定入力ソートサイズを超えない場合にディスクにスピルしないように、ソートが十分なメモリを要求することを意味します。
ソートスピルなしのLEAD更新クエリ
多様性のために、以下の修正対応クエリは、CTEの代わりに派生テーブル構文を使用します:
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate, CONVERT(date, '99991231', 112)
)
FROM
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
) AS CED
OPTION (MAXDOP 1, QUERYTRACEON 7470); 新しい実行後の計画は次のとおりです。

少量のこぼれをなくすと、パフォーマンスが3400ミリ秒から3250ミリ秒に向上します。 。統計IO出力は次のとおりです。
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
これを行番号付きクエリの論理読み取りと比較すると、論理読み取りが3,001,808から2,999,455に減少していることがわかります。これは2,353回の読み取りの違いです。これは、1回のクラスター化インデックススキャン(ページごとに1回の読み取り)の削除に正確に対応します。
これらの更新クエリの論理読み取りの大部分はクラスター化インデックスの更新に関連付けられており、スキャンは「わずか数千回の読み取り」に関連付けられていることを覚えているかもしれません。これで、Exampleテーブルに対して単純な行カウントクエリを実行することで、これをもう少し直接確認できます。
SET STATISTICS IO ON; SELECT COUNT(*) FROM dbo.Example WITH (TABLOCK); SET STATISTICS IO OFF;
IO出力は、行番号とリード更新の間の2,353の論理読み取りの違いを正確に示しています。
Table 'Example'. Scan count 1, logical reads 2353, physical reads 0
さらなる改善?
こぼれを修正したリードクエリ(3250ms)は、2行番号のクエリ(2950ms)よりもかなり遅いですが、これは少し意外かもしれません。直感的には、1回のスキャンと分析関数(ウィンドウスプールとストリーム集約)は、2回のスキャン、2セットの行番号付け、および結合よりも高速であると予想される場合があります。
とにかく、リードクエリ実行プランから飛び出すのはSortです。また、行番号付きクエリにも存在し、Halloween Protectionと、Clustered Index Update(DMLRequestSortプロパティが設定されている)の最適化された並べ替え順序に貢献しました。
重要なのは、このソートはリードクエリプランでは完全に不要です。自己参加がなくなったため、ハロウィーン保護には必要ありません。最適化された挿入ソート順にも必要ありません。行はクラスター化キーの順序で読み取られており、その順序を妨げるものは計画にありません。実際の問題は、Sortプロパティを確認することで確認できます:

そこにある[注文者]セクションに注目してください。並べ替えは、SomeIDとStartDate(クラスター化されたインデックスキー)だけでなく、一意化子である[Uniq1002]によっても並べ替えられます。これは、SomeIDとStartDateの組み合わせが実際に一意になるようにデータ母集団クエリで手順を実行したにもかかわらず、クラスター化インデックスを一意として宣言しなかった結果です。 (これは意図的なものだったので、これについて話すことができました。)
それでも、これは制限です。行はクラスター化インデックスから順番に読み取られ、オプティマイザーがこのソートを安全に回避できるように、必要な内部保証が存在します。オプティマイザが、着信ストリームがSomeIDとStartDateだけでなく、一意化子によってソートされていることを認識しないのは、単に見落としです。 (SomeID、StartDate)の順序は保持できますが、(SomeID、StartDate、uniquifier)は保持できないことを認識します。繰り返しになりますが、これは将来のバージョンで対処されることを願っています。
これを回避するには、最初にすべきことを実行できます。つまり、クラスター化されたインデックスを一意として構築します。
CREATE UNIQUE CLUSTERED INDEX CX_Example_SomeID_StartDate ON dbo.Example (SomeID, StartDate) WITH (DROP_EXISTING = ON, MAXDOP = 1);
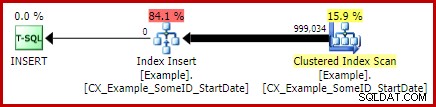
最初の2つの(LEAD以外の)クエリがこのインデックスの変更の恩恵を受けないことを読者が示すための演習として残しておきます(スペース上の理由で省略されています。カバーすることがたくさんあります)。
リード更新クエリの最終形式
ユニーク クラスタ化インデックスが適切に配置されている場合、まったく同じLEADクエリ(CTEまたは派生テーブル)により、予想される(実行前の)推定プランが生成されます。

これはかなり最適のようです。最小の演算子を間に挟んだ単一の読み取りおよび書き込み操作。確かに、回避可能な流出が削除されると3250ミリ秒で実行された不要なソートを備えた以前のバージョンよりもはるかに優れているようです(メモリ付与を少し増やすという犠牲を払って)。
実行後(実際の)計画は、実行前の計画とほぼ同じです。

ウィンドウスプールの出力が2行ずれていることを除いて、すべての見積もりは正確に正しいです。統計IO情報は、予想どおり、並べ替えが削除される前とまったく同じです。
Table 'Example'. Scan count 1, logical reads 2999455, physical reads 0 Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0
簡単にまとめると、この新しい計画と直前の計画との唯一の明らかな違いは、Sort(推定コスト貢献度が約80%)が削除されたことです。
その場合、並べ替えなしの新しいクエリが5000ミリ秒で実行されることを知って驚くかもしれません。 。これは、Sortを使用した3250msよりもはるかに悪く、5700msの元のループ結合クエリとほぼ同じ長さです。 2行の番号付けソリューションは、2950ミリ秒でまだはるかに進んでいます。
説明
説明はやや難解であり、最新のクエリでラッチが処理される方法に関連しています。この効果はいくつかの方法で示すことができますが、最も簡単なのは、DMVを使用して待機とラッチの統計を確認することです。
DBCC SQLPERF('sys.dm_os_wait_stats', CLEAR);
DBCC SQLPERF('sys.dm_os_latch_stats', CLEAR);
WITH CED AS
(
SELECT
E.EndDate,
CalculatedEndDate =
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E
)
UPDATE CED WITH (TABLOCKX)
SET CED.EndDate =
ISNULL
(
CED.CalculatedEndDate,
CONVERT(date, '99991231', 112)
)
OPTION (MAXDOP 1);
SELECT * FROM sys.dm_os_latch_stats AS DOLS
WHERE DOLS.waiting_requests_count > 0
ORDER BY DOLS.latch_class;
SELECT * FROM sys.dm_os_wait_stats AS DOWS
WHERE DOWS.waiting_tasks_count > 0
ORDER BY DOWS.waiting_tasks_count DESC; クラスタ化されたインデックスが一意でなく、プランに並べ替えがある場合、重要な待機はなく、PAGEIOLATCH_UPの待機が2、3回と予想されるSOS_SCHEDULER_YIELDがあります。
クラスタ化されたインデックスが一意であり、並べ替えが削除された場合、待機は次のようになります。
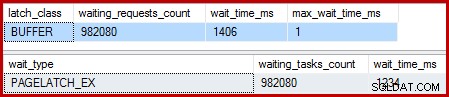
そこには982,080の専用ページラッチがあり、待機時間は余分な実行時間のほとんどすべてを説明しています。強調すると、これは更新された行ごとにほぼ1つのラッチ待機です。行ごとのラッチの変更が予想される場合がありますが、ラッチは待機ではありません。 特に、テストクエリがインスタンス上の唯一のアクティビティである場合。ラッチの待機時間は短いですが、非常に多くあります。
レイジーラッチ
デバッガーとアナライザーを接続してクエリを実行した後の説明は次のとおりです。
ClusteredIndexScanはレイジーラッチを使用します –別のスレッドがページへのアクセスを必要とする場合にのみラッチが解放されることを意味する最適化。通常、ラッチは読み取りまたは書き込みの直後に解放されます。レイジーラッチは、ページ全体をスキャンすると、すべての行で同じページラッチを取得して解放する場合を最適化します。レイジーラッチを競合なしで使用すると、ページ全体で1つのラッチのみが使用されます。
問題は、実行プランのパイプライン化された性質(ブロッキング演算子がない)が、読み取りと書き込みのオーバーラップを意味することです。 Clustered Index Updateが行を変更するためにEXラッチを取得しようとすると、ほとんどの場合、ページがすでにラッチされているSH(Clustered Index Scanによって取得されたレイジーラッチ)が検出されます。この状況では、ラッチ待機が発生します。
待機の準備とスケジューラーの次の実行可能アイテムへの切り替えの一環として、コードはレイジーラッチを解放するように注意しています。怠惰なラッチを解放すると、最初の適格なウェイターに信号が送られます。そのため、スレッドがそれ自体をブロックし、レイジーラッチを解放してから、スレッドが再び実行可能であることを通知するという奇妙な状況が発生します。スレッドは再びピックアップして続行しますが、サスペンドと切り替え、シグナリング、および再開の作業がすべて無駄になった後でのみです。前にも言ったように、待ち時間は短いですが、たくさんあります。
私が知っている限りでは、この奇妙な一連のイベントは、設計によるものであり、内部的な理由によるものです。それでも、ここでのパフォーマンスにかなり劇的な影響を与えるという事実から逃れることはできません。これについていくつか質問し、公の声明があれば記事を更新します。それまでの間、過剰なセルフラッチ待機は、パイプライン更新クエリで注意する必要があるかもしれませんが、クエリ作成者の観点からは何をすべきかは明確ではありません。
これは、二重行番号付けアプローチがこのクエリに対して実行できる最善の方法であることを意味しますか?完全ではありません。
4。手動ハロウィーン保護
この最後のオプションは、聞こえて少しおかしなことに見えるかもしれません。大まかな考え方は、テーブル変数に変更を加えるために必要なすべての情報を書き込んでから、別の手順として更新を実行することです。
より適切な説明が必要な場合は、これを「手動HP」アプローチと呼びます。これは、すべての変更情報を(最初のクエリで見られるように)Eager Table Spoolに書き込んでから、そのスプールから更新を実行するのと概念的に似ているためです。
とにかく、コードは次のとおりです:
DECLARE @U AS table
(
SomeID integer NOT NULL,
StartDate date NOT NULL,
NewEndDate date NULL,
PRIMARY KEY CLUSTERED (SomeID, StartDate)
);
INSERT @U
(SomeID, StartDate, NewEndDate)
SELECT
E.SomeID,
E.StartDate,
DATEADD(DAY, -1,
LEAD(E.StartDate) OVER (
PARTITION BY E.SomeID
ORDER BY E.StartDate))
FROM dbo.Example AS E WITH (TABLOCK)
OPTION (MAXDOP 1);
UPDATE E WITH (TABLOCKX)
SET E.EndDate =
ISNULL
(
U.NewEndDate, CONVERT(date, '99991231', 112)
)
FROM dbo.Example AS E
JOIN @U AS U
ON U.SomeID = E.SomeID
AND U.StartDate = E.StartDate
OPTION (MAXDOP 1, MERGE JOIN); そのコードは意図的にテーブル変数を使用しています 一時テーブルを使用すると発生する自動作成統計のコストを回避するため。必要な計画の形がわかっていて、コストの見積もりや統計情報に依存しないため、ここでは問題ありません。
テーブル変数(トレースフラグなし)の唯一の欠点は、オプティマイザーが通常1つの行を推定し、更新用にネストされたループを選択することです。これを防ぐために、マージ結合ヒントを使用しました。繰り返しになりますが、これは達成すべき計画の形を正確に知ることによって推進されます。
テーブル変数挿入の実行後のプランは、ラッチ待機で問題が発生したクエリとまったく同じに見えます。

このプランの利点は、読み取り元のテーブルと同じテーブルを変更しないことです。ハロウィーンの保護は必要ありません。また、ラッチの干渉の可能性もありません。さらに、tempdbオブジェクトの重要な内部最適化(ロックとロギング)があり、他の通常の一括読み込みの最適化も適用されます。一括最適化は挿入に対してのみ使用可能であり、更新や削除には使用できないことに注意してください。
更新ステートメントの実行後の計画は次のとおりです。
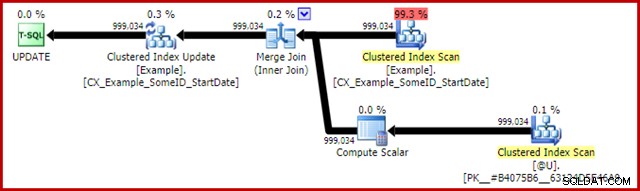
ここでのマージ結合は、効率的な1対多のタイプです。さらに重要なことに、この計画は、クラスター化インデックススキャンとクラスター化インデックス更新が同じ行セットを共有することを意味する特別な最適化の対象となります。重要な結果は、更新が更新する行を見つける必要がなくなったことです。これは、読み取りによってすでに正しく配置されています。これにより、更新時の論理読み取り(およびその他のアクティビティ)が大幅に節約されます。
通常の実行計画には、この共有行セットの最適化が適用される場所を示すものはありませんが、文書化されていないトレースフラグ8666を有効にすると、行セットの共有が使用されていることを示す更新とスキャンの追加のプロパティが公開され、更新が安全であることを確認するための手順が実行されますハロウィーンの問題から。
2つのクエリの統計IO出力は次のとおりです。
Table 'Worktable'. Scan count 0, logical reads 0, physical reads 0 Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 (999034 row(s) affected) Table 'Example'. Scan count 1, logical reads 2353, physical reads 0 Table '#B9C034B8'. Scan count 1, logical reads 2353, physical reads 0
Exampleテーブルの両方の読み取りには、ページごとに1回のスキャンと1回の論理読み取りが含まれます(前述の単純な行カウントクエリを参照)。 #B9C034B8テーブルは、テーブル変数をサポートする内部tempdbオブジェクトの名前です。両方のクエリの論理読み取りの合計は3*2353=7,059です。作業テーブルは、ウィンドウスプールによって使用されるメモリ内の内部ストレージです。
このクエリの一般的な実行時間は2300ms 。最後に、2行の番号付けクエリ(2950ms)に勝るものがありますが、見た目とは異なります。
最終的な考え
上記の「手動HP」ソリューションよりも優れたパフォーマンスを発揮する、このアップデートを作成するためのさらに優れた方法があるかもしれません。パフォーマンスの結果は、ハードウェアとSQL Serverの構成によって異なる場合もありますが、どちらもこの記事の主なポイントではありません。それは、私がより良いクエリやパフォーマンスの比較を見ることに興味がないということではありません–私はそうです。
重要なのは、SQL Serverの内部では、実行プランで公開されているよりもはるかに多くのことが行われているということです。このかなり長い記事で説明されている詳細のいくつかが、一部の人々にとって興味深い、あるいは役立つことを願っています。
パフォーマンスを期待し、どのプランの形状とプロパティが一般的に有益であるかを知ることは良いことです。この種の経験と知識は、調整を求められるクエリの99%以上に役立ちます。ただし、場合によっては、何が起こるかを確認し、それらの期待を検証するために、少し奇妙なことや変わったことを試してみるとよいでしょう。