
Couchbaseとは
Couchbase Serverは、オープンソースの分散型JSONドキュメントデータベースです。ミリ秒未満のデータ操作用のマネージドキャッシュ、効率的なクエリ用の専用インデクサー、SQLのようなクエリを実行するための強力なクエリエンジンを備えたスケールアウトのKey-Valueストアを公開します。モバイルおよびモノのインターネット環境の場合、Couchbaseはデバイス上でネイティブに実行され、サーバーへの同期を管理します。
なぜCouchbaseなのか
Couchbase Serverは、オープンソースの分散型JSONドキュメントデータベースです。ミリ秒未満のデータ操作用のマネージドキャッシュ、効率的なクエリ用の専用インデクサー、SQLのようなクエリを実行するための強力なクエリエンジンを備えたスケールアウトのKey-Valueストアを公開します。モバイルおよびモノのインターネット環境の場合、Couchbaseはデバイス上でネイティブに実行され、サーバーへの同期を管理します。
Couchbase Serverは、大規模なインタラクティブWeb、モバイル、およびIoTアプリケーションに低遅延のデータ管理を提供することに特化しています。 CouchbaseServerが満たすように設計された一般的な要件は次のとおりです。
- 統合プログラミングインターフェイス
- クエリ
- 検索
- モバイルとIoT
- 分析
- コアデータベースエンジン
- スケールアウトアーキテクチャ
- メモリファーストアーキテクチャ
- ビッグデータとSQLの統合
- フルスタックセキュリティ
- コンテナとクラウドの展開
- 高可用性
多くのデータベースは、これらの要件の1つ以上を満たすことができますが、インターネット規模のミッションクリティカルなアプリケーションを使用して本番環境で実行する場合は、トレードオフが必要です。たとえば、あるソリューションはデータモデルの柔軟性を提供しますが、稼働時間やパフォーマンスに影響を与えることなくノードを追加または削除する機能がない場合があります。別のソリューションは、データモデルのインデックス作成や変更をその場で行うことができなくても、優れた書き込みスケーラビリティを示す可能性があります。 Couchbase Serverは、生産的な開発者と管理エクスペリエンスを提供すると同時に、クラウド、コンテナ、オンプレミス、エッジデバイスのいずれでも大規模なパフォーマンスを提供するように設計されています。
Nosqlパフォーマンスベンチマーク
MongoDB、DataStax、Couchbase Serverを比較する新しいベンチマークは、Couchbaseが最もスケーラブルで最高のパフォーマンスを発揮するNoSQLデータベースであることを示しています。
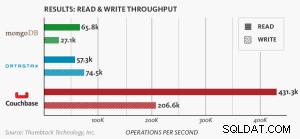
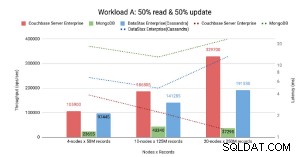
ノードベースのベンチマーク。
CAP定理Couchbaseによる。
キャプチャ定理

CouchbaseはCPとAPの図にあります。
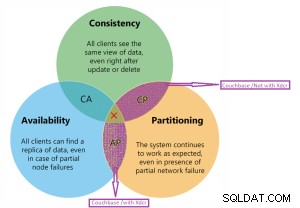
CouchbaseCPおよびAP図の詳細。
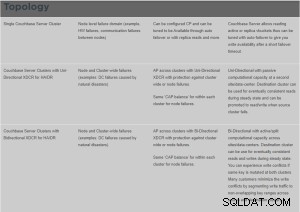
XDCRとは何ですか?
クロスデータセンターレプリケーション(XDCR)は、クラスター間でデータをレプリケートします。これにより、データセンターの障害に対する保護が提供され、グローバルに分散されたミッションクリティカルなアプリケーションに高性能のデータアクセスが提供されます。
XDCRは、ソースクラスターの特定のバケットからターゲットクラスターの特定のバケットにデータを複製します。ソースバケットからのデータは、データベース変更プロトコルを使用して、ソースクラスターで実行されているXDCRエージェントによってターゲットバケットにプッシュされます。任意のクラスター上の任意のバケット(CouchbaseまたはEphemeral)を、1つ以上のXDCR定義のソースまたはターゲットとして指定できます。
XDCRの完全なアーキテクチャの説明は、クロスデータセンターレプリケーション(XDCR)に記載されています。このセクションで提供されるルーチンを実行する前に、そこで提供される情報をよく理解しておくことをお勧めします。
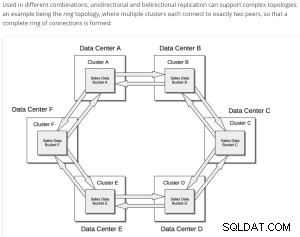
Xdcrの基本構造;
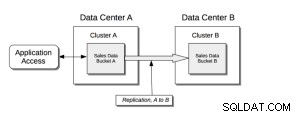
前提条件;
- クラスターのサイズが適切であり、新しいXDCRストリームを処理できることを確認します。たとえば、XDCRはストリームごとに1〜2個の追加のCPUコアを必要とし、場合によっては、より多くのRAMとネットワークリソースも必要になります。クラスタが既存のワークロードと新しいXDCRストリームに対して適切なサイズになっていない場合、XDCRはサーバーリソースを奪い合い、全体的なパフォーマンスに悪影響を与える可能性があります。
- Couchbase Serverは、TCP/IPポート8091を使用してクラスタ構成情報を交換します。専用接続またはインターネットを介して宛先クラスターと通信している場合は、宛先クラスターと送信元クラスターのすべてのノードがポート8091と8092を介して相互に通信できることを確認する必要があります。
| XDCR(クラスター間) |
|
Couchbaseは、データをディスクとRAMの両方に保存します。デフォルトの動作では、RAMに保存した後、任意の時点(通常は迅速)にドキュメントをディスクに書き込みます。これにより、ノードに障害が発生するとデータが失われる可能性がある短いウィンドウが残ります。
いずれにせよ、RAMに書き込んだ後、ドキュメントは最終的にディスクに書き込まれます。 Couchbaseは、管理コンソールのメトリクスレポートページで確認できるディスク書き込みキューを保持しています。現在、CBはクラスター全体で書き込みを同期します。書き込みは、Couchbaseが書き込みが発生したことを確認する前に(たとえば、writeメソッドが呼び出し元に戻る前に)クラスター全体で同期されると思います。
使用可能なRAMよりも多くのドキュメントがある場合、最も頻繁にアクセスされるドキュメントのみがRAMに保存され、すばやく取得できます。他のすべてのドキュメントはディスクに「削除」されます。
アドバイス;
バケットサイズがソースで200GBから10GBに減少すると、レプリケーションは十分に高速になりました。つまり、バケットサイズが大きく、すべてのデータがRAMにある場合、レプリケーションに10秒のギャップがあることがわかりました。
ソースとターゲットは同じLinux設定と同じリソースである必要があります。これは単なるアドバイスです。
製品バケットの常駐は%100である必要があります。複製速度が重要だからです。
Bucket replication best settings ; XDCR Source Nozzles per Node: 2 --> 8 XDCR Target Nozzles per Node: 2 --> 24 (Nozzles=Channel=parallel , as cpu core) XDCR Checkpoint Interval (sn): 1800 --> 60 Control frequency is low, but not as much as waiting in the queue. The higher this value, the longer it takes for XDCR queues to grow. XDCR Batch Count: 500 --> 2000 It is beneficial to increase by 2.3 times. It also sends so many data groups at the same time. XDCR Batch Size (kB): 2048 --> 8192 It is beneficial to increase by 2.3 times. At the same time, it sends such a large amount of data. XDCR Failure Retry Interval: 10 --> 10 It is used for retry attempts in network errors. XDCR Optimistic Replication Threshold: 256 --> 1024 --> 256 --> 128 Increasing or decreasing this value appropriately can speed up replication, collect data above 1 mb and send it in bulk. But collection can be a waste of time and waiting in the queue. This is the compressed document size in bytes. 0 - 2097152 Bytes (20MB). Default is 256 Bytes. XDCR retrieves metadata for documents larger than this size at once before copying the uncompressed document to a destination set. This option improves XDCR latency. XDCR Statistics Collection Interval (ms): 1000 --> 1000 XDCR Logging Level: info --> info
アドバイス;
ソースとターゲットを同じ設定にし、同じリソースを使用することをお勧めします。
これらは、バケット設定、クラスター設定、CPU、メモリ、ディスク品質などです。
Xdcrレプリケーションは単なるデータレプリケーションです。複製する前に、バケットメタデータを作成する必要があります。
必要に応じて、ユーザー、インデックス、ビュー、イベントなどを作成します。
追加情報として;
コミュニティバージョンでxdcrレプリケーションを作成できます。
エンタープライズバージョンでxdcrレプリケーションを作成できます。これには追加のライセンスが必要です。スタンバイを製品として使用しない場合、高額な料金ではありません。
XDCR用のCouchbaseの他のコネクタ。 Elasticsearch、Hadoop、Kafka、Spark、Talend、SQL(ODBC / JDBC)
Couchbaseの管理は、WEB UI、REST API、およびCLIを介して実行できます。特に、Webユーザーインターフェイスは非常にシンプルで簡単に使用できます。ユーザーインターフェースを介して、多くの操作トランザクションとクエリを実行できます。
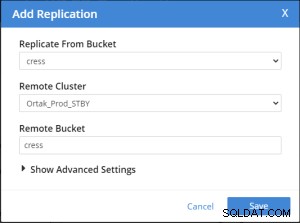
Replication Summary; Stby=Xdcr=Target=Remote same term. A different name xdcr cluster is established with the same features. The buckets with the same name with the same features are created in the xdcr cluster. In Prod, add remote server and xdcr information are entered in the xdcr tab. Prod in xdcr tab with add remote cluster; Cluster Name= Xdcr couchbase name IP/Hostname= Xdcr ip / hostname Username=Xdcr Admin username Password=Xdcr Admin user password Prod in xdcr tab with add bucket replication; Replicate From Bucket = Bucket name in the prod Remote Cluster = Added Xdcr name Remote Bucket = Bucket name added in Xdcr
Xdcrクラスタ設定のメモリ設定は、サーバーのメモリ値に従って指定されます。
サーバーメモリ用に空きサイズにする必要があります。
Xdcrはprodクラスターに追加のメモリを必要とします。
複数のcouchbaseバケットレプリケーションが可能です。
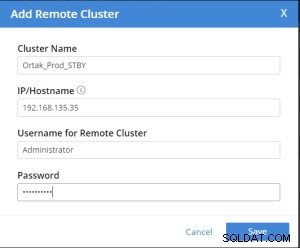
XDCRレプリケーションの簡単な操作の例;
couchbaseホームページで選択されたXdcrタブ。

選択した[xdcr]タブで[リモートクラスターの追加]タブが選択されています。

リモートクラスターの追加操作は次のように実行されます。
選択したxdcrタブで[レプリケーションの追加]タブが選択されています。
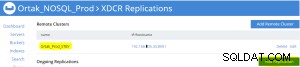
バケットレプリケーションの追加操作は次のように実行されます。
xdcrパフォーマンスに最適なパラメータ。ただし、システムに合わせて再設定できます。

ソース(製品)のxdcrタブのレプリケーションステータス
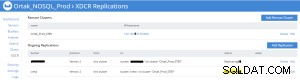
バケット複製統計
目標のレプリケーションパフォーマンス;

ソースでのレプリケーションパフォーマンス;

参考資料;
1-)https://resources.couchbase.com/nosql_comparison_web/altoros-nosql-performance-benchmark
2-)https://docs.couchbase.com/
3-)https://www.businesswire.com/news/home/20140625005778/en/Couchbase-Blows-Past-Competition-in-NoSQL-Performance-Benchmark
4-)https://www.quora.com/What-is-the-relation-between-SQL-NoSQL-the-CAP-theorem-and-ACID
FatihGençali–Couchbase認定

