 この記事は、テーブル式に関するシリーズの第8部です。これまで、テーブル式の背景を説明し、派生テーブルの論理的側面と最適化の側面の両方、CTEの論理的側面、およびCTEの最適化の側面のいくつかについて説明しました。今月は、CTEの最適化の側面、特に複数のCTE参照の処理方法について引き続き取り上げます。
この記事は、テーブル式に関するシリーズの第8部です。これまで、テーブル式の背景を説明し、派生テーブルの論理的側面と最適化の側面の両方、CTEの論理的側面、およびCTEの最適化の側面のいくつかについて説明しました。今月は、CTEの最適化の側面、特に複数のCTE参照の処理方法について引き続き取り上げます。
私の例では、サンプルデータベースTSQLV5を引き続き使用します。 TSQLV5を作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
複数の参照と非決定性
先月、CTEがネストされないのに対し、一時テーブルとテーブル変数は実際にはデータを保持することを説明し、実証しました。クエリのパフォーマンスの観点から、CTEを使用するのが理にかなっている場合と、一時オブジェクトを使用するのが理にかなっている場合の観点から、推奨事項を提供しました。ただし、ソリューションのパフォーマンスを超えて検討するCTE最適化、つまり物理処理のもう1つの重要な側面があります。それは、外部クエリからのCTEへの複数の参照がどのように処理されるかです。同じCTEへの複数の参照を持つ外部クエリがある場合、それぞれが個別にネストされていないことを理解することが重要です。 CTEの内部クエリに非決定論的な計算がある場合、それらの計算は、異なる参照で異なる結果をもたらす可能性があります。
たとえば、CTEの内部クエリでSYSDATETIME関数を呼び出して、dtという結果列を作成するとします。一般に、入力に変更がないと仮定すると、関連する行数に関係なく、組み込み関数はクエリと参照ごとに1回評価されます。外部クエリからCTEを1回だけ参照するが、dt列を複数回操作する場合、すべての参照は同じ関数評価を表し、同じ値を返すことになっています。ただし、外部クエリでCTEを複数回参照する場合は、CTEを参照する複数のサブクエリ、または同じCTEの複数のインスタンス間の結合(C1とC2のエイリアスなど)、C1.dtおよびC2.dtは、基になる式のさまざまな評価を表し、さまざまな値になる可能性があります。
これを実証するために、次の3つのバッチを検討してください。
-- Batch 1
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
SELECT @i += 1 WHERE SYSDATETIME() = SYSDATETIME();
PRINT @i;
GO
-- Batch 2
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 FROM C WHERE dt = dt;
PRINT @i;
GO
-- Batch 3
DECLARE @i AS INT = 1;
WHILE @@ROWCOUNT = 1
WITH C AS ( SELECT SYSDATETIME() AS dt )
SELECT @i += 1 WHERE (SELECT dt FROM C) = (SELECT dt FROM C);
PRINT @i;
GO 今説明したことに基づいて、どのバッチに無限ループがあり、述語の2つの比較対象が異なる値に評価されたためにいずれが停止するかを特定できますか?
SYSDATETIMEのような組み込みの非決定論的関数の呼び出しは、クエリと参照ごとに1回評価されると言ったことを思い出してください。これは、バッチ1では2つの異なる評価があり、ループを十分に繰り返した後、異なる値になることを意味します。それを試してみてください。コードは何回の反復を報告しましたか?
バッチ2の場合、コードには同じCTEインスタンスからのdt列への2つの参照があります。つまり、両方が同じ関数評価を表し、同じ値を表す必要があります。したがって、バッチ2には無限ループがあります。好きな時間実行しますが、最終的にはコードの実行を停止する必要があります。
バッチ3の場合、外部クエリにはCTE Cと相互作用する2つの異なるサブクエリがあり、それぞれが個別にネスト解除プロセスを通過する異なるインスタンスを表します。 2つのサブクエリは独立したスコープに表示されるため、コードはCTEの異なるインスタンスに異なるエイリアスを明示的に割り当てませんが、理解しやすくするために、1つのサブクエリでC1などの異なるエイリアスを使用していると考えることができます。他のC2。つまり、一方のサブクエリがC1.dtと相互作用し、もう一方のサブクエリがC2.dtと相互作用するかのようです。異なる参照は、基になる式の異なる評価を表すため、異なる値になる可能性があります。コードを実行してみて、ある時点で停止することを確認してください。停止するまでに何回の反復が必要でしたか?
クエリ実行プランの基になる式の単一の評価と複数の評価がある場合を特定してみるのは興味深いことです。図1は、3つのバッチのグラフィカルな実行計画を示しています(クリックして拡大)。
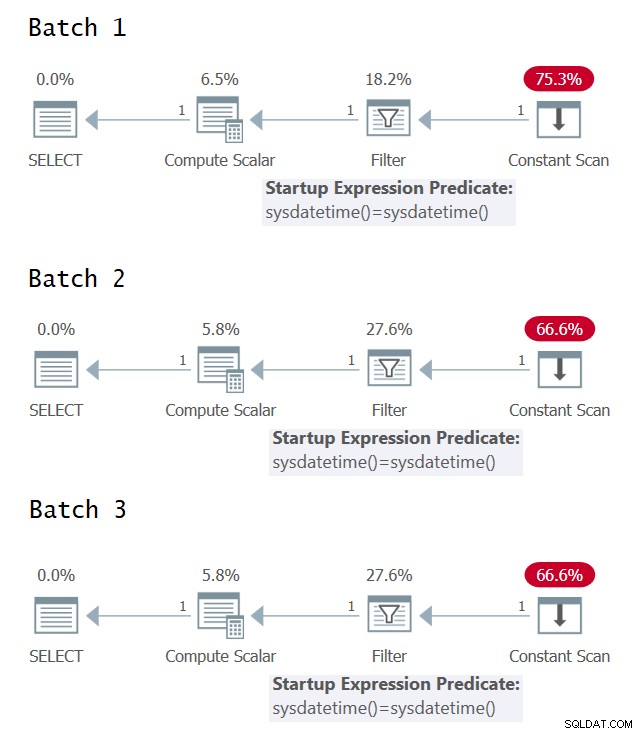 図1:バッチ1、バッチ2、およびバッチ3のグラフィカルな実行計画
図1:バッチ1、バッチ2、およびバッチ3のグラフィカルな実行計画
残念ながら、グラフィカルな実行計画には喜びがありません。意味的には、3つのバッチが同じ意味を持っていなくても、それらはすべて同じように見えます。 @CodeRecceとForrest(@tsqladdict)のおかげで、コミュニティとして、他の方法でこの問題を解決することができました。
@CodeRecceが発見したように、XML計画がその答えを保持しています。 3つのバッチのXMLの関連部分は次のとおりです。
-バッチ1
<述語>
…
…
-バッチ2
<述語>
…
<識別子>
<識別子>
…
-バッチ3
<述語>
…
<識別子>
<識別子>
…
バッチ1のXMLプランで、フィルター述語が組み込みのSYSDATETIME関数の2つの別々の直接呼び出しの結果を比較していることがはっきりとわかります。
バッチ2のXMLプランでは、フィルター述部は、SYSDATETIME関数の1回の呼び出しを表す定数式ConstExpr1002をそれ自体と比較します。
バッチ3のXMLプランでは、フィルター述部はConstExpr1005およびConstExpr1006と呼ばれる2つの異なる定数式を比較し、それぞれがSYSDATETIME関数の個別の呼び出しを表します。
別のオプションとして、Forrest(@tsqladdict)は、トレースフラグ3604を有効にした後、SQLServerによって作成された初期クエリツリー表現を示すトレースフラグ8605を使用することを提案しました。次のコードを使用して、両方のトレースフラグを有効にします。
DBCC TRACEON(3604); -- direct output to client GO DBCC TRACEON(8605); -- show initial query tree GO
次に、クエリツリーを取得するコードを実行します。 3つのバッチについてTF8605から取得した出力の関連部分は次のとおりです。
-バッチ1
***変換されたツリー:***
LogOp_Project COL:Expr1000
LogOp_Select
LogOp_ConstTableGet(1)[空]
ScaOp_Comp x_cmpEq
ScaOp_Intrinsic sysdatetime
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int、ML =4)XVAR(int、Not Owned、Value =1)
-バッチ2
***変換されたツリー:***
LogOp_Project COL:Expr1001
LogOp_Select
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet(1)[空]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
ScaOp_Comp x_cmpEq
ScaOp_Identifier COL:Expr1000
ScaOp_Identifier COL:Expr1000
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int、ML =4)XVAR(int、Not Owned、Value =1)
-バッチ3
***変換されたツリー:***
LogOp_Project COL:Expr1004
LogOp_Select
LogOp_ConstTableGet(1)[空]
ScaOp_Comp x_cmpEq
ScaOp_Subquery COL:Expr1001
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet(1)[空]
AncOp_PrjList
AncOp_PrjEl COL:Expr1000
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1001
ScaOp_Identifier COL:Expr1000
ScaOp_Subquery COL:Expr1003
LogOp_Project
LogOp_ViewAnchor
LogOp_Project
LogOp_ConstTableGet(1)[空]
AncOp_PrjList
AncOp_PrjEl COL:Expr1002
ScaOp_Intrinsic sysdatetime
AncOp_PrjList
AncOp_PrjEl COL:Expr1003
ScaOp_Identifier COL:Expr1002
AncOp_PrjList
AncOp_PrjEl COL:Expr1004
ScaOp_Arithmetic x_aopAdd
ScaOp_Identifier COL:@i
ScaOp_Const TI(int、ML =4)XVAR(int、Not Owned、Value =1)
バッチ1では、組み込み関数SYSDATETIMEの2つの別々の評価の結果の比較を見ることができます。
バッチ2では、関数の1つの評価がExpr1000という列になり、次にこの列とそれ自体の比較が表示されます。
バッチ3では、関数の2つの別々の評価が表示されます。 Expr1000と呼ばれる列に1つ(後でExpr1001と呼ばれるサブクエリ列によって投影されます)。 Expr1002と呼ばれる別の列(後でExpr1003と呼ばれるサブクエリ列によって投影されます)。次に、Expr1001とExpr1003を比較します。
したがって、グラフィカル実行プランが公開するものを少し掘り下げることで、基になる式が1回だけ評価されるのか、複数回評価されるのかを実際に把握できます。さまざまなケースを理解したので、目的の動作に基づいてソリューションを開発できます。
非決定論的な順序のウィンドウ関数
同じCTEへの複数の参照があるソリューションで使用すると、問題が発生する可能性のある別のクラスの計算があります。これらは、非決定論的な順序に依存するウィンドウ関数です。例として、ROW_NUMBERウィンドウ関数を取り上げます。 半順序とともに使用する場合 (行を一意に識別しない要素で並べ替える)、基になるクエリを評価するたびに、基になるデータが変更されていなくても、行番号の割り当てが異なる可能性があります。複数のCTE参照がある場合、それぞれが個別にネスト解除され、異なる結果セットが得られる可能性があることに注意してください。外部クエリが各参照で何を行うかに応じて、たとえばオプティマイザーは、各参照のどの列とどのように相互作用するか、さまざまな順序要件を持つさまざまなインデックスを使用して、各インスタンスのデータにアクセスすることを決定できます。
例として次のコードを考えてみましょう。
USE TSQLV5;
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; このクエリは空でない結果セットを返すことができますか?おそらくあなたの最初の反応はそれができないということです。しかし、私が今説明したことをもう少し注意深く考えてみてください。少なくとも理論的には、ここで行われる2つの別々のCTEネスト解除プロセス(C1とC2の1つ)により、それが可能であることがわかります。ただし、何かが起こる可能性があることを理論化することと、それを実証することは別のことです。たとえば、新しいインデックスを作成せずにこのコードを実行すると、空の結果セットが表示され続けました。
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
このクエリについて、図23に示す計画を取得しました。
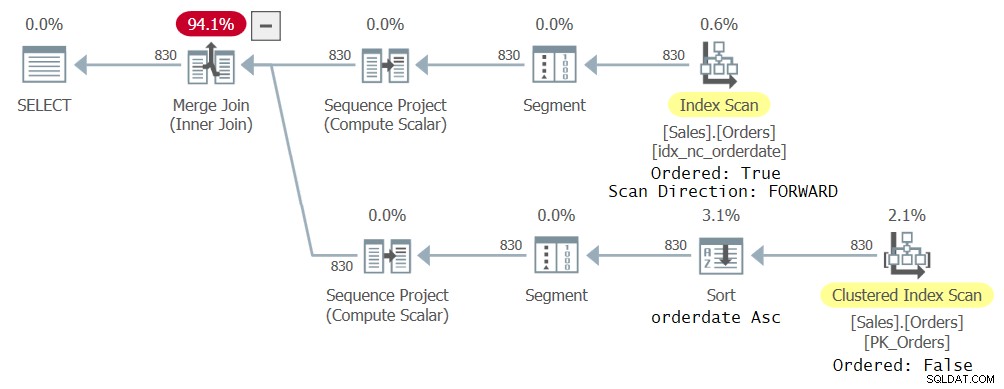 図2:2つのCTE参照を使用したクエリの最初の計画
図2:2つのCTE参照を使用したクエリの最初の計画
ここで注目すべき興味深い点は、オプティマイザーがさまざまなインデックスを使用してさまざまなCTE参照を処理することを選択したことです。これは、オプティマイザーが最適と見なしたためです。結局のところ、外部クエリの各参照は、CTE列の異なるサブセットに関係しています。 1つの参照は、インデックスidx_nc_orderedateの順序付けられた順方向スキャンをもたらし、もう1つは、クラスター化されたインデックスの順序付けられていないスキャンと、それに続くorderdateの昇順によるソート操作をもたらしました。インデックスidx_nc_orderedateは、キーとしてorderdate列でのみ明示的に定義されていますが、orderidはクラスター化されたインデックスキーであり、すべての非クラスター化インデックスの最後のキーとして含まれているため、実際には(orderdate、orderid)でキーとして定義されます。したがって、インデックスの順序付きスキャンは、実際にはorderdate、orderidで順序付けられた行を出力します。クラスタ化されたインデックスの順序付けられていないスキャンに関しては、ストレージエンジンレベルで、データはインデックスキーの順序(orderidに基づく)でスキャンされ、コミットされたデフォルトの分離レベルの最小限の一貫性の期待に対処します。したがって、Sortオペレーターは、orderidで並べ替えられたデータを取り込み、orderdateで行を並べ替え、実際には、orderdate、orderidで並べ替えられた行を出力することになります。
繰り返しになりますが、理論的には、基になるデータが変更されていない場合でも、2つの参照が常に同じ結果セットを表すという保証はありません。これを示す簡単な方法は、2つの参照に対して2つの異なる最適なインデックスを配置することですが、一方はデータをorderdate ASC、orderid ASCで並べ替え、もう一方はデータをorderdate DESC、orderid ASC(または正反対)で並べ替えます。以前のインデックスはすでに用意されています。後者を作成するためのコードは次のとおりです。
CREATE INDEX idx_nc_odD_oid_I_sc ON Sales.Orders(orderdate DESC, orderid) INCLUDE(shipcountry);
インデックスを作成した後、コードをもう一度実行します:
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; 新しいインデックスを作成した後にこのコードを実行すると、次の出力が得られました。
orderid shipcountry orderid ----------- --------------- ----------- 10251 France 10250 10250 Brazil 10251 10261 Brazil 10260 10260 Germany 10261 10271 USA 10270 ... 11070 Germany 11073 11077 USA 11074 11076 France 11075 11075 Switzerland 11076 11074 Denmark 11077 (546 rows affected)
おっと。
図3に示すように、この実行のクエリプランを調べます。
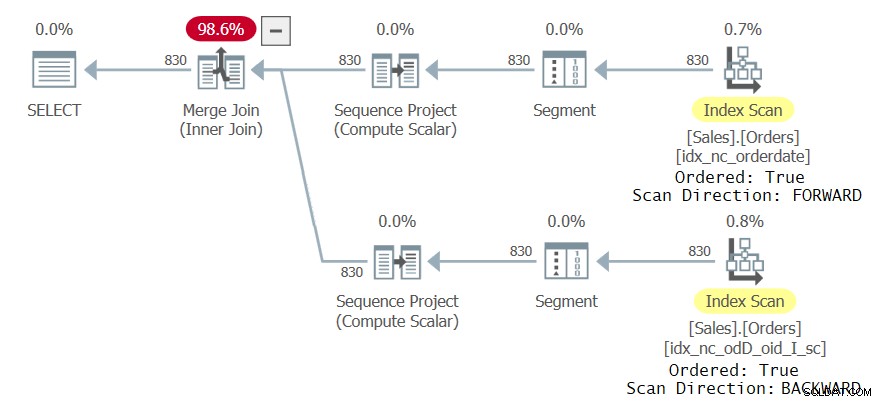 図3:2つのCTE参照を使用したクエリの2番目の計画
図3:2つのCTE参照を使用したクエリの2番目の計画
プランの最上位ブランチがインデックスidx_nc_orderdateを順方向にスキャンし、行番号を計算するシーケンスプロジェクトオペレーターが実際にorderdate ASC、orderidASCで順序付けられたデータを取り込むことに注意してください。プランの一番下のブランチは、新しいインデックスidx_nc_odD_oid_I_scを逆方向にスキャンし、Sequence Projectオペレーターが、実際にはorderdate ASC、orderidDESCで順序付けられたデータを取り込むようにします。これにより、同じorderdate値が複数回出現する場合は常に、2つのCTE参照の行番号の配置が異なります。その結果、クエリは空でない結果セットを生成します。
このようなバグを回避したい場合、明らかなオプションの1つは、内部クエリの結果を一時テーブルやテーブル変数などの一時オブジェクトに永続化することです。ただし、CTEの使用に固執したい場合は、タイブレーカーを追加してウィンドウ関数で全順序を使用するのが簡単な解決策です。つまり、行を一意に識別する式の組み合わせで並べ替えることを確認してください。この場合、次のように、タイブレーカーとしてorderidを明示的に追加できます。
WITH C AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY orderdate, orderid) AS rownum
FROM Sales.Orders
)
SELECT C1.orderid, C1.shipcountry, C2.orderid
FROM C AS C1
INNER JOIN C AS C2
ON C1.rownum = C2.rownum
WHERE C1.orderid <> C2.orderid; 期待どおりに空の結果セットが表示されます:
orderid shipcountry orderid ----------- --------------- ----------- (0 rows affected)
さらにインデックスを追加しなくても、図4に示す計画が得られます。
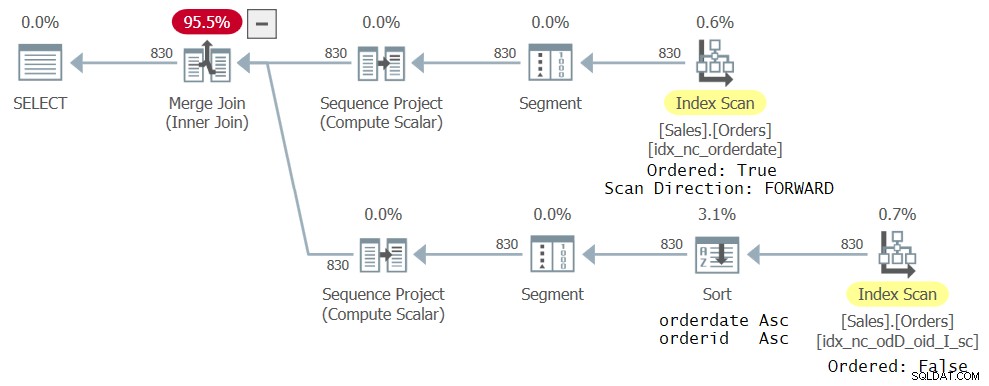 図4:2つのCTE参照を使用したクエリの3番目の計画
図4:2つのCTE参照を使用したクエリの3番目の計画
プランの上のブランチは、図3に示されている前のプランと同じですが、下のブランチは少し異なります。以前に作成された新しいインデックスは、ROW_NUMBER関数が必要とするデータ(orderdate、orderid)のように順序付けられたデータがないという意味で、新しいクエリにはあまり理想的ではありません。これは、オプティマイザーがそれぞれのCTE参照に対して見つけることができる最も狭いカバーインデックスであるため、選択されます。ただし、Ordered:Falseの方法でスキャンされます。次に、明示的な並べ替え演算子は、ROW_NUMBER計算に必要なorderidであるorderdateによってデータを並べ替えます。もちろん、インデックス定義を変更して、orderdateとorderidの両方が同じ方向を使用するようにすることができます。これにより、明示的な並べ替えが計画から削除されます。ただし、重要な点は、完全な順序付けを使用することで、この特定のバグによるトラブルに巻き込まれないようにすることです。
完了したら、クリーンアップのために次のコードを実行します。
DROP INDEX IF EXISTS idx_nc_odD_oid_I_sc ON Sales.Orders;
結論
外部クエリから同じCTEを複数回参照すると、CTEの内部クエリが個別に評価されることを理解することが重要です。評価が異なると値も異なる可能性があるため、非決定論的な計算には特に注意してください。
ROW_NUMBERのようなウィンドウ関数を使用し、フレームで集計する場合は、異なるCTE参照で同じ行に対して異なる結果が得られないように、必ず全順序を使用してください。