この記事では、SQL Serverが複数の単一列の統計からの密度情報を組み合わせて、複数の列にわたる集計のカーディナリティ推定値を生成する方法を示します。詳細は、それ自体が興味深いものになることを願っています。また、カーディナリティ推定器で使用される一般的なアプローチとアルゴリズムのいくつかについての洞察も提供します。
次のAdventureWorksサンプルデータベースクエリについて考えてみます。これは、倉庫の各棚の各ビンにある製品在庫アイテムの数を一覧表示します。
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin;
推定実行プランでは、テーブルから1,069行が読み取られ、Shelfに並べ替えられています。 およびBin 注文し、Stream Aggregate演算子を使用して集計します:
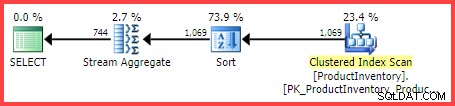
推定実行計画
問題は、SQLServerクエリオプティマイザがどのようにして744行の最終的な見積もりに到達したのかということです。
利用可能な統計
上記のクエリをコンパイルすると、クエリオプティマイザはShelfに単一列の統計を作成します およびBin 適切な統計がまだ存在しない場合は、列。特に、これらの統計は、(密度ベクトル内の)個別の列値の数に関する情報を提供します。
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Shelf]
)
WITH DENSITY_VECTOR;
DBCC SHOW_STATISTICS
(
[Production.ProductInventory],
[Bin]
)
WITH DENSITY_VECTOR; 結果は以下の表にまとめられています(3番目の列は密度から計算されます):
| 列 | 密度 | 1/密度 |
|---|---|---|
| 0.04761905 | 21 | |
| ビン | 0.01612903 | 62 |
ドキュメントに記載されているように、密度の逆数は、列内の個別の値の数です。上記の統計情報から、SQLServerは21個の異なるShelfがあったことを認識しています。 値と62個の異なるBin 統計が収集されたときのテーブルの値。
GROUP BYによって生成される行数を見積もるタスク 単一の列のみが含まれる場合(他の述語がないと仮定)、節は自明です。たとえば、GROUP BY Shelfは簡単にわかります。 21行を生成します。 GROUP BY Bin 62を生成します。
ただし、SQL Serverが個別の(Shelf, Bin)の数をどのように見積もることができるかはすぐにはわかりません。 組み合わせ GROUP BY Shelf, Bin クエリ。少し違う言い方をすると、21個の棚と62個のビンがあるとすると、棚とビンのユニークな組み合わせはいくつあるでしょうか。問題領域に関する物理的側面やその他の人間の知識は別として、答えはmax(21、62)=62から(21 * 62)=1,302までのどこかになります。詳細な情報がなければ、その範囲の見積もりをどこに売り込むかを知る明確な方法はありません。
ただし、クエリの例では、SQLServerは744.312を推定します 行(プランエクスプローラービューでは744に丸められます)が、どのような基準で?
カーディナリティ推定拡張イベント
カーディナリティ推定プロセスを調べるための文書化された方法は、拡張イベントquery_optimizer_estimate_cardinalityを使用することです。 (「デバッグ」チャネルにあるにもかかわらず)。このイベントを収集するセッションの実行中に、実行プランのオペレーターは追加のプロパティStatsCollectionIdを取得します これは、個々のオペレーターの見積もりを、それらを生成した計算にリンクします。このクエリ例では、統計収集ID 2は、groupby集計演算子のカーディナリティ推定にリンクされています。
テストクエリの拡張イベントからの関連する出力は次のとおりです。
<data name="calculator">
<type name="xml" package="package0"></type>
<value>
<CalculatorList>
<DistinctCountCalculator CalculatorName="CDVCPlanLeaf" SingleColumnStat="Shelf,Bin" />
</CalculatorList>
</value>
</data>
<data name="stats_collection">
<type name="xml" package="package0"></type>
<value>
<StatsCollection Name="CStCollGroupBy" Id="2" Card="744.31">
<LoadedStats>
<StatsInfo DbId="6" ObjectId="258099960" StatsId="3" />
<StatsInfo DbId="6" ObjectId="258099960" StatsId="4" />
</LoadedStats>
</StatsCollection>
</value>
</data> 確かに、そこにはいくつかの有用な情報があります。
プランリーフの個別値計算クラス(CDVCPlanLeaf )Shelfの単一列統計を使用して採用されました およびBin 入力として。 statsコレクション要素は、このフラグメントを実行プランに示されているID(2)と照合します。これは、 744.31のカーディナリティ推定値を示しています。 、および使用される統計オブジェクトIDに関する詳細情報。
残念ながら、イベント出力には、電卓がどのようにして最終的な数値に到達したかを正確に示すものはありません。これは、私たちが本当に興味を持っていることです。
個別のカウントの組み合わせ
文書化されていないルートを使用して、トレースフラグ 2363を使用してクエリの推定計画をリクエストできます。 および3604が有効:
SELECT
INV.Shelf,
INV.Bin,
COUNT_BIG(*)
FROM Production.ProductInventory AS INV
GROUP BY
INV.Shelf,
INV.Bin
ORDER BY
INV.Shelf,
INV.Bin
OPTION (QUERYTRACEON 3604, QUERYTRACEON 2363); これにより、デバッグ情報がSQL ServerManagementStudioの[メッセージ]タブに返されます。興味深い部分は以下に再現されています:
Begin distinct values computation
Input tree:
LogOp_GbAgg OUT(QCOL: [INV].Shelf,QCOL: [INV].Bin,COL: Expr1001 ,) BY(QCOL: [INV].Shelf,QCOL: [INV].Bin,)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
AncOp_PrjList
AncOp_PrjEl COL: Expr1001
ScaOp_AggFunc stopCountBig
ScaOp_Const TI(int,ML=4) XVAR(int,Not Owned,Value=0)
Plan for computation:
CDVCPlanLeaf
0 Multi-Column Stats, 2 Single-Column Stats, 0 Guesses
Loaded histogram for column QCOL: [INV].Shelf from stats with id 3
Loaded histogram for column QCOL: [INV].Bin from stats with id 4
Using ambient cardinality 1069 to combine distinct counts:
21
62
Combined distinct count: 744.312
Result of computation: 744.312
Stats collection generated:
CStCollGroupBy(ID=2, CARD=744.312)
CStCollBaseTable(ID=1, CARD=1069 TBL: Production.ProductInventory AS TBL: INV)
End distinct values computation これは、拡張イベントが(おそらく)より使いやすい形式で行ったのとほぼ同じ情報を示しています:
- (
LogOp_GbAggのカーディナリティ推定を計算するための入力関係演算子 –集計による論理グループ) - 使用した計算機(
CDVCPlanLeaf)および入力統計 - 結果の統計収集の詳細
興味深い新しい情報は、アンビエントカーディナリティを使用して個別のカウントを組み合わせることに関する部分です。 。
これは、値21、62、および1069が使用されたことを明確に示していますが、(イライラして) 744.312に到達するために実行された計算が正確ではありません。 結果。
デバッガーへ!
デバッガーを接続してパブリックシンボルを使用すると、サンプルクエリのコンパイル中にたどるコードパスを詳細に調べることができます。
以下のスナップショットは、プロセスの代表的なポイントでの呼び出しスタックの上部を示しています。
MSVCR120!log sqllang!OdblNHlogN sqllang!CCardUtilSQL12::ProbSampleWithoutReplacement sqllang!CCardUtilSQL12::CardDistinctMunged sqllang!CCardUtilSQL12::CardDistinctCombined sqllang!CStCollAbstractLeaf::CardDistinctImpl sqllang!IStatsCollection::CardDistinct sqllang!CCardUtilSQL12::CardGroupByHelperCore sqllang!CCardUtilSQL12::PstcollGroupByHelper sqllang!CLogOp_GbAgg::PstcollDeriveCardinality sqllang!CCardFrameworkSQL12::DeriveCardinalityProperties
ここにいくつかの興味深い詳細があります。ボトムアップで作業すると、更新されたCE(CCardFrameworkSQL12)を使用してカーディナリティが導出されていることがわかります。 )SQL Server 2014以降で使用可能(元のCEはCCardFrameworkSQL7です )、group by集計論理演算子(CLogOp_GbAgg 。
明確なカーディナリティを計算するには、置換せずにサンプリングを使用して、複数の入力を組み合わせる(結合する)必要があります。
Hへの参照 上から2番目の方法の(自然)対数は、計算でのシャノンエントロピーの使用を示しています。
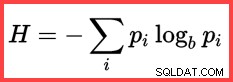
シャノンエントロピー
エントロピーを使用して、2つの統計間の情報相関(相互情報量)を推定できます。
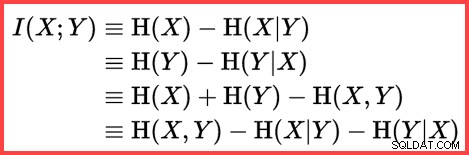
相互情報量
これらすべてを組み合わせることで、SQL Serverが置換なしのサンプリング、シャノンエントロピー、および相互情報量を使用する方法に一致するT-SQL計算スクリプトを構築できます。 最終的なカーディナリティの見積もりを作成します。
入力番号(周囲のカーディナリティと各列の個別の値の数)から始めます:
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62; 頻度 各列のは、個別の値ごとの平均行数です:
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2; 置換なしのサンプリング(SWR)は、行の総数から個別の値(頻度)ごとの平均行数を差し引くだけの簡単な問題です。
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2; エントロピー(N log N)と相互情報量を計算します:
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Using logarithms allows us to express
-- multiplication as addition and division as subtraction
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4); これで、2つの統計セットがどの程度相関しているかを推定したので、最終的な推定値を計算できます。
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2;
計算結果は744.311823994677で、これは 744.312です。 小数点第3位を四捨五入します。
便宜上、コード全体を1つのブロックにまとめました。
DECLARE
@Card float = 1069,
@Distinct1 float = 21,
@Distinct2 float = 62;
DECLARE
@Frequency1 float = @Card / @Distinct1,
@Frequency2 float = @Card / @Distinct2;
-- Sample without replacement
DECLARE
@SWR1 float = @Card - @Frequency1,
@SWR2 float = @Card - @Frequency2,
@SWR3 float = @Card - @Frequency1 - @Frequency2;
-- Entropy
DECLARE
@E1 float = (@SWR1 + 0.5) * LOG(@SWR1),
@E2 float = (@SWR2 + 0.5) * LOG(@SWR2),
@E3 float = (@SWR3 + 0.5) * LOG(@SWR3),
@E4 float = (@Card + 0.5) * LOG(@Card);
-- Mutual information
DECLARE
@MI float = EXP(@E1 + @E2 - @E3 - @E4);
-- Final estimate
SELECT (1e0 - @MI) * @Distinct1 * @Distinct2; 最終的な考え
この場合、最終的な見積もりは不完全です。サンプルのクエリは実際には 441を返します。 行。
改善された見積もりを取得するために、オプティマイザーにBinの密度に関するより良い情報を提供することができます。 およびShelf 複数列の統計を使用する列。例:
CREATE STATISTICS stat_Shelf_Bin ON Production.ProductInventory (Shelf, Bin);
その統計が適切に配置されている場合(指定されたとおり、または同様の複数列インデックスを追加した場合の副作用として)、サンプルクエリのカーディナリティ推定は正確に正しくなります。ただし、このような単純な集計を計算することはめったにありません。追加の述語を使用すると、複数列の統計の効果が低下する可能性があります。それでも、複数列の統計によって提供される追加の密度情報は、集計(および同等性の比較)に役立つ可能性があることを覚えておくことが重要です。
複数列の統計がなくても、追加の述語を含む集計クエリでも、この記事に示されている基本的なロジックを使用できる場合があります。たとえば、数式をテーブルのカーディナリティに適用する代わりに、入力ヒストグラムに段階的に適用できます。
関連コンテンツ:COUNT式の述語のカーディナリティ推定