他のプログラミング言語と同様に、T-SQLには一般的なバグや落とし穴があり、その中には誤った結果を引き起こすものもあれば、パフォーマンスの問題を引き起こすものもあります。これらのケースの多くには、トラブルに巻き込まれないようにするためのベストプラクティスがあります。私は仲間のMicrosoftDataPlatform MVPを調査し、彼らが頻繁に見たり、特に興味深いと思ったバグや落とし穴、およびそれらを回避するために採用したベストプラクティスについて質問しました。興味深い事例がたくさんありました。
Erland Sommarskog、Aaron Bertrand、Alejandro Mesa、Umachandar Jayachandran(UC)、Fabiano Neves Amorim、Milos Radivojevic、Simon Sabin、Adam Machanic、Thomas Grohser、Chan MingManに知識と経験を共有してくれてありがとう!
この記事は、このトピックに関するシリーズの最初の記事です。各記事は特定のテーマに焦点を当てています。今月は、決定論に関連するバグ、落とし穴、ベストプラクティスに焦点を当てます。決定論的計算は、同じ入力が与えられた場合に再現可能な結果を生成することが保証されている計算です。非決定論的計算の使用に起因する多くのバグと落とし穴があります。この記事では、非決定論的順序、非決定論的関数、非決定論的計算でのテーブル式への複数の参照、および非決定論的計算でのCASE式とNULLIF関数の使用の影響について説明します。
このシリーズの多くの例では、サンプルデータベースTSQLV5を使用しています。
非決定論的順序
T-SQLのバグの一般的な原因の1つは、非決定論的な順序の使用です。つまり、リストによる注文で行が一意に識別されない場合です。それは、プレゼンテーションの順序、TOP / OFFSET-FETCHの順序、またはウィンドウの順序である可能性があります。
たとえば、OFFSET-FETCHフィルターを使用した従来のページングシナリオを考えてみましょう。一度に10行の1ページを返すSales.Ordersテーブルをクエリし、orderdateの降順(最新のものから順に)する必要があります。簡単にするために、オフセット要素とフェッチ要素に定数を使用しますが、通常、これらは入力パラメータに基づく式です。
次のクエリ(クエリ1と呼びます)は、最近の10件の注文の最初のページを返します。
USE TSQLV5; SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
クエリ1の計画を図1に示します。
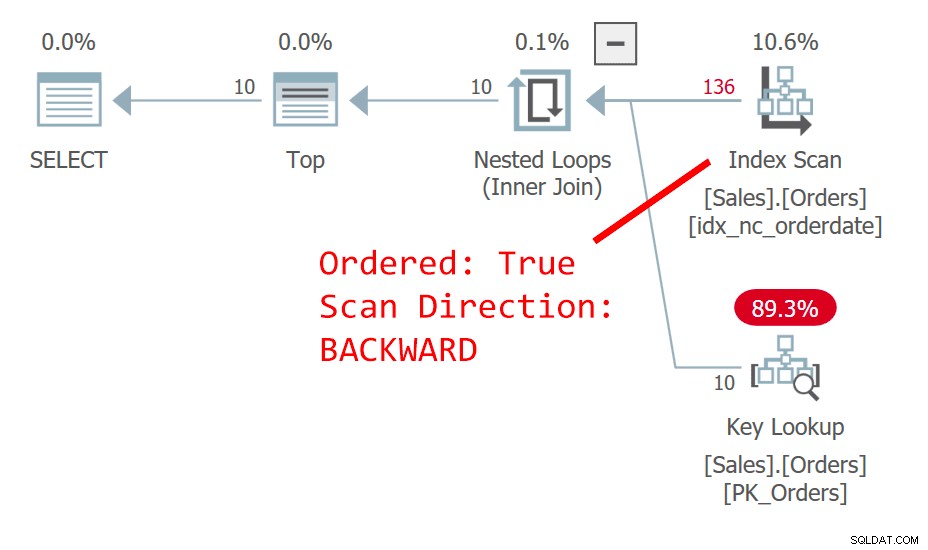 図1:クエリ1の計画
図1:クエリ1の計画
クエリは、行をorderdateの降順で並べ替えます。 orderdate列は行を一意に識別しません。この非決定的な順序は、概念的には、同じ日付の行の間に優先順位がないことを意味します。同点の場合、SQL Serverが優先する行を決定するのは、プランの選択や物理データレイアウトなどであり、繰り返し可能であると信頼できるものではありません。図1のプランは、逆順の注文日にインデックスをスキャンします。このテーブルにはorderidにクラスター化インデックスがあり、クラスター化テーブルでは、クラスター化インデックスキーが非クラスター化インデックスの行ロケーターとして使用されます。理論的にはSQLServerが包含列としてインデックスに配置できたとしても、実際には、すべての非クラスター化インデックスの最後のキー要素として暗黙的に配置されます。したがって、暗黙的に、orderdateの非クラスター化インデックスは実際には(orderdate、orderid)に定義されます。したがって、インデックスの順序付き逆方向スキャンでは、orderdateに基づくタイの行間で、orderid値が高い行がorderid値が低い行の前にアクセスされます。このクエリは次の出力を生成します:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
次に、次のクエリ(クエリ2と呼びます)を使用して、10行の2番目のページを取得します。
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
クエリの計画を図2に示します。
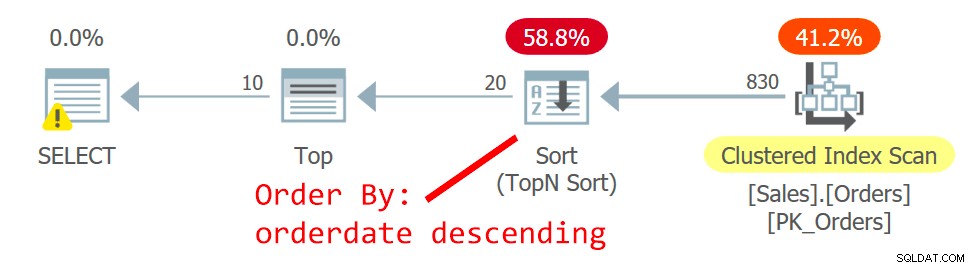
図2:クエリ2の計画
オプティマイザーは別のプランを選択します。1つはクラスター化されたインデックスを順序付けられていない方法でスキャンし、TopNソートを使用してオフセットフェッチフィルターを処理するTopオペレーターの要求をサポートします。変更の理由は、図1のプランでは、クラスター化されていない非カバーインデックスが使用されており、ページが遠くなるほど、より多くのルックアップが必要になるためです。 2ページ目のリクエストで、非カバーインデックスを使用することを正当化する転換点を超えました。
orderidをキーとして定義されたクラスター化インデックスのスキャンは順序付けされていないものですが、ストレージエンジンは内部でインデックス順序スキャンを採用しています。これは、インデックスのサイズと関係があります。最大64ページのストレージエンジンは、通常、割り当て順序スキャンよりもインデックス順序スキャンを優先します。インデックスが大きい場合でも、読み取りコミット分離レベルと読み取り専用としてマークされていないデータでは、ストレージエンジンはインデックス順序スキャンを使用して、ページ分割中に発生するページ分割の結果として行が二重に読み取られたりスキップされたりしないようにします。スキャン。与えられた条件下で、実際には、同じ日付の行の間で、このプランは、高いorderidを持つ行の前に低いorderidを持つ行にアクセスします。
このクエリは次の出力を生成します:
orderid orderdate custid ----------- ---------- ----------- 11069 2019-05-04 80 *** 11064 2019-05-01 71 11065 2019-05-01 46 11066 2019-05-01 89 11060 2019-04-30 27 11061 2019-04-30 32 11062 2019-04-30 66 11063 2019-04-30 37 11057 2019-04-29 53 11058 2019-04-29 6
基になるデータが変更されていなくても、最初のページと2番目のページの両方で同じ注文(注文ID 11069)が返されることに注意してください!
うまくいけば、ここでのベストプラクティスは明確です。確定的な順序を取得するには、リストごとの順序にタイブレーカーを追加します。たとえば、orderdateの降順、orderidの降順です。
今度は決定論的な順序で最初のページをもう一度尋ねてみてください:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 0 ROWS FETCH NEXT 10 ROWS ONLY;
次の出力が保証されます:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
2ページ目を求める:
SELECT orderid, orderdate, custid FROM Sales.Orders ORDER BY orderdate DESC, orderid DESC OFFSET 10 ROWS FETCH NEXT 10 ROWS ONLY;
次の出力が保証されます:
orderid orderdate custid ----------- ---------- ----------- 11067 2019-05-04 17 11066 2019-05-01 89 11065 2019-05-01 46 11064 2019-05-01 71 11063 2019-04-30 37 11062 2019-04-30 66 11061 2019-04-30 32 11060 2019-04-30 27 11059 2019-04-29 67 11058 2019-04-29 6
基になるデータに変更がない限り、ページ間の行の繰り返しやスキップがなく、連続したページを取得することが保証されます。
同様に、ROW_NUMBERなどのウィンドウ関数を非決定的な順序で使用すると、プランの形状とタイ間の実際のアクセス順序に応じて、同じクエリに対して異なる結果を得ることができます。次のクエリ(クエリ3と呼びます)を考えてみましょう。行番号を使用して最初のページのリクエストを実装します(説明のために注文日にインデックスを使用するように強制します):
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(idx_nc_orderdate))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; このクエリの計画を図3に示します。
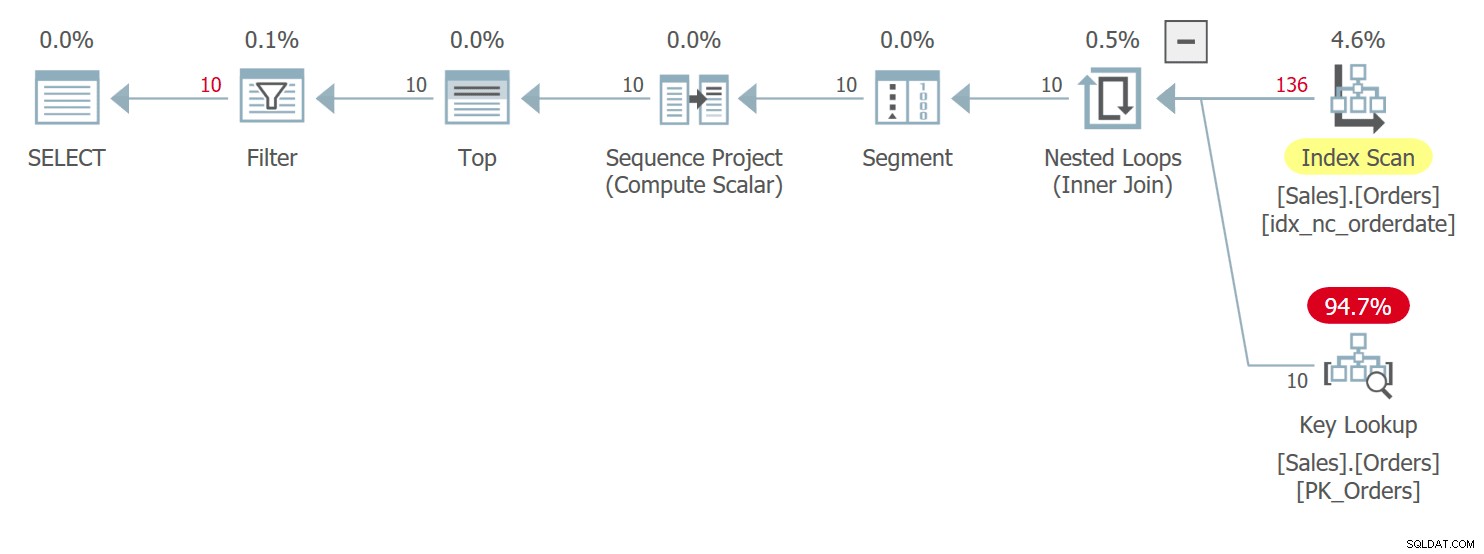
図3:クエリ3の計画
ここでは、クエリ1で前述したプランと、図1で示したプランと非常によく似た条件があります。orderdate値が同点の行の間で、このプランは、低いorderid値の前に高いorderid値の行にアクセスします。 orderid値。このクエリは次の出力を生成します:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 *** 11068 2019-05-04 62
次に、クエリを再度実行し(クエリ4と呼びます)、最初のページを要求します。今回のみ、クラスター化インデックスPK_Ordersの使用を強制します。
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders WITH (INDEX(PK_Orders))
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; このクエリの計画を図4に示します。

図4:クエリ4の計画
今回は、クエリ2について前に説明した条件と非常によく似た条件があり、そのプランは図2で前に示しました。orderdate値が同点の行の間で、このプランは、より低いorderid値の行にアクセスします。より高いorderid値。このクエリは次の出力を生成します:
orderid orderdate custid ----------- ---------- ----------- 11074 2019-05-06 73 11075 2019-05-06 68 11076 2019-05-06 9 11077 2019-05-06 65 11070 2019-05-05 44 11071 2019-05-05 46 11072 2019-05-05 20 11073 2019-05-05 58 11067 2019-05-04 17 *** 11068 2019-05-04 62
基になるデータに何も変更がない場合でも、2つの実行で異なる結果が生成されたことを確認してください。
繰り返しになりますが、ここでのベストプラクティスは単純です。次のように、タイブレーカーを追加して決定論的な順序を使用します。
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10; このクエリは次の出力を生成します:
orderid orderdate custid ----------- ---------- ----------- 11077 2019-05-06 65 11076 2019-05-06 9 11075 2019-05-06 68 11074 2019-05-06 73 11073 2019-05-05 58 11072 2019-05-05 20 11071 2019-05-05 46 11070 2019-05-05 44 11069 2019-05-04 80 11068 2019-05-04 62
返されるセットは、プランの形状に関係なく再現可能であることが保証されています。
このクエリには外部クエリの句ごとの表示順序がないため、ここでは表示順序が保証されていないことに注意してください。このような保証が必要な場合は、次のように、句ごとにプレゼンテーションの順序を追加する必要があります。
WITH C AS
(
SELECT orderid, orderdate, custid,
ROW_NUMBER() OVER(ORDER BY orderdate DESC, orderid DESC) AS n
FROM Sales.Orders
)
SELECT orderid, orderdate, custid
FROM C
WHERE n BETWEEN 1 AND 10
ORDER BY n; 非決定的関数
非決定論的関数は、同じ入力が与えられた場合、関数の異なる実行で異なる結果を返す可能性がある関数です。典型的な例は、SYSDATETIME、NEWID、およびRAND(入力シードなしで呼び出された場合)です。 T-SQLでの非決定論的関数の動作は、一部の人にとっては驚くべきものであり、場合によってはバグや落とし穴につながる可能性があります。
多くの人は、クエリの一部として非決定論的関数を呼び出すと、関数は行ごとに個別に評価されると想定しています。実際には、ほとんどの非決定論的関数は、クエリ内の参照ごとに1回評価されます。例として次のクエリを考えてみましょう。
SELECT orderid, SYSDATETIME() AS dt, RAND() AS rnd FROM Sales.Orders;
クエリには非決定論的関数SYSDATETIMEとRANDのそれぞれへの参照が1つしかないため、これらの関数はそれぞれ1回だけ評価され、その結果はすべての結果行で繰り返されます。このクエリを実行すると、次の出力が得られました。
orderid dt rnd ----------- --------------------------- ---------------------- 11008 2019-02-04 17:03:07.9229177 0.962042872007464 11019 2019-02-04 17:03:07.9229177 0.962042872007464 11039 2019-02-04 17:03:07.9229177 0.962042872007464 11040 2019-02-04 17:03:07.9229177 0.962042872007464 11045 2019-02-04 17:03:07.9229177 0.962042872007464 11051 2019-02-04 17:03:07.9229177 0.962042872007464 11054 2019-02-04 17:03:07.9229177 0.962042872007464 11058 2019-02-04 17:03:07.9229177 0.962042872007464 11059 2019-02-04 17:03:07.9229177 0.962042872007464 11061 2019-02-04 17:03:07.9229177 0.962042872007464 ...
この動作を理解しないとバグが発生する可能性がある例として、Sales.Ordersテーブルから3つのランダムな注文を返すクエリを作成する必要があるとします。一般的な最初の試みは、RAND関数に基づく順序付けでTOPクエリを使用することです。このように、関数は行ごとに個別に評価されると考えています。
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY RAND();
実際には、関数はクエリ全体に対して1回だけ評価されます。したがって、すべての行で同じ結果が得られ、順序はまったく影響を受けません。実際、このクエリの計画を確認すると、並べ替え演算子は表示されません。このクエリを複数回実行すると、同じ結果が得られ続けました:
orderid ----------- 11008 11019 11039
クエリは、実際にはORDER BY句のないクエリと同等であり、プレゼンテーションの順序は保証されません。したがって、技術的には順序は非決定的であり、理論的には実行が異なると順序が異なり、したがって上位3行の選択が異なる可能性があります。ただし、この可能性は低く、このソリューションを実行ごとに3つのランダムな行を生成するものと考えることはできません。
非決定論的関数がクエリ内の参照ごとに1回呼び出されるという規則の例外は、グローバル一意識別子(GUID)を返すNEWID関数です。クエリで使用する場合、この関数は 行ごとに個別に呼び出されます。次のクエリはこれを示しています:
SELECT orderid, NEWID() AS mynewid FROM Sales.Orders;
このクエリは次の出力を生成しました:
orderid mynewid ----------- ------------------------------------ 11008 D6417542-C78A-4A2D-9517-7BB0FCF3B932 11019 E2E46BF1-4FA6-4EF2-8328-18B86259AD5D 11039 2917D923-AC60-44F5-92D7-FF84E52250CC 11040 B6287B49-DAE7-4C6C-98A8-7DB8A879581C 11045 2E14D8F7-21E5-4039-BF7E-0A27D1A0E186 11051 FA0B7B3E-BA41-4D80-8581-782EB88836C0 11054 1E6146BB-FEE7-4FF4-A4A2-3243AA2CBF78 11058 49302EA9-0243-4502-B9D2-46D751E6EFA9 11059 F5BB7CB2-3B17-4D01-ABD2-04F3C5115FCF 11061 09E406CA-0251-423B-8DF5-564E1257F93E ...
NEWID自体の値はかなりランダムです。その上にチェックサム関数を適用すると、さらに優れたランダム分布の整数結果が得られます。したがって、3つのランダムな順序を取得する1つの方法は、次のように、CHECKSUM(NEWID())に基づく順序でTOPクエリを使用することです。
SELECT TOP (3) orderid FROM Sales.Orders ORDER BY CHECKSUM(NEWID());
このクエリを繰り返し実行すると、毎回3つのランダムな順序の異なるセットが取得されることに注意してください。 1回の実行で次の出力が得られました:
orderid ----------- 11031 10330 10962
そして、別の実行での次の出力:
orderid ----------- 10308 10885 10444
NEWID以外に、クエリでSYSDATETIMEのような非決定論的関数を使用する必要があり、行ごとに個別に評価する必要がある場合はどうなりますか?これを実現する1つの方法は、次のように非決定論的関数を呼び出すユーザー定義関数(UDF)を使用することです。
CREATE OR ALTER FUNCTION dbo.MySysDateTime() RETURNS DATETIME2
AS
BEGIN
RETURN SYSDATETIME();
END;
GO 次に、次のようにクエリでUDFを呼び出します(クエリ5と呼びます):
SELECT orderid, dbo.MySysDateTime() AS mydt FROM Sales.Orders;
今回は、UDFは行ごとに実行されます。ただし、UDFの行ごとの実行には、かなり急激なパフォーマンスの低下があることに注意する必要があります。さらに、スカラーT-SQLUDFの呼び出しは並列処理の阻害要因です。
このクエリの計画を図5に示します。
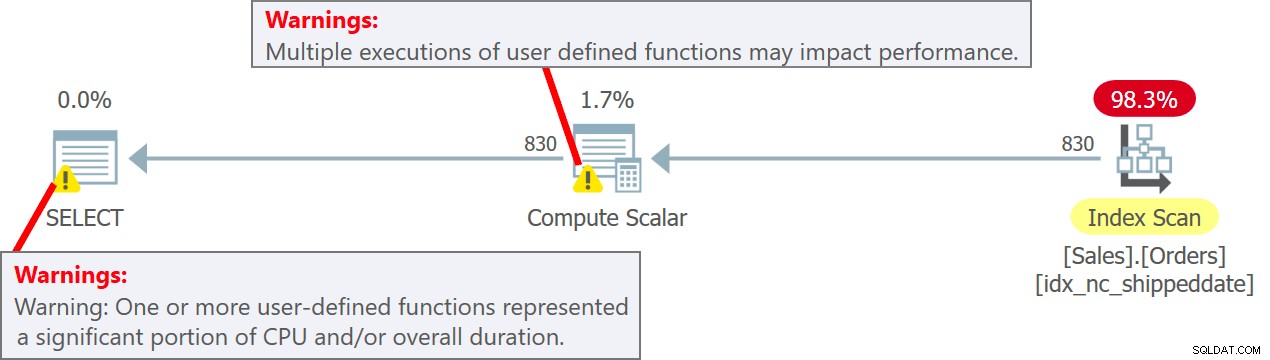
図5:クエリ5の計画
計画では、実際にUDFがComputeScalar演算子のソース行ごとに呼び出されることに注意してください。また、SentryOne Plan Explorerは、ComputeScalarオペレーターとプランのルートノードの両方でUDFを使用することに関連する潜在的なパフォーマンスの低下について警告することに注意してください。
このクエリの実行から次の出力が得られました:
orderid mydt ----------- --------------------------- 11008 2019-02-04 17:07:03.7221339 11019 2019-02-04 17:07:03.7221339 11039 2019-02-04 17:07:03.7221339 ... 10251 2019-02-04 17:07:03.7231315 10255 2019-02-04 17:07:03.7231315 10248 2019-02-04 17:07:03.7231315 ... 10416 2019-02-04 17:07:03.7241304 10420 2019-02-04 17:07:03.7241304 10421 2019-02-04 17:07:03.7241304 ...
出力行のmydt列に複数の異なる日付と時刻の値があることに注意してください。
SQL Server 2019は、このような関数をインライン化することで、スカラーT-SQLUDFによって引き起こされる一般的なパフォーマンスの問題に対処していると聞いたことがあるかもしれません。ただし、UDFをインライン化するには、要件のリストを満たす必要があります。要件の1つは、UDFがSYSDATETIMEなどの非決定論的な組み込み関数を呼び出さないことです。この要件の理由は、行ごとの実行を取得するためにUDFを正確に作成した可能性があるためです。 UDFがインライン化された場合、基になる非決定論的関数は、クエリ全体に対して1回だけ実行されます。実際、図5の計画はSQL Server 2019で生成されたものであり、UDFがインライン化されていないことがはっきりとわかります。これは、非決定論的関数SYSDATETIMEを使用しているためです。次のように、sys.sql_modulesビューでis_inlineable属性をクエリすることにより、SQLServer2019でUDFがインライン化可能かどうかを確認できます。
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.MySysDateTime');
このコードは、UDFMySysDateTimeがインライン化できないことを示す次の出力を生成します。
is_inlineable ------------- 0
インライン化可能なUDFを示すために、入力日を受け入れ、それぞれの年末日を返すEndOfyearと呼ばれるUDFの定義を次に示します。
CREATE OR ALTER FUNCTION dbo.EndOfYear(@dt AS DATE) RETURNS DATE
AS
BEGIN
RETURN DATEADD(year, DATEDIFF(year, '18991231', @dt), '18991231');
END;
GO ここでは非決定論的関数は使用されておらず、コードはインライン化に関する他の要件も満たしています。次のコードを使用して、UDFがインライン化可能であることを確認できます。
SELECT is_inlineable FROM sys.sql_modules WHERE object_id = OBJECT_ID(N'dbo.EndOfYear');
このコードは次の出力を生成します:
is_inlineable ------------- 1
次のクエリ(クエリ6と呼びます)は、UDF EndOfYearを使用して、年末日に行われた注文をフィルタリングします。
SELECT orderid FROM Sales.Orders WHERE orderdate = dbo.EndOfYear(orderdate);
このクエリの計画を図6に示します。
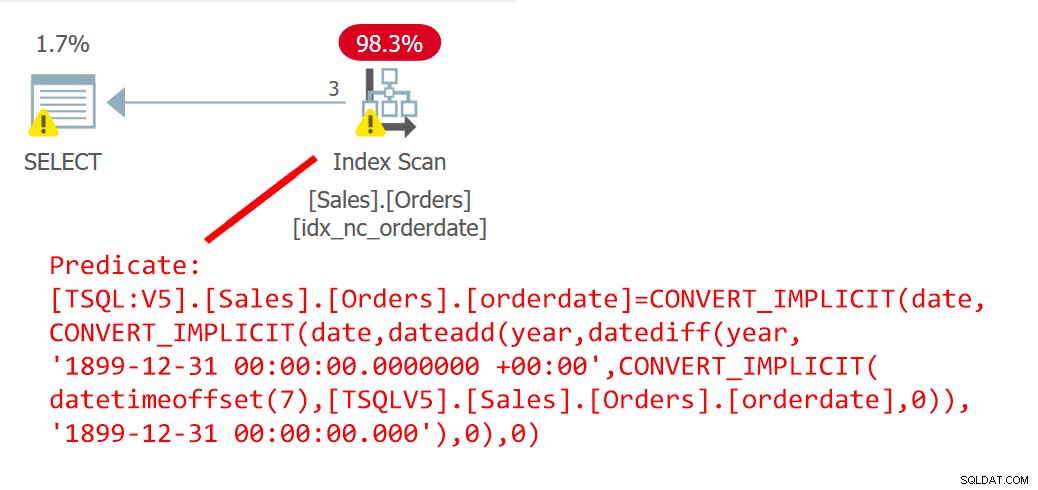
図6:クエリ6の計画
この計画は、UDFがインライン化されたことを明確に示しています。
テーブル式、非決定性、および複数の参照
前述のように、SYSDATETIMEのような非決定論的関数は、クエリ内の参照ごとに1回呼び出されます。しかし、CTEのようなテーブル式のクエリでそのような関数を一度参照し、次にCTEへの複数の参照を持つ外部クエリがある場合はどうなるでしょうか。多くの人は、テーブル式への各参照が個別に展開され、インライン化されたコードが基になる非決定論的関数への複数の参照になることに気づいていません。 SYSDATETIMEのような関数を使用すると、各実行の正確なタイミングに応じて、それぞれに対して異なる結果が得られる可能性があります。この振る舞いが驚くべきものだと感じる人もいます。
これは、次のコードで説明できます。
DECLARE @i AS INT = 1, @rc AS INT = NULL;
WHILE 1 = 1
BEGIN;
WITH C1 AS
(
SELECT SYSDATETIME() AS dt
),
C2 AS
(
SELECT dt FROM C1
UNION
SELECT dt FROM C1
)
SELECT @rc = COUNT(*) FROM C2;
IF @rc > 1 BREAK;
SET @i += 1;
END;
SELECT @rc AS distinctvalues, @i AS iterations; C2のクエリでのC1への両方の参照が同じものを表す場合、このコードは無限ループになります。ただし、2つの参照は別々に展開されるため、各呼び出しが異なる100ナノ秒間隔(結果値の精度)で行われるようなタイミングの場合、和集合は2行になり、コードはループ。このコードを実行して、自分の目で確かめてください。確かに、いくつかの反復の後、それは壊れます。実行の1つで次の結果が得られました:
distinctvalues iterations -------------- ----------- 2 448
内部クエリが非決定論的計算を使用し、外部クエリがテーブル式を複数回参照する場合、ベストプラクティスはCTEやビューなどのテーブル式の使用を避けることです。もちろん、その影響を理解し、問題がない限り、それは当然です。別のオプションとして、たとえば一時テーブルに内部クエリ結果を保持してから、必要な回数だけ一時テーブルにクエリを実行することもできます。
ベストプラクティスに従わないと問題が発生する可能性がある例を示すために、HR.Employeesテーブルの従業員をランダムにペアにするクエリを作成する必要があるとします。タスクを処理するために、次のクエリ(クエリ7と呼びます)を考え出します。
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1; このクエリの計画を図7に示します。
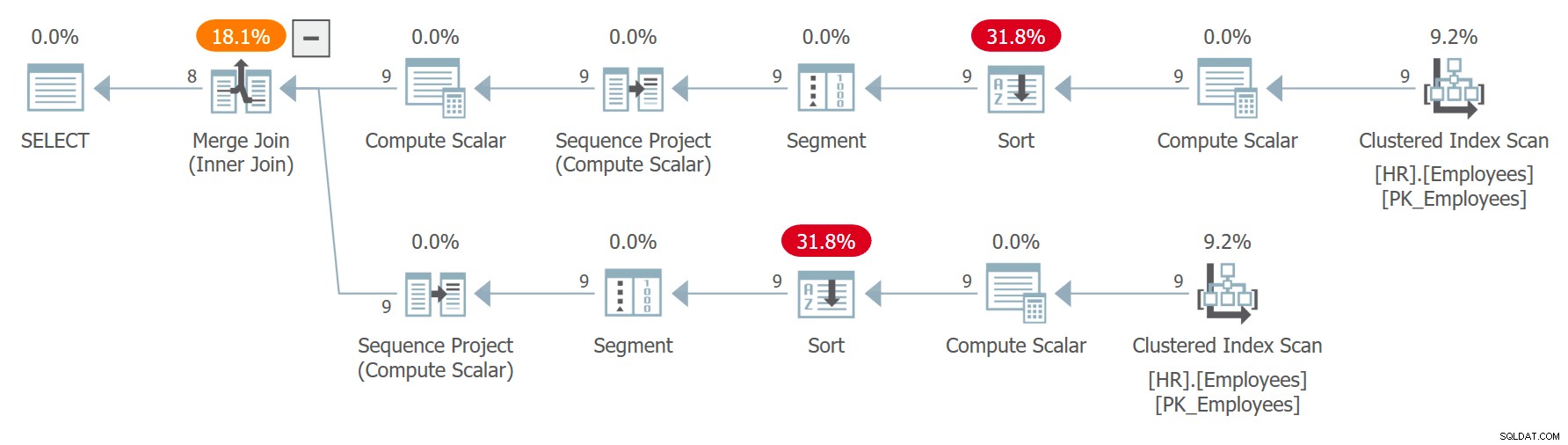
図7:クエリ7の計画
Cへの2つの参照が別々に展開され、行番号がCHECKSUM(NEWID())式の独立した呼び出しによって順序付けられた参照ごとに独立して計算されることに注意してください。これは、同じ従業員が2つの拡張参照で同じ行番号を取得することが保証されていないことを意味します。従業員がC1で行番号xを取得し、C2で行番号x – 1を取得した場合、クエリはその従業員を自分自身とペアにします。たとえば、実行の1つで次の結果が得られました:
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 3 Judy Lew 6 Paul Suurs 9 Patricia Doyle *** 9 Patricia Doyle *** 5 Sven Mortensen 4 Yael Peled 6 Paul Suurs 8 Maria Cameron 8 Maria Cameron 5 Sven Mortensen 2 Don Funk *** 2 Don Funk *** 4 Yael Peled 3 Judy Lew 7 Russell King *** 7 Russell King ***
ここでセルフペアのケースが3つあることに注意してください。これは、次のように、特に自己ペアを探す外部クエリにフィルタを追加することで見やすくなります。
WITH C AS
(
SELECT empid, firstname, lastname, ROW_NUMBER() OVER(ORDER BY CHECKSUM(NEWID())) AS n
FROM HR.Employees
)
SELECT
C1.empid AS empid1, C1.firstname AS firstname1, C1.lastname AS lastname1,
C2.empid AS empid2, C2.firstname AS firstname2, C2.lastname AS lastname2
FROM C AS C1
INNER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.empid = C2.empid; 問題を確認するには、このクエリを何度も実行する必要がある場合があります。実行の1つで得た結果の例を次に示します。
empid1 firstname1 lastname1 empid2 firstname2 lastname2 ----------- ---------- -------------------- ----------- ---------- -------------------- 5 Sven Mortensen 5 Sven Mortensen 2 Don Funk 2 Don Funk
ベストプラクティスに従うと、この問題を解決する1つの方法は、内部クエリの結果を一時テーブルに永続化し、必要に応じて一時テーブルの複数のインスタンスをクエリすることです。
別の例は、非決定論的な順序の使用とテーブル式への複数の参照から生じる可能性のあるバグを示しています。 Sales.Ordersテーブルをクエリする必要があり、傾向分析を行うために、注文日の順序に基づいて各注文を次の注文とペアにする必要があるとします。ソリューションはSQLServer2012より前のシステムと互換性がある必要があります。つまり、明らかなLAG/LEAD関数を使用することはできません。行番号を計算するCTEを使用して、注文日の順序に基づいて行を配置し、CTEの2つのインスタンスを結合して、行番号間のオフセット1に基づいて順序をペアにすることにします(このクエリ8と呼びます):
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1; このクエリの計画を図8に示します。
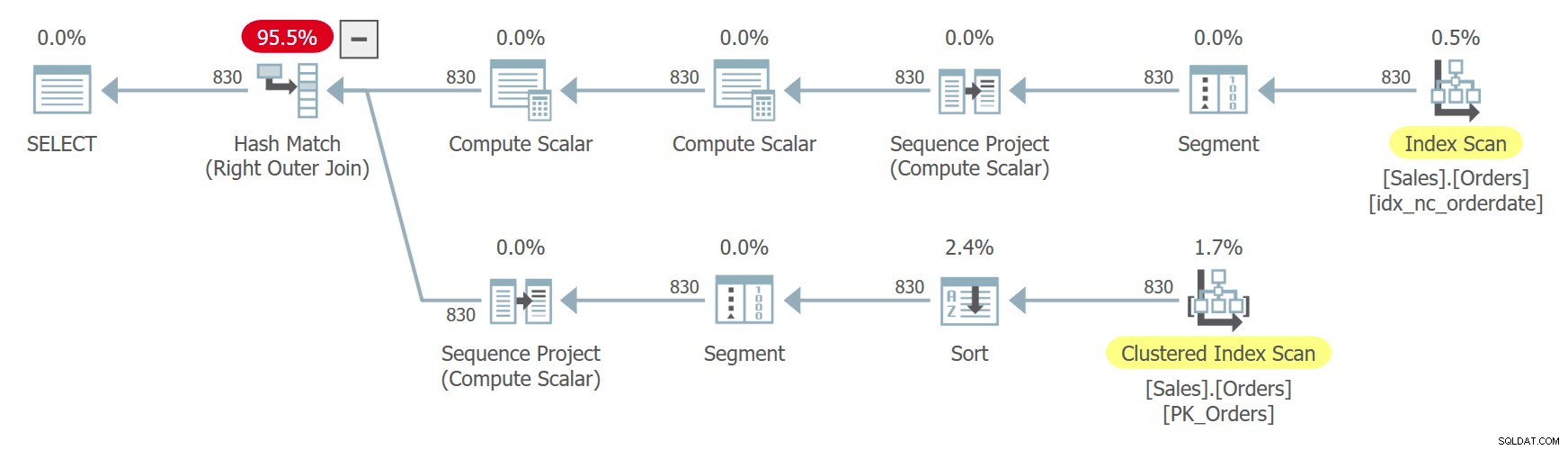 図8:クエリ8の計画
図8:クエリ8の計画
orderdateは一意ではないため、行番号の順序は決定論的ではありません。 CTEへの2つの参照が別々に展開されることに注意してください。不思議なことに、クエリは各インスタンスから異なる列のサブセットを探しているため、オプティマイザーはそれぞれの場合に異なるインデックスを使用することを決定します。あるケースでは、orderdateのインデックスの順序付けされた逆方向スキャンを使用し、orderidの降順に基づいて同じ日付の行を効果的にスキャンします。もう1つのケースでは、クラスター化インデックスをスキャンし、falseの順序で並べ替えてから並べ替えますが、同じ日付の行間では、事実上、orderidの昇順で行にアクセスします。これは、前の非決定論的順序に関するセクションで提供したのと同様の理由によるものです。これにより、同じ行が一方のインスタンスで行番号xを取得し、もう一方のインスタンスで行番号x –1を取得する可能性があります。このような場合、結合は、次の順序ではなく、それ自体と順序を一致させることになります。
このクエリを実行すると、次の結果が得られました。
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11074 2019-05-06 73 NULL NULL 11075 2019-05-06 68 11077 2019-05-06 11076 2019-05-06 9 11076 2019-05-06 *** 11077 2019-05-06 65 11075 2019-05-06 11070 2019-05-05 44 11074 2019-05-06 11071 2019-05-05 46 11073 2019-05-05 11072 2019-05-05 20 11072 2019-05-05 *** ...
結果の自己一致を観察します。繰り返しになりますが、次のように自己一致を探すフィルターを追加することで、問題をより簡単に特定できます。
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate DESC) AS n
FROM Sales.Orders
)
SELECT
C1.orderid AS orderid1, C1.orderdate AS orderdate1, C1.custid AS custid1,
C2.orderid AS orderid2, C2.orderdate AS orderdate2
FROM C AS C1
LEFT OUTER JOIN C AS C2
ON C1.n = C2.n + 1
WHERE C1.orderid = C2.orderid; このクエリから次の出力が得られました:
orderid1 orderdate1 custid1 orderid2 orderdate2 ----------- ---------- ----------- ----------- ---------- 11076 2019-05-06 9 11076 2019-05-06 11072 2019-05-05 20 11072 2019-05-05 11062 2019-04-30 66 11062 2019-04-30 11052 2019-04-27 34 11052 2019-04-27 11042 2019-04-22 15 11042 2019-04-22 ...
ここでのベストプラクティスは、ウィンドウの順序句にorderidのようなタイブレーカーを追加することにより、決定論を保証するために一意の順序を使用することを確認することです。したがって、同じCTEへの複数の参照がある場合でも、行番号は両方で同じになります。計算の繰り返しを避けたい場合は、内部クエリ結果を保持することも検討できますが、その場合は、そのような作業の追加コストを考慮する必要があります。
CASE/NULLIFおよび非決定論的関数
クエリに非決定論的関数への複数の参照がある場合、各参照は個別に評価されます。驚くべきことであり、バグを引き起こす可能性さえあるのは、1つの参照を作成することもありますが、暗黙的に複数の参照に変換されることです。これは、CASE式とIIF関数のいくつかの使用法の状況です。
次の例を考えてみましょう:
SELECT CASE ABS(CHECKSUM(NEWID())) % 2 WHEN 0 THEN 'Even' WHEN 1 THEN 'Odd' END;
Here the outcome of the tested expression is a nonnegative integer value, so clearly it has to be either even or odd. It cannot be neither even nor odd. However, if you run this code enough times, you will sometimes get a NULL indicating that the implied ELSE NULL clause of the CASE expression was activated. The reason for this is that the above expression translates to the following:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN 'Even'
WHEN ABS(CHECKSUM(NEWID())) % 2 = 1 THEN 'Odd'
ELSE NULL
END; In the converted expression there are two separate references to the tested expression that generates a random nonnegative value, and each gets evaluated separately. One possible path is that the first evaluation produces an odd number, the second produces an even number, and then the ELSE NULL clause is activated.
Here’s a very similar situation with the NULLIF function:
SELECT NULLIF(ABS(CHECKSUM(NEWID())) % 2, 0);
This expression generates a random nonnegative value, and is supposed to return 1 when it’s odd, and NULL otherwise. It’s never supposed to return 0 since in such a case the 0 is supposed to be replaced with a NULL. Run it a few times and you will see that in some cases you get a 0. The reason for this is that the above expression internally translates to the following one:
SELECT
CASE
WHEN ABS(CHECKSUM(NEWID())) % 2 = 0 THEN NULL
ELSE ABS(CHECKSUM(NEWID())) % 2
END; A possible path is that the first WHEN clause generates a random odd value, so the ELSE clause is activated, and the ELSE clause generates a random even value so the % 2 calculation results in a 0.
In both cases this behavior is standard, so the bug is more in the eyes of the beholder based on your expectations and your choice of how to write the code. The best practice in both cases is to persist the result of the original calculation and then interact with the persisted result. If it’s a single value, store the result in a variable first. If you’re querying tables, first persist the result of the nondeterministic calculation in a column in a temporary table, and then apply the CASE/IIF logic in the query against the temporary table.
結論
This article is the first in a series about T-SQL bugs, pitfalls and best practices, and is the result of discussions with fellow Microsoft Data Platform MVPs who shared their experiences. This time I focused on bugs and pitfalls that resulted from using nondeterministic order and nondeterministic calculations. In future articles I’ll continue with other themes. If you have bugs and pitfalls that you often stumble into, or that you find as particularly interesting, please do share!