さて、SARS-CoV-2コロナウイルスの蔓延を分析することは私の夢のユースケースではありませんでした 。しかし、FerryDjajaのTrackingCoronavirus COVID-19 Near Real Time with SAP HANA XSAの記事への回答に基づいて、2つのグロジーも追加することにしました。
[20-03-30に更新 ソースデータへのリンクが変更されました。新しいデータの粒度に基づいた新しいマップ出力。コメントをありがとうダグラスモルトビー!]
Ferryはブログ投稿で、SAP HANA XSAのJavaScriptを使用して、ジョンズホプキンス大学が毎日更新するCSVファイルからデータを取得しました。
ほんの数行のコードを使用して、これらのファイルをSAPHANAにプルしてロードする方法を紹介します。 機械学習用のSAPHANAPythonクライアントAPI(hana_ml)に感謝します パッケージ)。
一部の人々は、最後の地図での視覚化と混同していました。この記事は、コロナウイルスデータの詳細な分析ではなく、さまざまなコンポーネントを接続する技術的なユースケースに焦点を当てていることに注意してください。
Python環境を取得します。例: Jupyter
そのために、DockerコンテナでJupyterを使用します。私の以前の投稿「コンテナについて(パート05)」をご覧ください:起動方法に慣れていない場合は、ホストとコンテナ間で共有されるファイル。同様に、他のPython環境から以下のすべての同じ手順を実行できます。
だから、私は私のコンテナmyjupyter01を持っています ランニング。前のブログで説明したように、JupyterUIに接続しています。
hana_mlをインストールします
Docker Hubレジストリから使用したJupyterイメージは、jupyter/minimal-notebookでした。 。 pandasなどの人気のあるデータ処理パッケージがすでに含まれています 。
ただし、さらに、hana_mlをインストールする必要があります 、これは—現在のバージョン1.0.8では— PyPIリポジトリで入手できます:https://pypi.org/project/hana-ml/。
インストールを実行するコマンドは、python -m pip install hana_mlです。 、ただし、Python3カーネルを使用してJupyterノートブックから実行しているため、!を使用して実行する必要があります。 最初に:
!python -m pip install hana_ml
明らかに、このインストール手順は1回だけ実行する必要があります。同じコンテナで再実行する必要はありません。最新のファイルをリロードするとき。
pandasを使用する データを含むファイルをインポートするには
同じ3つのファイルをインポートしましょう(confirmed 、deaths 、recovered )https://github.com/CSSEGISandData/COVID-19/tree/master/csse_covid_19_data/csse_covid_19_time_seriesから、フェリーが彼の例で使用したように。
import hana_ml, pandas
# Links updated on 2020-03-22
df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_confirmed_global.csv')
df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_deaths_global.csv')
df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_covid19_recovered_global.csv')
#Links from before March 22nd
#df_confd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Confirmed.csv')
#df_death = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Deaths.csv')
#df_recvd = pandas.read_csv('https://raw.githubusercontent.com/CSSEGISandData/COVID-19/master/csse_covid_19_data/csse_covid_19_time_series/time_series_19-covid-Recovered.csv')
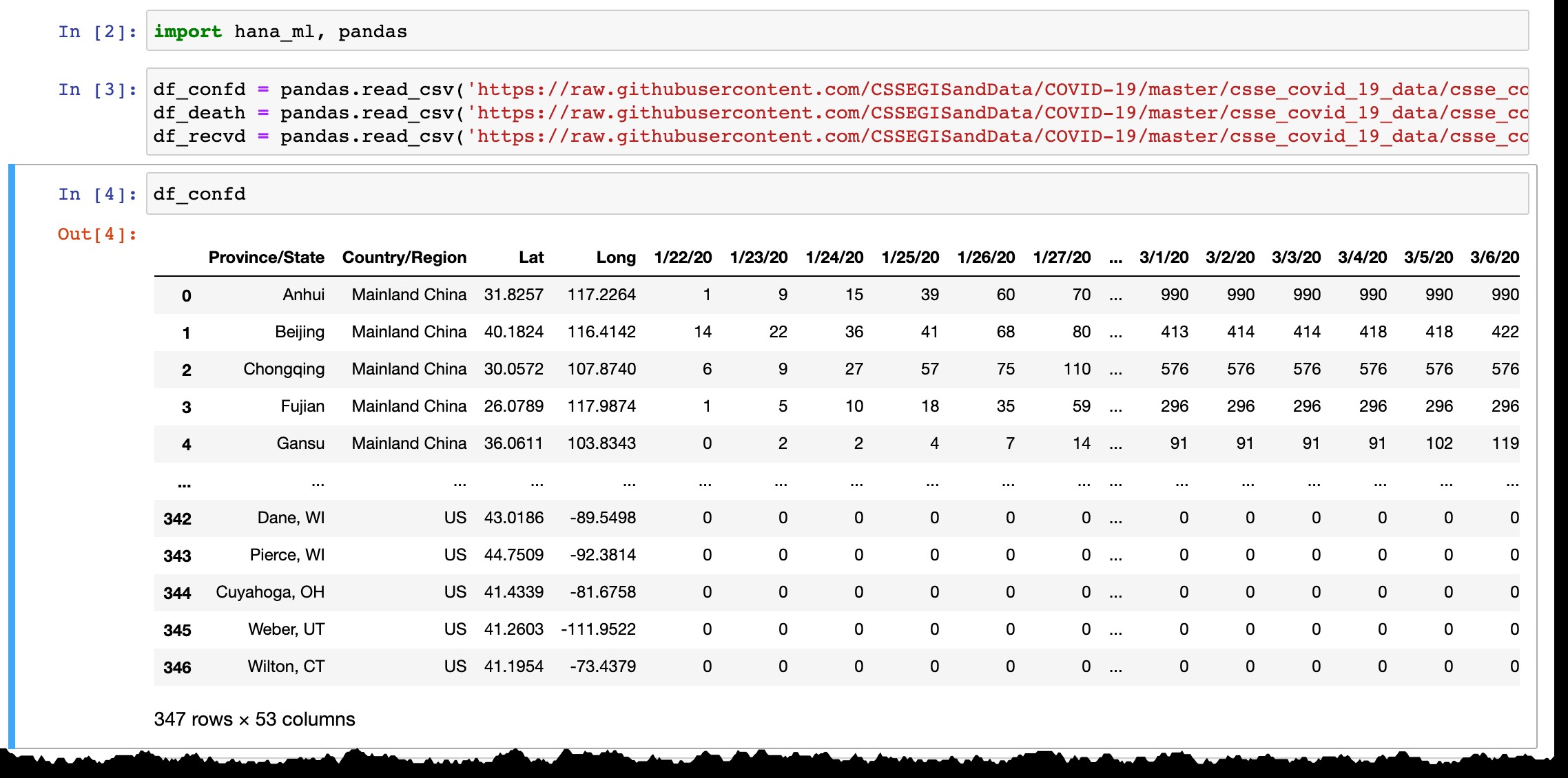
Pandasデータフレームのプレビューからわかるように、確認されたケースがある国または州のみが一覧表示され、毎日新しい列に前日の最新データが追加されます。新しい地域で最初のケースが確認されると、行が追加されます。
pandasを使用する データフレームを再フォーマットするには
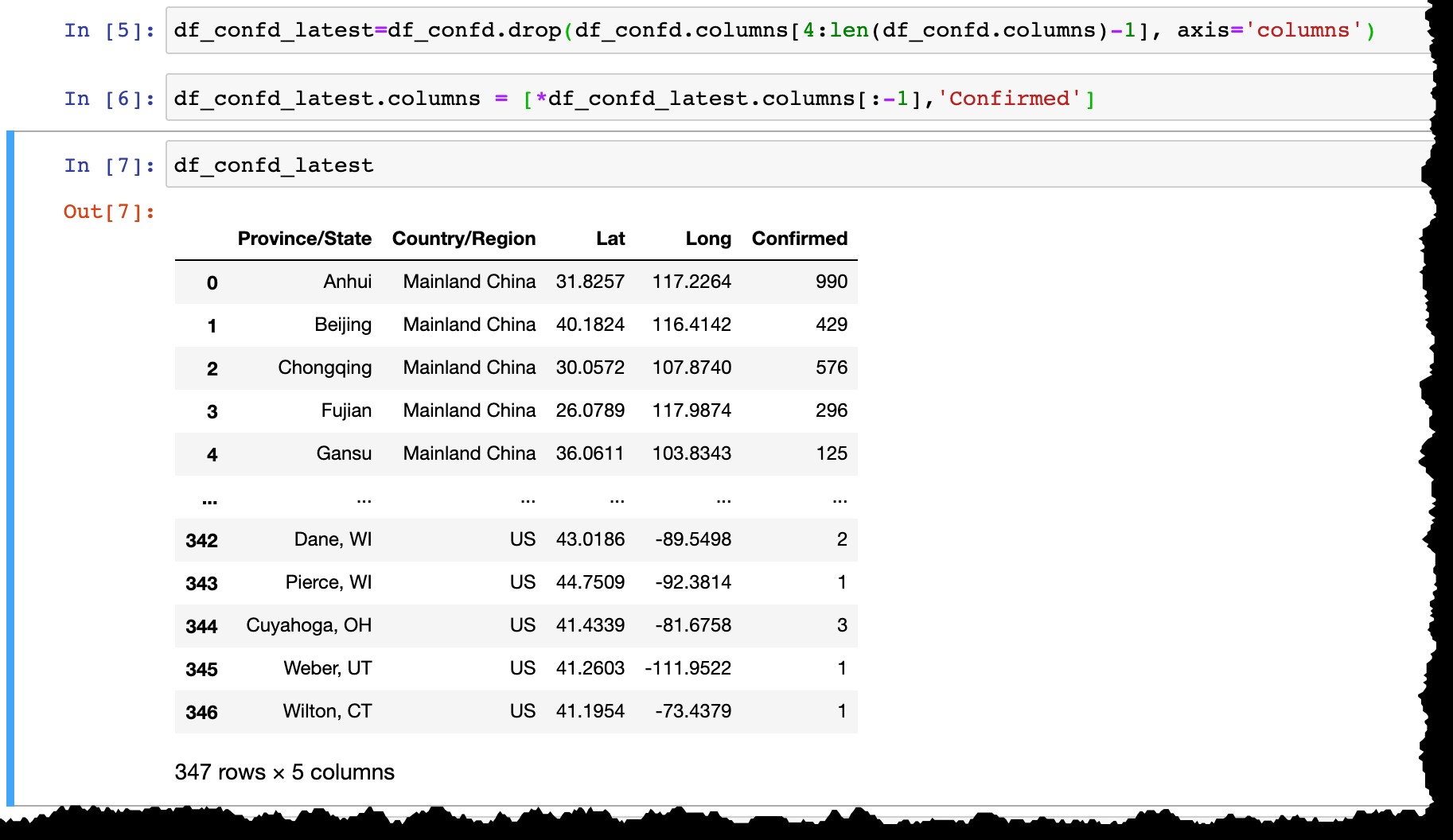
SAP HANAでデータを永続化する前に、次のことを行います。
- 最後の列を除くすべての日付列を削除します
- 実際の日付から最後の列の名前を変更します(今日の
3/10/20のように)confirmedへ 。
df_confd_latest=df_confd.drop(df_confd.columns[4:len(df_confd.columns)-1], axis='columns')
df_confd_latest.columns = [*df_confd_latest.columns[:-1],'Confirmed']
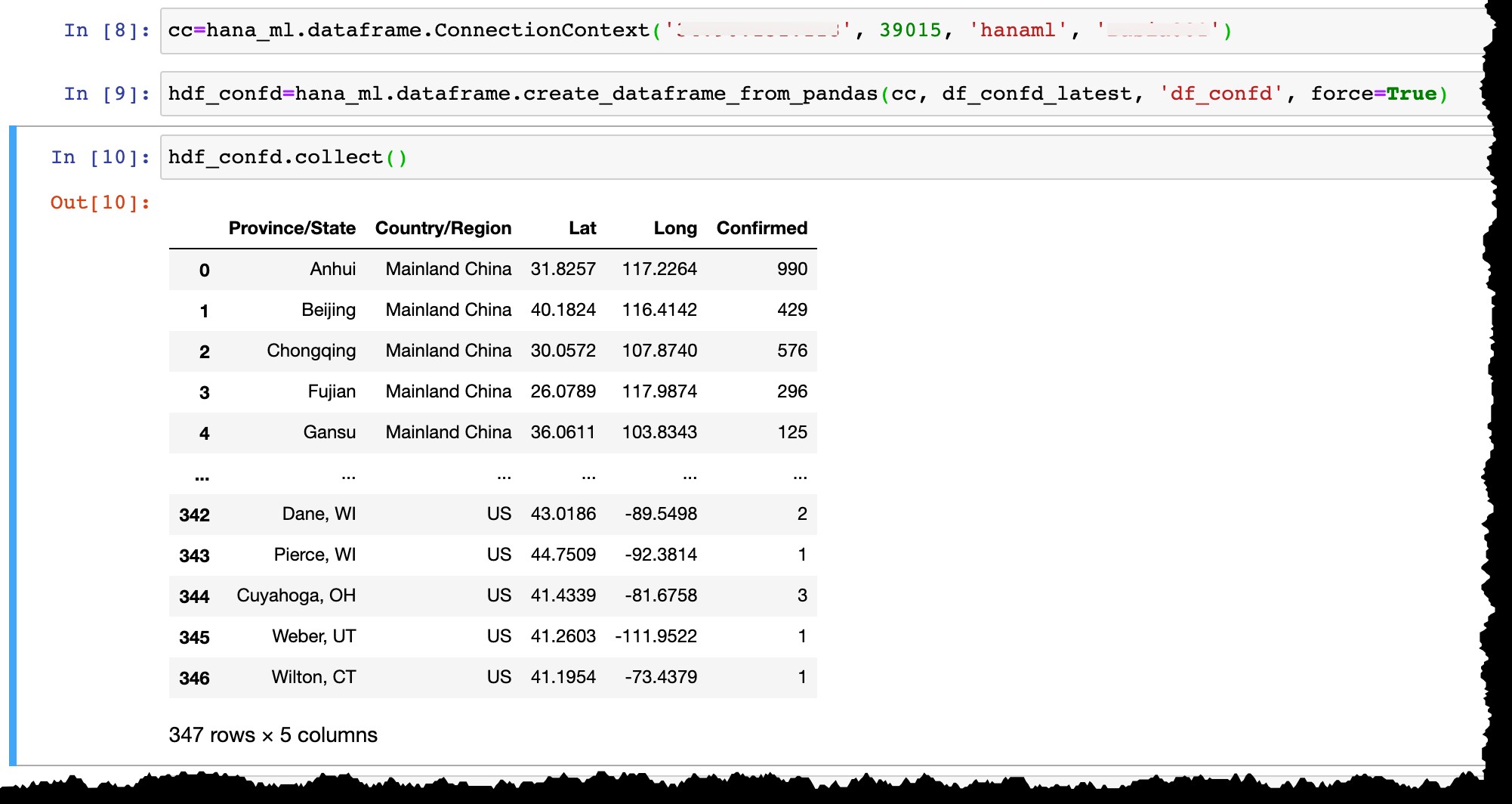
hana_mlを使用する SAPHANAテーブルにデータを永続化する
次に、ユーザーhanamlを使用してSAPHANAExpressのインスタンスに接続します。 すでにそこに存在しています…
cc=hana_ml.dataframe.ConnectionContext('12.34.567.890', 39015, 'hanaml', 'MyPasswordReusedEverywhere')
…そしてPandasデータフレームを変換しますdf_confd_latest HANAデータフレームにhdf_confd 。
hdf_confd=hana_ml.dataframe.create_dataframe_from_pandas(cc, df_confd_latest, 'df_confd', force=True)
HANAデータフレームが作成されたら:
- 物理列テーブルがHANAで作成され、Pandasデータフレームからのデータがそこに挿入されます。
- HANAデータフレーム
hdf_confdPythonでは、ラップトップにデータを保存せず、テーブルHANAML.df_confdのみを指します。 SAP HANAサーバーメモリ内で、HANAデータフレーム上のすべてのPython操作は、サーバーとクライアント間でデータを移動することなく、HANAデータベースで物理的に期待されます。 - 操作の結果を表示するには、
collect()を適用する必要があります HANAデータフレームをPandasに変換する方法(およびその結果、HANAデータベースサーバーからローカルクライアントにデータを取り込む方法)。
DBeaverを使用してSAPHANAのデータを確認します…
以前の投稿「GeoArtwithSAPHANA and DBeaver」で、SAPHANAをサポートする無料のデータベースツールであるDBeaverをすでに使用していることを覚えているかもしれません。
私は今それを再び使用しています、そして確かに私はテーブルdf_confdを見つけることができます スキーマ内HANAML ソースのPandasデータフレームからのすべてのデータを使用します。
…そして空間プレビューを行う
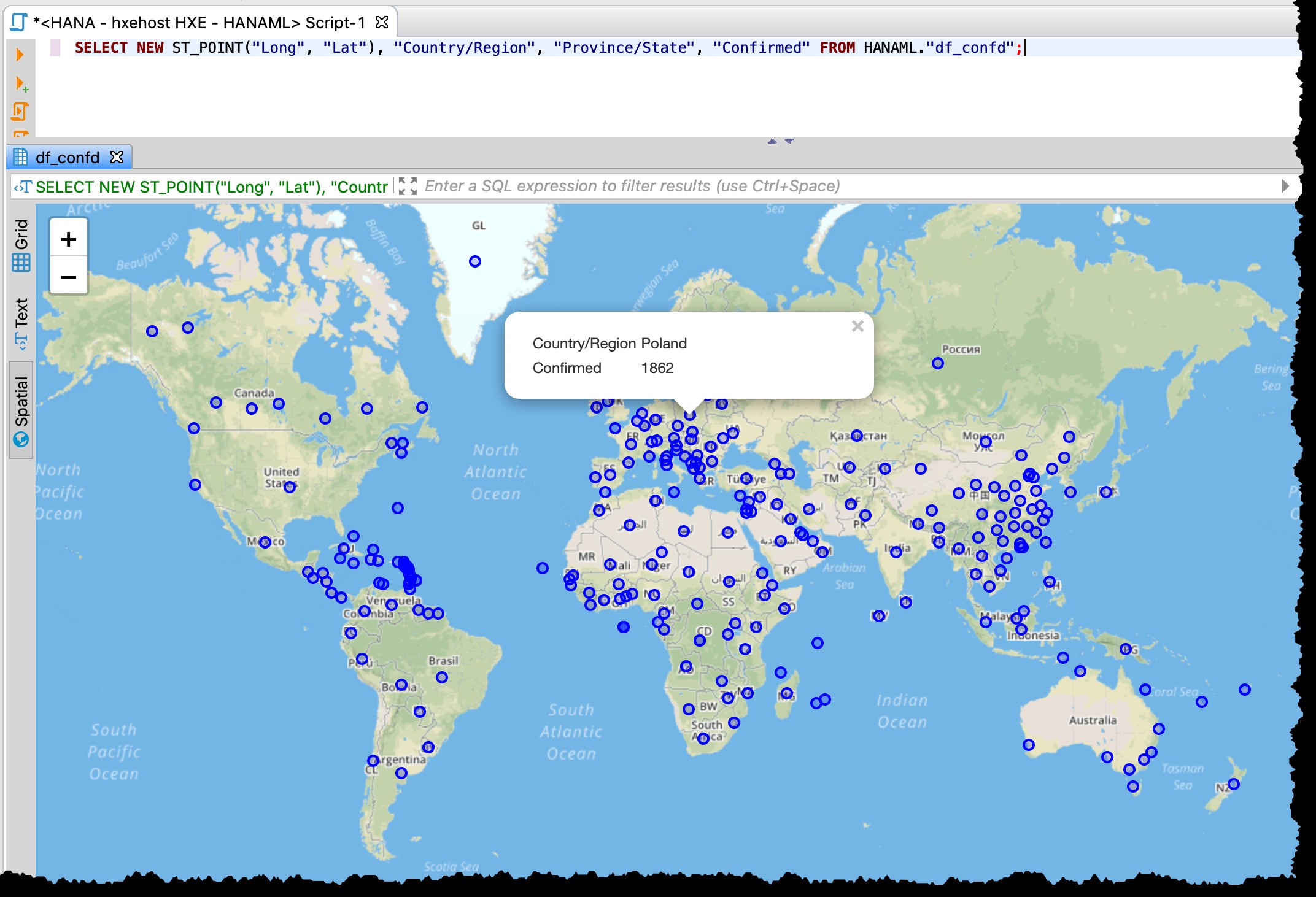
表には緯度と経度の列が含まれているため、空間データプレビューを使用して次のSQLを使用し、影響を受ける国/州をDBeaverから直接視覚化できます。
SELECT NEW ST_POINT("Long", "Lat"), "Country/Region", "Province/State", "Confirmed" FROM HANAML."df_confd";
地図投影法をEPSG:4326に変更する必要がありました マップ上でこれらのポイントを取得します。また、DBeaverは、任意のポイントをクリックすると、残りのレコードデータを表示します。
[以下 2020-03-11の古いスクリーンショットです。これは、たとえば、当時使用されていた米国のデータ]
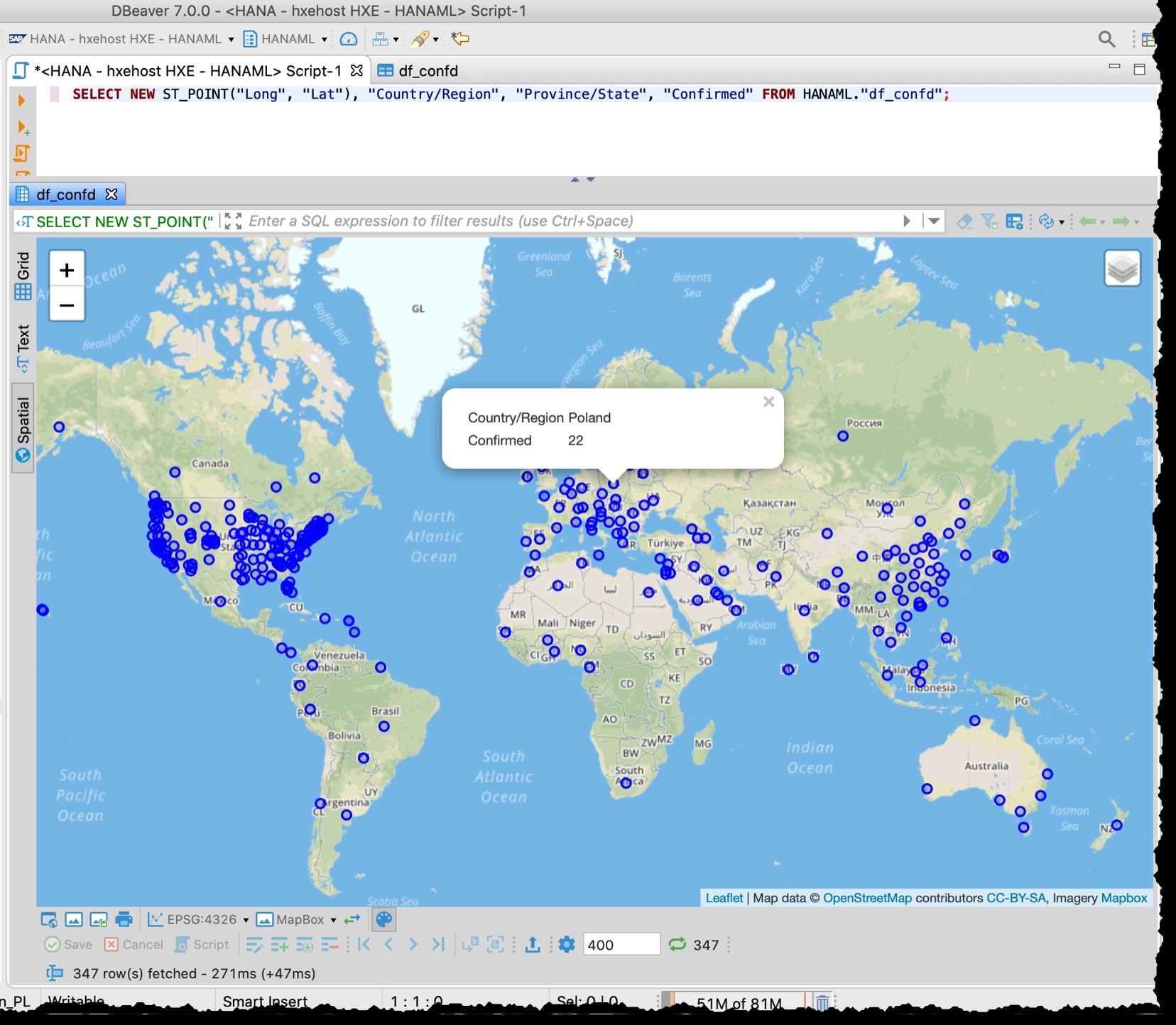
DBeaver空間プレビューは、本格的な地理空間視覚探索ツールではありません。それでも、影響を受ける国/地域を確認するだけで十分です(ソースファイルの粒度によって異なります)。
hana_mlについて詳しく知りたい場合 …
…次に、AndreasForsterによるPythonを使用したSAPHANAへのハンズオンチュートリアル:機械学習のプッシュダウンを確認することを強くお勧めします。
HANA MLは、CodeJamイベントの新しい「SAPHANAを使用した高度な分析」トピックの一部です。残念ながら、コロナウイルスの状況のため、今月ベルンでJakobFlamanが主催した最初のコロナウイルスをキャンセルしなければなりませんでした。もう1つは、5月27日にカトヴィツェでEwelinaPękałaによって開催されます:https://www.eventbrite.com/e/sap-codejam-katowice-registration-99016299417。うまくいけば、その時までに状況は正常になり、これもキャンセルする必要はありません。