私が何年にもわたって遭遇したほとんどすべての計算列関連のパフォーマンスの問題には、次の根本的な原因の1つ(または複数)がありました:
- 実装の制限
- クエリオプティマイザでのコストモデルサポートの欠如
- 最適化を開始する前に計算された列定義の展開
実装制限の例 計算列にフィルター処理されたインデックスを作成できません(永続化されている場合でも)。この問題のカテゴリについてできることはあまりありません。製品の改善が到着するのを待つ間、回避策を使用する必要があります。
オプティマイザーの欠如コストモデルのサポート つまり、SQL Serverは、複雑さや実装に関係なく、スカラー計算に小さな固定費を割り当てます。結果として、サーバーは、永続化された値またはインデックス付けされた値を直接読み取るのではなく、保存された計算列の値を再計算することを決定することがよくあります。これは、計算された式が高価な場合、たとえばスカラーのユーザー定義関数を呼び出す場合など、特に苦痛です。
定義の拡張に関する問題 もう少し複雑で、幅広い効果があります。
計算列拡張の問題
SQL Serverは通常、クエリの正規化のバインドフェーズ中に、計算列を基になる定義に展開します。これは、クエリのコンパイルプロセスの非常に初期の段階であり、計画の選択が決定されるかなり前の段階です(些細な計画を含む)。
理論的には、早期拡張を実行すると、他の方法では見逃される最適化が可能になる可能性があります。たとえば、オプティマイザは、クエリとメタデータ(制約など)に他の情報があれば、簡略化を適用できる場合があります。これは、ビュー定義が展開されるのと同じ種類の推論です(NOEXPANDを除く) ヒントが使用されます。
コンパイルプロセスの後半(ただし、些細な計画が検討される前でも)、オプティマイザーは、式を永続化またはインデックス付けされた計算列に一致させるように見えます。問題は、その間にオプティマイザーのアクティビティによって拡張された式が変更され、照合ができなくなった可能性があることです。
これが発生すると、最終的な実行プランは、オプティマイザが永続化またはインデックス付けされた計算列を使用する「明らかな」機会を逃したように見えます。実行計画には、原因を特定するのに役立つ詳細がほとんどないため、これをデバッグおよび修正するのにイライラする可能性のある問題になっています。
式を計算列に一致させる
ここには2つの別個のプロセスがあることを特に明確にする価値があります。
- 計算列の初期拡張。および
- 後で、式を計算列に一致させようとします。
特に、計算列の拡張から生じた式だけでなく、クエリ式は後で適切な計算列に一致する可能性があることに注意してください。
計算列式のマッチングにより、元のクエリのテキストを変更できない場合でも、計画を改善できます。たとえば、既知のクエリ式に一致する計算列を作成すると、オプティマイザは計算列に関連付けられた統計とインデックスを使用できます。この機能は、概念的にはEnterpriseEditionのインデックス付きビューマッチングに似ています。計算列マッチングはすべてのエディションで機能します。
実用的な観点から、私自身の経験では、一般的なクエリ式を計算列に一致させることで、パフォーマンス、効率、および実行プランの安定性を実際に向上させることができます。一方、計算列の拡張が価値があるとは(あったとしても)めったに見つかりませんでした。有用な最適化が得られることは決してないようです。
計算列の使用
どちらでもない計算列 永続化もインデックス化も有効な用途があります。たとえば、列が決定論的で正確な場合(浮動小数点要素がない場合)、自動統計をサポートできます。また、ストレージスペースを節約するために使用することもできます(ランタイムプロセッサを少し余分に使用する必要があります)。最後の例として、毎回クエリで明示的に書き出すのではなく、単純な計算が常に正しく実行されるようにするための優れた方法を提供できます。
持続 計算列が製品に追加され、決定論的であるが「不正確な」(浮動小数点)列にインデックスを作成できるようになりました。私の経験では、この意図された使用法は比較的まれです。おそらくこれは、浮動小数点データにあまり遭遇しないためです。
浮動小数点インデックスはさておき、永続化された列はかなり一般的です。ある程度、これは、経験の浅いユーザーが、インデックスを作成する前に、計算列を常に永続化する必要があると想定していることが原因である可能性があります。経験豊富なユーザーは、パフォーマンスが向上する傾向があることに気付いたという理由だけで、永続化された列を使用する場合があります。
インデックス付き 計算列(永続化されているかどうかに関係なく)を使用して、順序付けと効率的なアクセス方法を提供できます。計算された値をベーステーブルに永続化せずにインデックスに格納すると便利な場合があります。同様に、適切な計算列も、キー列ではなくインデックスに含まれる場合があります。
パフォーマンスの低下
パフォーマンス低下の主な原因は、インデックス付きまたは永続化された計算列値を期待どおりに使用できないという単純な失敗です。インデックス付きまたは永続化された計算列を使用した明らかにより良いプランが存在するのに、オプティマイザーがひどい実行プランを選択する理由を尋ねる長年の質問の数を数え切れませんでした。
それぞれの場合の正確な原因はさまざまですが、ほとんどの場合、コストベースの決定に誤りがあります(スカラーには低い固定コストが割り当てられているため)。または、展開された式を永続化された計算列またはインデックスに一致させることができませんでした。
マッチバックの失敗は、直交エンジン機能との複雑な相互作用を伴うことが多いため、私にとって特に興味深いものです。同様に、「一致」に失敗すると、内部クエリツリー内の位置に(列ではなく)式が残り、重要な最適化ルールが一致しなくなります。どちらの場合も、結果は同じです。最適ではない実行計画です。
さて、人々は一般的に、保存された値が実際に使用されることを強く期待して、計算列にインデックスを付けたり、永続化したりすると言っても過言ではありません。 SQL Serverが、意図的に提供された保存された値を無視しながら、基になる式を毎回再計算するのを見るのは、非常にショックになる可能性があります。人々は、望ましくない結果につながる内部の相互作用やコストモデルの欠陥に常に関心を持っているわけではありません。回避策が存在する場合でも、これらを発見してテストするには、時間、スキル、および労力が必要です。
つまり、多くの人は、SQLServerが永続化された値またはインデックス付けされた値を使用することを単に好むでしょう。 常に。
新しいオプション
これまで、SQL Serverに常に保存された値を使用させる方法はありませんでした(NOEXPANDに相当するものはありません)。 ビューのヒント)。計画ガイドが機能する状況もありますが、最初に必要な計画形状を生成できるとは限らず、すべての計画要素と位置を強制できるわけではありません(フィルターや計算スカラーなど)。
きちんとした、完全に文書化されたソリューションはまだありませんが、SQL Server 2016の最近の更新により、興味深い新しいアプローチが提供されています。これは、少なくともSQL Server2016SP1の累積的な更新プログラム2またはSQLServer2016RTMの累積的な更新プログラム4でパッチが適用されたSQLServer2016インスタンスに適用されます。
関連する更新については、次のドキュメントに記載されています。修正:SQLServer2016で計算されたパーティション列を含むテーブルのパーティションをオンラインで再構築できない
サポートドキュメントでよくあることですが、これは問題に対処するためにエンジンで何が変更されたかを正確に示しているわけではありません。タイトルと説明から判断すると、それは確かに私たちの現在の懸念にひどく関連しているようには見えません。それにもかかわらず、この修正により、サポートされる新しいトレースフラグ 176が導入されます。 、FDontExpandPersistedCCと呼ばれるコードメソッドでチェックされます 。メソッド名が示すように、これにより、永続化された計算列が展開されなくなります。
これには3つの重要な注意事項があります:
- 計算列は永続化する必要があります 。インデックスが作成されている場合でも、列は永続化する必要があります。
- 一般的なクエリ式から永続化された計算列へのマッチバックは無効です 。
- ドキュメントにはトレースフラグの機能は記載されておらず、その他の用途についても規定されていません。したがって、トレースフラグ176を使用して、永続化された計算列の拡張を防ぐことを選択した場合は、自己責任で行ってください。
このトレースフラグは、起動時の–Tとして有効です。 オプション、DBCC TRACEONを使用したグローバルスコープとセッションスコープの両方 、およびOPTION (QUERYTRACEON)を使用したクエリごと 。
例
これは、数年前にDatabase Administrators Stack Exchangeで回答した(実際の問題に基づく)質問の簡略版です。テーブル定義には、永続化された計算列が含まれます:
CREATE TABLE dbo.T
(
ID integer IDENTITY NOT NULL,
A varchar(20) NOT NULL,
B varchar(20) NOT NULL,
C varchar(20) NOT NULL,
D date NULL,
Computed AS A + '-' + B + '-' + C PERSISTED,
CONSTRAINT PK_T_ID
PRIMARY KEY CLUSTERED (ID),
);
GO
INSERT dbo.T WITH (TABLOCKX)
(A, B, C, D)
SELECT
A = STR(SV.number % 10, 2),
B = STR(SV.number % 20, 2),
C = STR(SV.number % 30, 2),
D = DATEADD(DAY, 0 - SV.number, SYSUTCDATETIME())
FROM master.dbo.spt_values AS SV
WHERE SV.[type] = N'P'; 以下のクエリは、テーブルからすべての行を特定の順序で返し、列Dの次の値も同じ順序で返します。
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D; サブクエリでの最終的な順序付けとルックアップをサポートするための明らかなカバーインデックスは次のとおりです。
CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
オプティマイザーによって提供される実行計画は驚くべきものであり、期待外れです。
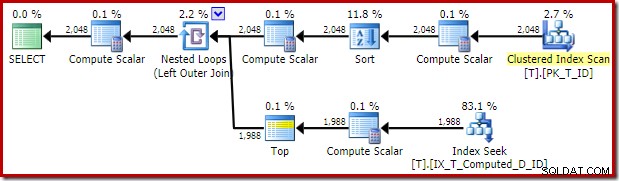
ネストされたループ結合の内側にあるインデックスシークはすべて良好のようです。ただし、外部入力でのクラスター化インデックスのスキャンと並べ替えは予期しないものです。代わりに、対象となる非クラスター化インデックスの順序付きスキャンが表示されることを期待していました。
オプティマイザーにテーブルヒント付きの非クラスター化インデックスを使用するように強制できます:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
WITH (INDEX(IX_T_Computed_D_ID)) -- New!
ORDER BY
T1.Computed, T1.D; 結果の実行プランは次のとおりです。
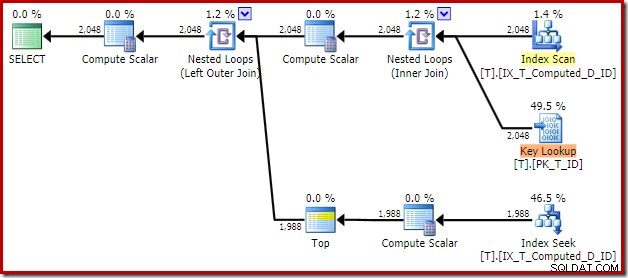
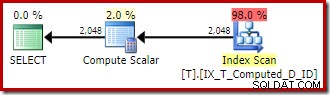
非クラスター化インデックスをスキャンすると、並べ替えは削除されますが、キールックアップが追加されます。インデックスがクエリに必要なすべての列を確実にカバーしていることを考えると、この新しいプランでのルックアップは驚くべきものです。
キールックアップ演算子のプロパティを確認する:
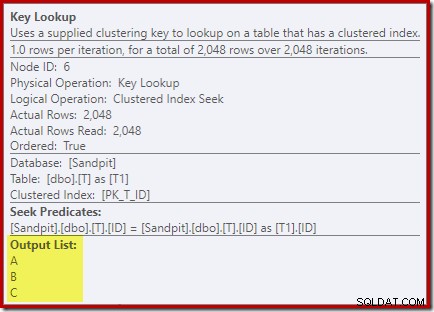
何らかの理由で、オプティマイザは、クエリに記載されていない3つの列をベーステーブルからフェッチする必要があると判断しました(設計上、非クラスタ化インデックスに存在しないため)。
実行プランを見てみると、ルックアップされた列が内側のインデックスシークに必要であることがわかります:

このシーク述語の最初の部分は、相関T2.Computed = T1.Computedに対応します。 元のクエリで。オプティマイザーは両方の計算列の定義を拡張しましたが、内部エイリアスT1の永続化およびインデックス付けされた計算列に一致するように管理されました。 。 T2を離れる 参照が展開されたため、結合の外側でベーステーブルの列(Aを指定する必要があります)が発生しました 、B 、およびC )各行の式を計算する必要があります。
時々あるように、問題がなくなるようにこのクエリを書き直すことが可能です(1つのオプションがStack Exchangeの質問に対する私の古い回答に示されています)。 SQL Server 2016を使用して、トレースフラグ176を試して、計算列が展開されないようにすることもできます。
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
(
SELECT TOP (1)
t2.D
FROM dbo.T AS T2
WHERE
T2.Computed = T1.Computed
AND T2.D > T1.D
ORDER BY
T2.D ASC
)
FROM dbo.T AS T1
ORDER BY
T1.Computed, T1.D
OPTION (QUERYTRACEON 176); -- New! 実行計画が大幅に改善されました:
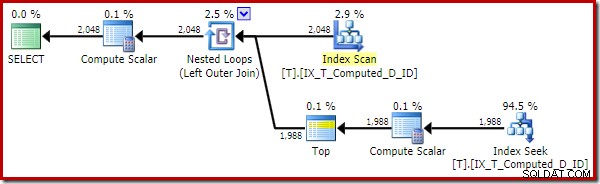
この実行プランには、計算列への参照のみが含まれています。 Compute Scalarは何の役にも立たず、オプティマイザーが家の周りで少し整頓されていればクリーンアップされます。
重要な点は、最適なインデックスが正しく使用され、並べ替えとキーの検索が削除されたことです。すべて、SQL Serverが最初から期待していなかったことを実行できないようにすることで(永続化され、インデックスが作成された計算列を拡張します)。
LEADの使用
元のStackExchangeの質問は、SQL Server 2008を対象としており、LEAD 利用できません。新しい構文を使用して、SQLServer2016で要件を表現してみましょう。
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed; SQLServer2016の実行プランは次のとおりです。
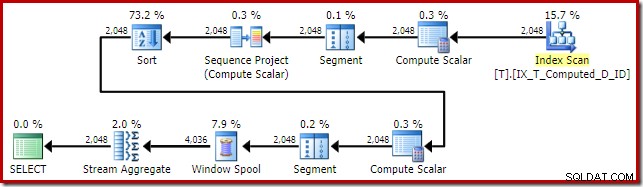
この平面形状は、単純な行モードのウィンドウ関数では非常に一般的です。予期しない項目の1つは、中央の並べ替え演算子です。データセットが大きい場合、この並べ替えはパフォーマンスとメモリ使用量に大きな影響を与える可能性があります。
ここでも、問題は計算列の拡張です。この場合、展開された式の1つは、通常のオプティマイザーロジックが並べ替えを単純化するのを妨げる位置にあります。
トレースフラグ176を使用してまったく同じクエリを試行する:
SELECT
T1.ID,
T1.Computed,
T1.D,
NextD =
LEAD(T1.D) OVER (
PARTITION BY T1.Computed
ORDER BY T1.D)
FROM dbo.T AS T1
ORDER BY
T1.Computed
OPTION (QUERYTRACEON 176); 計画を作成します:
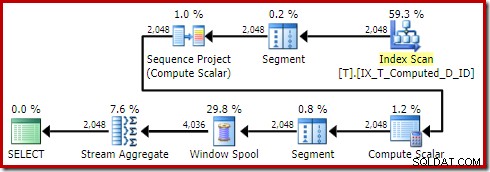
ソートが適切に消えました。また、このクエリは簡単な計画に適格であり、コストベースの最適化を完全に回避していることにも注意してください。
無効な一般式マッチング
前述の注意点の1つは、トレースフラグ176が、ソースクエリの式から永続化された計算列へのマッチングも無効にすることでした。
説明のために、次のバージョンのクエリ例について考えてみます。 LEAD 計算が削除され、SELECTの計算列への参照が削除されました およびORDER BY 句は、基になる式に置き換えられました。トレースフラグ176なしで最初に実行します:
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C; 式は永続化された計算列と照合され、実行プランは非クラスター化インデックスの単純な順序付きスキャンです。
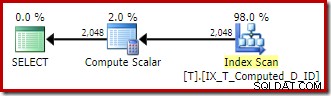
Compute Scalarには、建築上のがらくたが残っています。
次に、トレースフラグ176を有効にして同じクエリを試してください。
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); -- New! 新しい実行プランは次のとおりです。
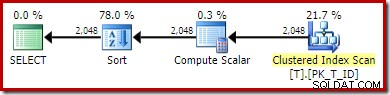
非クラスター化インデックススキャンは、クラスター化インデックススキャンに置き換えられました。 Compute Scalarは式を評価し、結果によって並べ替え順序を評価します。式を永続化された計算列に一致させる機能がないため、オプティマイザーは永続化された値または非クラスター化インデックスを利用できません。
式の一致の制限は、永続化にのみ適用されることに注意してください トレースフラグ176がアクティブな場合の計算列。計算列にインデックスを付けても永続化しない場合、式の一致は正しく機能します。
永続化された属性を削除するには、最初に非クラスター化インデックスを削除する必要があります。変更が行われると、インデックスを元に戻すことができます(式が決定論的で正確であるため):
DROP INDEX IX_T_Computed_D_ID ON dbo.T; GO ALTER TABLE dbo.T ALTER COLUMN Computed DROP PERSISTED; GO CREATE UNIQUE NONCLUSTERED INDEX IX_T_Computed_D_ID ON dbo.T (Computed, D, ID);
トレースフラグ176がアクティブな場合、オプティマイザはクエリ式を計算列に一致させるのに問題はありません。
-- Computed column no longer persisted
-- but still indexed. TF 176 active.
SELECT
T1.ID,
Computed = T1.A + '-' + T1.B + '-' + T1.C,
T1.D
FROM dbo.T AS T1
ORDER BY
T1.A + '-' + T1.B + '-' + T1.C
OPTION (QUERYTRACEON 176); 実行プランは、並べ替えなしで最適な非クラスター化インデックススキャンに戻ります。
要約すると、トレースフラグ176は、計算列の拡張が持続するのを防ぎます。副作用として、永続化された計算列のみにクエリ式が一致することも防止されます。
スキーマメタデータは、バインドフェーズ中に一度だけロードされます。トレースフラグ176は拡張を防止するため、その時点で計算列定義はロードされません。後の式と列の一致は、一致する計算列定義がないと機能しません。
最初のメタデータのロードでは、クエリで参照されている列だけでなく、すべての列が取り込まれます(最適化は後で実行されます)。これにより、すべての計算列を照合できるようになります。これは一般的に良いことです。残念ながら、ロードされた計算列の1つにスカラーのユーザー定義関数が含まれている場合、問題のある列が使用されていない場合でも、その存在によってクエリ全体の並列処理が無効になります。問題の列が永続化されている場合は、トレースフラグ176もこれに役立ちます。定義をロードしないことにより、スカラーのユーザー定義関数が存在しないため、並列処理が無効になりません。
最終的な考え
オプティマイザーが永続化またはインデックス付けされた計算列を通常の列のように扱う場合、SQLServerの世界はより良い場所であるように思われます。ほとんどすべての場合、これは現在の取り決めよりも開発者の期待によく一致します。計算列を基になる式に拡張し、後でそれらを一致させようとすることは、理論が示唆するほど実際には成功しません。
SQL Serverが永続化またはインデックス付けされた計算列の拡張を防ぐための特定のサポートを提供するまで、新しいトレースフラグ176は、不完全ではありますが、SQLServer2016ユーザーにとって魅力的なオプションです。副作用として一般式のマッチングが無効になるのは少し残念です。また、インデックスを作成するときに計算列を永続化する必要があるのも残念です。その場合、文書化された目的以外の目的でトレースフラグを使用するリスクがあります。
計算列クエリの問題の大部分は、十分な時間、労力、専門知識があれば、最終的には他の方法で解決できると言っても過言ではありません。一方、トレースフラグ176は、魔法のように機能することがよくあります。彼らが言うように、選択はあなた次第です。
最後に、トレースフラグ176の恩恵を受けるいくつかの興味深い計算列の問題を示します。
- 計算列インデックスは使用されていません
- ウィンドウ関数のパーティショニングで使用されないPERSISTED計算列
- スキャンの原因となる計算列の永続化
- MAXデータ型では使用されない計算列インデックス
- 永続化された計算列と結合に関する重大なパフォーマンスの問題
- 永続化された計算列を選択すると、SQL Serverが「スカラーを計算」するのはなぜですか?
- エンジンによって永続化された計算列の代わりに使用されるベース列
- UDFを使用して計算された列は、*その他の*列に対するクエリの並列処理を無効にします