IGNORE_DUP_KEY 一意のインデックスのオプションは、SQLServerがINSERTの試行にどのように応答するかを指定します 重複する値:テーブル(ビューではなく)にのみ適用され、挿入にのみ適用されます。 MERGEの挿入部分 ステートメントはIGNORE_DUP_KEYを無視します インデックス設定。
IGNORE_DUP_KEYの場合 OFFです 、最初に重複が発生すると、エラーが発生します 、および新しい行は挿入されません。
IGNORE_DUP_KEYの場合 ONです 、一意性に違反する挿入された行は破棄されます。残りの行は正常に挿入されます。 警告 エラーの代わりにメッセージが出力されます:
IGNORE_DUP_KEY indexオプションは、クラスター化された一意のインデックスとクラスター化されていない一意のインデックスの両方に指定できます。クラスタ化されたインデックスで使用すると、パフォーマンスが大幅に低下する可能性があります。 クラスター化されていない一意のインデックスよりも。
パフォーマンスの違いの大きさは、INSERT中に発生した一意性違反の数によって異なります。 手術。違反が多いほど、クラスター化された一意のインデックスのパフォーマンスは比較して悪くなります。違反がまったくない場合は、クラスター化されたインデックスの挿入のパフォーマンスがさらに向上する可能性があります。
IGNORE_DUP_KEYを使用したクラスター化された一意のインデックスの場合 セットすると、重複はストレージエンジンによって処理されます 。
各行の挿入に関連する作業の多くは、重複が検出される前に実行されます。たとえば、 Clustered Index Insert オペレーターは、クラスター化インデックスのbツリーを下に移動して、重複するキーを検出する前に、ページラッチと通常のロックの階層を取得して、新しい行が移動するポイントに移動します。
キーの重複状態が検出されると、エラー 上げられます。実行をキャンセルしてエラーをクライアントに返す代わりに、エラーは内部で処理されます。問題のある行は挿入されず、実行が続行され、挿入する次の行が検索されます。その行で重複キーが検出されると、別のエラーが発生して処理されます。
例外は、投げたりキャッチしたりするのに非常に費用がかかります。重複の数が多いと、実行速度が著しく低下します。
IGNORE_DUP_KEYを使用するクラスター化されていない一意のインデックスの場合 セットすると、重複はクエリプロセッサによって処理されます 。各挿入が試行される前に、重複が検出され、警告が発行されます。
クエリプロセッサは、挿入ストリームから重複を削除し、ストレージエンジンに重複が表示されないようにします。その結果、一意のキー違反エラーが発生したり、内部で処理されたりすることはありません。
実行プランで重複キーを検出して削除するコストと、重要な挿入関連の作業を実行するコストと、重複が見つかった場合にエラーをスローしてキャッチするコストとの間には、トレードオフがあります。
重複が非常にまれであると予想される場合 、ストレージエンジンソリューション(クラスター化インデックス)の方が効率的かもしれません。重複の可能性が低い場合、クエリプロセッサのアプローチは利益をもたらす可能性があります。正確なクロスオーバーポイントは、重複の検出と削除に使用される実行プランコンポーネントの実行時効率などの要因によって異なります。
この記事の残りの部分では、デモを提供し、ストレージエンジンのアプローチのパフォーマンスが非常に低い理由について詳しく説明します。
次のスクリプトは、100万行の一時テーブルを作成します。 1,000の一意の値と、一意の値ごとに1,000の行があります。このデータセットは、さまざまなインデックス構成のテーブルに挿入するためのデータソースとして使用されます。
DROP TABLE IF EXISTS #Data;
GO
CREATE TABLE #Data (c1 integer NOT NULL);
GO
SET NOCOUNT ON;
SET STATISTICS XML OFF;
DECLARE
@Loop integer = 1,
@N integer = 1;
WHILE @N <= 1000
BEGIN
SET @Loop = 1;
BEGIN TRANSACTION;
-- Add 1,000 copies of the current loop value
WHILE @Loop <= 50
BEGIN
INSERT #Data
(c1)
VALUES
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N),
(@N), (@N), (@N), (@N), (@N);
SET @Loop += 1;
END;
COMMIT TRANSACTION;
SET @N += 1;
END;
CREATE CLUSTERED INDEX cx
ON #Data (c1)
WITH (MAXDOP = 1); 一意でないクラスター化インデックスを使用したテーブル変数への次の挿入には、約 900msかかります。 :
DECLARE @T table
(
c1 integer NOT NULL
INDEX cuq CLUSTERED (c1)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
IGNORE_DUP_KEYがないことに注意してください ターゲットテーブル変数で。
同じデータを一意のクラスター化に挿入する IGNORE_DUP_KEYのインデックス ONを設定します 約15,900ms —ほぼ18倍悪い:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D;
一意の非クラスター化にデータを挿入する IGNORE_DUP_KEYのインデックス ONを設定します 約700ms :
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE NONCLUSTERED
WITH (IGNORE_DUP_KEY = ON)
);
INSERT @T
(c1)
SELECT
D.c1
FROM #Data AS D; ベースラインテストには900msかかります 100万行すべてを挿入します。非クラスター化インデックステストには700msかかります 1,000個の異なるキーだけを挿入します。クラスター化インデックステストには15,900msかかります 同じ1,000の一意の行を挿入します。
このテストは、成功した行ごとに999ユニットの無駄な作業(ラッチ、ロック、エラー処理)を生成することにより、ストレージエンジン実装のパフォーマンスの低下を明らかにするように意図的に設定されています。
意図したメッセージは、そのIGNORE_DUP_KEYではありません。 クラスター化インデックスでは常にパフォーマンスが低下しますが、クラスター化インデックスと非クラスター化インデックスには大きな違いがあります。
クラスター化されたインデックス挿入計画で確認できる量はそれほど多くありません:
Clustered Index Insertに渡される行は1,000,000行です。 演算子。1,000行を「返す」と表示されます。計画の詳細を掘り下げると、次のことがわかります。
- 挿入演算子での1,244,008個の論理読み取り。
- 実行時間の大部分は挿入に費やされます オペレーター。
- 11ミリ秒の
SOS_SCHEDULER_YIELD待機します(つまり、他の待機はありません)。
15,900ミリ秒を実際に説明するものはありません 経過時間の。
この計画では、行ごとに多くの作業を行う必要があることは明らかです。
- クラスター化インデックスのbツリーレベルをナビゲートし、ラッチとロックを行って、新しいレコードの挿入ポイントを見つけます。
- 必要なインデックスページのいずれかがメモリにない場合は、ディスクからフェッチする必要があります。
- メモリ内に新しいBツリー行を作成します。
- ログレコードを準備します。
- キーの重複が見つかった場合(ゴーストレコードではない)、エラーを発生させ、そのエラーを内部で処理し、現在の行を解放し、コード内の適切なポイントで再開して、次の候補行を処理します。
これはすべてかなりの量の作業であり、すべてが行ごとに発生することを忘れないでください。 。
私が集中したいのは、非常にであるため、エラーの発生と処理です。 高価な。上記の残りの側面は、デモでテーブル変数と一時テーブルを使用することにより、すでに可能な限り安価になっています。
私が最初にやりたいことは、クラスター化されたインデックスの挿入を示すことです。 キーが重複している場合、オペレーターは実際に例外を発生させます。
これを直接示す1つの方法は、デバッガーを接続し、例外がスローされた時点でスタックトレースをキャプチャすることです。
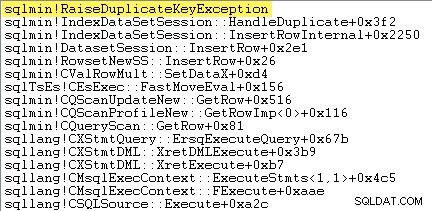
ここで重要な点は、例外のスローとキャッチには非常にコストがかかるということです。
テストの実行中にWindowsPerformanceRecorderを使用してSQLServerを監視し、WindowsPerformanceAnalyzerで結果を分析すると次のようになります。
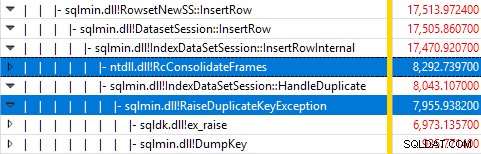
ほとんどすべてのクエリ実行時間は、sqlmin!IndexDataSetSession::InsertRowInternalで費やされます。 行の挿入以外はほとんど何もしないクエリで予想されるように。
驚いたことに、その時間の45%が、sqlmin!RaiseDuplicateKeyExceptionを介して例外を発生させるために費やされています。 さらに47%は、関連する例外キャッチブロック(ntdll!RcConsolidateFrames)に費やされます。 階層)。
要約すると、例外の発生とキャッチは、実行時間の92%を占めます。 テストクラスター化インデックス挿入クエリの例。
鋭い目の読者は、sqlmin!DumpKeyで費やされた例外発生時間のかなりの量(約12%)に気付くかもしれません。 Windowsパフォーマンスアナライザのグラフィックで。これは、いくつかの関連項目とともに、すばやく調べる価値があります。
例外を発生させる一環として、SQL Serverは、エラーが発生したときにのみ使用可能なデータを収集する必要があります。重複キー例外に関連するエラー番号は2627です。sys.messagesのメッセージテキスト そのエラー番号は次のとおりです。
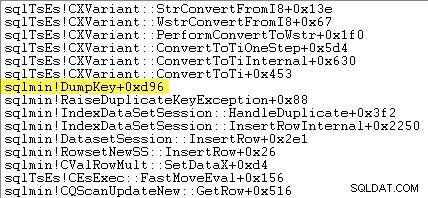
これらの場所マーカーを設定するための情報は、エラーが発生したときに収集する必要があります。後で利用することはできません。これは、制約のタイプ、その名前、ターゲットオブジェクトのフルネーム、および特定のキー値を検索してフォーマットすることを意味します。時間がかかります。
次のスタックトレースは、サーバーがDumpKey中に重複キー値をUnicode文字列としてフォーマットしていることを示しています。 電話:
例外処理には、スタックトレースのキャプチャも含まれます:
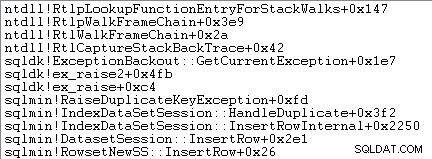
SQL Serverは、次のように、例外(スタックフレームを含む)に関する情報も小さなリングバッファーに記録します。
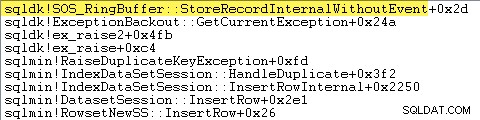
次のようなコマンドを使用して、これらのリングバッファエントリを確認できます。
SELECT TOP (10)
date_time =
DATEADD
(
MILLISECOND,
DORB.[timestamp] - DOSI.ms_ticks,
SYSDATETIME()
),
record = CONVERT(xml, DORB.record)
FROM sys.dm_os_ring_buffers AS DORB
CROSS JOIN sys.dm_os_sys_info AS DOSI
WHERE
DORB.ring_buffer_type = N'RING_BUFFER_EXCEPTION'
ORDER BY
DORB.[timestamp] DESC; 重複キー例外のxmlレコードの例を次に示します。スタックフレームに注意してください:
<Record id="4611442" type="RING_BUFFER_EXCEPTION" time="93079430">
<Exception>
<Task address="0x00000245B5E1FC28" />
<Error>2627</Error>
<Severity>14</Severity>
<State>1</State>
<UserDefined>0</UserDefined>
<Origin>0</Origin>
</Exception>
<Stack>
<frame id="0">0X00007FFAC659E80A</frame>
<frame id="1">0X00007FFACBAC0EFD</frame>
<frame id="2">0X00007FFACBAA1252</frame>
<frame id="3">0X00007FFACBA9E040</frame>
<frame id="4">0X00007FFACAB55D53</frame>
<frame id="5">0X00007FFACAB55C06</frame>
<frame id="6">0X00007FFACB3E3D0B</frame>
<frame id="7">0X00007FFAC92020EC</frame>
<frame id="8">0X00007FFACAB5B2FA</frame>
<frame id="9">0X00007FFACABA3B9B</frame>
<frame id="10">0X00007FFACAB3D89F</frame>
<frame id="11">0X00007FFAC6A9D108</frame>
<frame id="12">0X00007FFAC6AB2BBF</frame>
<frame id="13">0X00007FFAC6AB296F</frame>
<frame id="14">0X00007FFAC6A9B7D0</frame>
<frame id="15">0X00007FFAC6A9B233</frame>
</Stack>
</Record> このバックグラウンド作業はすべて、すべての例外に対して行われます。私たちのテストでは、これは999,000回発生することを意味します—重複するキー違反が発生する行ごとに1回です。
これを確認する方法はたくさんあります。たとえば、例外を使用してプロファイラートレースを実行するなどです。 エラーと警告のイベント クラス。私たちのテストケースでは、これは最終的に TextDataで999,000行を生成します このような要素:
UNIQUEKEY制約の違反'UQ__#AC166DE__3213663B8B6E2E0E'オブジェクト'dbo。@T'に重複キーを挿入できません。
重複キー値は(173)です。
Profilerをアタッチすると、必要な追加データが収集およびフォーマットされるため、各例外処理イベントが大量の追加オーバーヘッドを取得することになります。前述のデフォルトのデータは、誰も積極的に情報を消費していない場合でも、常に収集されます。
明確にするために:この記事で報告されているパフォーマンスの数値はすべて、デバッガーを接続せずに取得されたものであり、他の監視はアクティブではありません。
非常に高速ですが、非クラスター化インデックス挿入プランはかなり複雑なので、2つの部分に分けます。
一般的なテーマは、この計画は前の重複を排除するため、より高速であるということです。 それらをターゲットテーブルに挿入しようとしています。
まず、非クラスター化インデックスプランの右側:
プランのこの部分は、ターゲットテーブルでキーが一致する行をすべて拒否します IGNORE_DUP_KEYを使用した一意のインデックスの場合 ONを設定します 。
Anti Semi Joinが表示されることを期待している可能性があります ここでは、SQL Serverに、 Anti Semi Joinで必要な重複キー警告を発行するために必要なインフラストラクチャがありません。 オペレーター。 (それがまだ意味をなさない場合は、まもなく意味があります。)
代わりに、いくつかの興味深い機能を備えた計画を取得します。
- クラスター化インデックススキャン
Ordered:Trueです 左半結合のマージへの入力を提供します 列c1で並べ替え#Dataで テーブル。 - インデックススキャン テーブル変数の
Ordered:Falseです。 - 並べ替え 列ごとに行を並べ替える
c1テーブル変数で。この注文は、注文によって提供された可能性がありますc1のテーブル変数インデックスのスキャン 、ただし、オプティマイザが並べ替えを決定します 必要なレベルのハロウィーン保護を提供するための最も安価な方法です。 - テーブル変数インデックススキャン 内部
UPDLOCKがあります およびSERIALIZABLE計画の実行中にターゲットの安定性を確保するために適用されるヒント。 - Merge Left Semi Join
c1の値ごとにテーブル変数の一致をチェックします#Dataから返されます テーブル。通常の半結合とは異なり、上位の入力で受信したすべての行を出力します。 プローブ列にフラグを設定します 現在の行が一致するかどうかを示します。プローブカラムは、 Merge Left Semi Joinから放出されますExpr1012という名前の式として 。 - アサート オペレーターはプローブ列の値をチェックします
Expr1012。プローブ列の値がnull以外の行(インデックスキーの一致が見つかったことを示す)を初めて検出すると、「重複キーが無視されました」が出力されます。 メッセージ。 - アサート プローブ列がnullである行のみを渡します。これにより、重複キーエラーが発生する可能性のある着信行が排除されます。
すべてが複雑に見えるかもしれませんが、基本的には、一致が見つかった場合にフラグを設定し、フラグが最初に設定されたときに警告を発し、ターゲットテーブルにまだ存在しない行のみを挿入に渡すのと同じくらい簡単です。 。
計画の2番目の部分は、アサートに従います。 演算子:
計画の前の部分では、ターゲットテーブルで一致した行が削除されました。計画のこの部分は、挿入セット内の重複を削除します 。
たとえば、c1 = 1であるターゲットテーブルに行がないことを想像してください。 。 c1 = 1で2つの行を挿入しようとすると、重複キーエラーが発生する可能性があります。 ソーステーブルから。 IGNORE_DUP_KEY = ONのセマンティクスを尊重するために、これを回避する必要があります。 。
この側面は、セグメントによって処理されます。 およびトップ 演算子。
セグメント オペレーターが新しいフラグを設定します(Segment1015というラベルが付いています )c1の新しい値を持つ行に遭遇したとき 。行はc1で表示されるため 注文(注文を保持するマージのおかげで )、プランは同じc1を持つすべての行に依存できます 連続したストリームに到着する値。
トップ セグメントで示されるように、演算子は重複のグループごとに1つの行を渡します。 国旗。 トップの場合 オペレーターが同じセグメントに対して複数の行に遭遇しました グループ(c1 値)、「重複キーが無視されました」を出力します。 警告、プランがその状態に遭遇したのが初めての場合。
これらすべての正味の効果は、c1の一意の値ごとに1つの行のみが挿入演算子に渡されることです。 、および必要に応じて警告が生成されます。
実行プランにより、重複する可能性のあるキー違反がすべて排除されたため、残りのテーブル挿入 およびインデックス挿入 演算子は、重複キーエラーを恐れることなく、ヒープおよび非クラスター化インデックスに行を安全に挿入できます。
UPDLOCKであることを忘れないでください およびSERIALIZABLE ターゲットテーブルに適用されるヒントは、実行中にセットが変更されないようにします。つまり、並行ステートメントは、 Insertで重複キーエラーが発生するようにターゲットテーブルを変更することはできません。 演算子。プライベートテーブル変数を使用しているため、ここでは問題になりませんが、SQLServerは一般的な安全対策としてヒントを追加します。
これらのヒントがないと、計画のパート1でチェックが行われたにもかかわらず、並行プロセスによってターゲットテーブルに行が追加され、重複するキー違反が生成される可能性があります。 SQL Serverは、存在チェックの結果が引き続き有効であることを確認する必要があります。
好奇心旺盛な読者は、トレースフラグ3604および8607を有効にしてオプティマイザの出力ツリーを表示することにより、上記の機能の一部を確認できます。
PhyOp_RestrRemap
PhyOp_StreamUpdate(INS TBL: @T, iid 0x2 as IDX, Sort(QCOL: .c1, )), {
- COL: Bmk10001013 = COL: Bmk1000
- COL: c11014 = QCOL: .c1}
PhyOp_StreamUpdate(INS TBL: @T, iid 0x0 as TBLInsLocator(COL: Bmk1000 ) REPORT-COUNT), {
- QCOL: .c1= QCOL: [D].c1}
PhyOp_GbTop Group(QCOL: [D].c1,) WARN-DUP
PhyOp_StreamCheck (WarnIgnoreDuplicate TABLE)
PhyOp_MergeJoin x_jtLeftSemi M-M, Probe COL: Expr1012 ( QCOL: [D].c1) = ( QCOL: .c1)
PhyOp_Range TBL: #Data(alias TBL: D)(1) ASC
PhyOp_Sort +s -d QCOL: .c1
PhyOp_Range TBL: @T(2) ASC Hints( UPDLOCK SERIALIZABLE FORCEDINDEX )
ScaOp_Comp x_cmpIs
ScaOp_Identifier QCOL: [D].c1
ScaOp_Identifier QCOL: .c1
ScaOp_Logical x_lopIsNotNull
ScaOp_Identifier COL: Expr1012
IGNORE_DUP_KEY インデックスオプションは、ほとんどの人が頻繁に使用するものではありません。それでも、この機能がどのように実装されているか、そしてなぜIGNORE_DUP_KEYの間に大きなパフォーマンスの違いがあるのかを見るのは興味深いことです。 クラスター化インデックスと非クラスター化インデックス。
多くの場合、IGNORE_DUP_KEYに依存するのではなく、クエリプロセッサの主導に従い、重複を明示的に排除するクエリを作成することを検討します。 。この例では、次のように書くことを意味します:
DECLARE @T table
(
c1 integer NOT NULL
UNIQUE CLUSTERED -- no IGNORE_DUP_KEY!
);
INSERT @T
(c1)
SELECT DISTINCT -- Remove duplicates
D.c1
FROM #Data AS D; これは約400msで実行されます 、記録のためだけに。