データベースを処理および管理する際の最大の懸念事項の1つは、データとサイズの複雑さです。多くの場合、データベース管理が失敗するため、組織は成長に対処し、成長の影響を管理する方法について懸念を抱きます。複雑さには、当初は対処されておらず、見られなかった、または現在使用されているテクノロジーがそれ自体で処理できるために見落とされる可能性のある懸念が伴います。複雑で大規模なデータベースの管理は、それに応じて計画する必要があります。特に、管理または処理しているデータの種類が、予想または予測できない方法で大幅に増加すると予想される場合はそうです。計画の主な目標は、不要な災害を回避することです。それとも、煙が立ち上がらないようにすることです。このブログでは、大規模なデータベースを効率的に管理する方法について説明します。
データベースのサイズは、パフォーマンスとその管理方法に影響を与えるため、重要です。データがどのように処理および保存されるかは、データベースの管理方法に影響します。これは、転送中のデータと保存中のデータの両方に適用されます。多くの大規模な組織にとって、データは金であり、データの増加はプロセスに劇的な変化をもたらす可能性があります。したがって、データベース内の増大するデータを処理するための事前の計画を立てることが重要です。
データベースを使用した私の経験では、パフォーマンスの低下に対処し、極端なデータ増加を管理する際に顧客が問題を抱えているのを目撃しました。テーブルを正規化するのか、テーブルを非正規化するのかという疑問が生じます。
テーブルを正規化すると、データの整合性が維持され、冗長性が低下し、データを管理、分析、および抽出するためのより効率的な方法に簡単に整理できます。正規化されたテーブルを操作すると、特にSQLステートメントによってデータフローを分析してデータを取得する場合や、MySQLコネクタを使用するC / C ++、Java、Go、Ruby、PHP、Pythonインターフェースなどのプログラミング言語を操作する場合に効率が向上します。
正規化されたテーブルに関する懸念にはパフォーマンスの低下があり、データを取得する際の一連の結合によりクエリが遅くなる可能性があります。非正規化されたテーブルに対して、最適化のために考慮する必要があるのは、複数のディスクシークを実行するよりも迅速に取得できるように、データをバッファーに格納するためのインデックスまたは主キーに依存することです。非正規化されたテーブルは結合を必要としませんが、データの整合性が犠牲になり、データベースのサイズがどんどん大きくなる傾向があります。
データベースが大きい場合は、MySQL / MariaDBのデータベーステーブルにDDL(データ定義言語)を使用することを検討してください。テーブルに主キーまたは一意キーを追加するには、テーブルを再構築する必要があります。適用できるアルゴリズムはALGORITHM=COPYのみであるため、列のデータ型を変更するには、テーブルの再構築も必要です。
本番環境でこれを行う場合、困難な場合があります。テーブルが巨大な場合は、チャレンジを2倍にします。百万または十億の行数を想像してみてください。 ALTERTABLEステートメントをテーブルに直接適用することはできません。これにより、現在DDLを適用しているテーブルにアクセスする必要があるすべての着信トラフィックをブロックできます。ただし、これはpt-online-schema-changeまたはgreatgh-ostを使用することで軽減できます。それでも、DDLのプロセスを実行している間は、監視と保守が必要です。
シャーディングとパーティショニングにより、論理的なアイデンティティに従ってデータを分離またはセグメント化するのに役立ちます。たとえば、日付、アルファベット順、国、州、または指定された範囲に基づく主キーに基づいて分離することによって。これにより、データベースのサイズを管理しやすくなります。データベースのサイズを、組織やチームが管理できる限界まで維持します。特に災害が発生した場合は、必要に応じて簡単に拡張でき、管理も簡単です。
管理可能と言うときは、サーバーとエンジニアリングチームの容量リソースも考慮してください。少数のエンジニアで大規模なデータを処理することはできません。多数のデータセットを含む1000個のデータベースなどのビッグデータを処理するには、膨大な時間が必要です。スキルと専門知識は必須です。コストが問題になる場合は、マネージドサービスを提供するサードパーティのサービスを活用したり、そのようなエンジニアリング作業を提供するための有償のコンサルティングやサポートを利用したりできます。
文字セットと照合は、特に選択した特定の文字セットと照合で、データの保存とパフォーマンスに影響します。各文字セットと照合には目的があり、ほとんどの場合、異なる長さが必要です。文字エンコードのために他の文字セットと照合を必要とするテーブルがある場合、データベースとテーブル、または列を使用してデータを保存および処理する必要があります。
これは、データベースを効果的に管理する方法に影響します。前述のように、データストレージとパフォーマンスに影響を与えます。アプリケーションで処理される文字の種類を理解している場合は、使用される文字セットと照合に注意してください。 LATINタイプの文字セットは、格納および処理される英数字タイプの文字に主に十分です。
それが避けられない場合、シャーディングとパーティショニングは、データベースサーバー内のデータの肥大化を回避するために、少なくともデータを軽減および制限するのに役立ちます。単一のデータベースサーバーで非常に大きなデータを管理すると、特にバックアップ目的、障害とリカバリ、またはデータの破損やデータの損失が発生した場合のデータリカバリの効率に影響を与える可能性があります。
大規模で複雑なデータベースは、パフォーマンスの低下という点で要因となる傾向があります。この場合、複雑とは、データベースのコンテンツが数式、座標、または数値と財務の記録で構成されていることを意味します。次に、これらのレコードを、データベースに固有の数学関数を積極的に使用しているクエリと混合しました。以下のSQL(MySQL / MariaDB互換)クエリの例をご覧ください。
SELECT
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) a,
ATAN2( PI(),
SQRT(
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) -
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) -
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) b,
ATAN2( PI(),
SQRT(
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`) *
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) /
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`)
)
) c
FROM
a
LEFT JOIN `a`.`pk`=`b`.`pk`
LEFT JOIN `a`.`pk`=`c`.`pk`
WHERE
((`a`.`col1` * `c`.`col1` + `a`.`col1` * `b`.`col1`)/ (`a`.`col2`))
between 0 and 100
AND
SQRT(((
(0 + (
(((`a`.`col3` * `a`.`col4` + `b`.`col3` * `b`.`col4` + `c`.`col3` + `c`.`col4`)-(PI()))/(`a`.`col2`)) *
`b`.`col2`)) -
`c`.`col2) *
((0 + (
((( `a`.`col5`* `b`.`col3`+ `b`.`col4` * `b`.`col5` + `c`.`col2` `c`.`col3`)-(0))/( `c`.`col5`)) *
`b`.`col3`)) -
`a`.`col5`)) +
((
(0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * PI() + `c`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `b`.`col5`)) -
`b`.`col5` ) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `c`.`col2` + `b`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * -20.90625)) - `b`.`col5`)) +
(((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2` +`a`.`col2` / `c`.`col3`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`) *
((0 + (((( `a`.`col5`* `b`.`col3` + `b`.`col5` * `b`.`col2`5 + `c`.`col3` / `c`.`col2`)-(0))/( `c`.`col5`)) * `c`.`col3`)) - `b`.`col5`
))) <=600
ORDER BY
ATAN2( PI(),
SQRT(
pow(`a`.`col1`-`a`.`col2`,`a`.`powcol`) +
pow(`b`.`col1`-`b`.`col2`,`b`.`powcol`) +
pow(`c`.`col1`-`c`.`col2`,`c`.`powcol`)
)
) DESC
複雑さを処理する場合、より効率的な方法は、複雑な数式の厳密な使用や、この組み込みの複雑な計算機能の積極的な使用を避けることです。これは、データベースを使用する代わりに、バックエンドプログラミング言語を使用して複雑な計算を介して操作および転送できます。複雑な計算がある場合は、これらの方程式をデータベースに保存し、クエリを取得して、必要に応じて分析またはデバッグしやすいように整理してください。
適切なデータベースエンジンを使用していますか?
データ構造は、指定されたクエリとテーブルから読み取られた、またはテーブルから取得されたレコードの組み合わせに基づいて、データベースサーバーのパフォーマンスに影響を与えます。 MySQL / MariaDB内のデータベースエンジンはBツリーを使用するInnoDBとMyISAMをサポートしますが、NDBまたはメモリデータベースエンジンはハッシュマッピングを使用します。これらのデータ構造には漸近表記があり、後者はこれらのデータ構造で使用されるアルゴリズムのパフォーマンスを表します。コンピュータサイエンスでは、これらをアルゴリズムのパフォーマンスまたは複雑さを表すBigO表記と呼びます。 InnoDBとMyISAMがBツリーを使用している場合、検索にはO(log n)を使用します。一方、ハッシュテーブルまたはハッシュマップはO(n)を使用します。どちらも、そのパフォーマンスの平均と最悪のケースをその表記法と共有しています。
ここで、特定のエンジンに戻ります。エンジンのデータ構造を考えると、取得するターゲットデータに基づいて適用されるクエリは、もちろんデータベースサーバーのパフォーマンスに影響します。ハッシュテーブルは範囲検索を実行できませんが、Bツリーはこれらのタイプの検索を実行するのに非常に効率的であり、大量のデータを処理することもできます。
保存するデータに適切なエンジンを使用して、保存するこれらの特定のデータに適用するクエリの種類を特定する必要があります。これらのデータがビジネスロジックに変換されるときにどのような種類のロジックを作成するか。
数千または数千のデータベースを処理し、取得して保存するクエリとデータを適切なエンジンと組み合わせて使用すると、優れたパフォーマンスが得られます。適切なデータベース環境の目的のために要件を事前に決定して分析したことを前提としています。
信頼できる堅固なプラットフォームがなければ、非常に大規模なデータベースを管理することは非常に困難で困難です。優秀で熟練したデータベースエンジニアであっても、技術的には、使用しているデータベースサーバーは人為的エラーを起こしやすい傾向があります。構成パラメーターと変数の変更を1つ間違えると、大幅な変更が発生し、サーバーのパフォーマンスが低下する可能性があります。
非常に大規模なデータベースでデータベースへのバックアップを実行することは、困難な場合があります。奇妙な理由でバックアップが失敗する場合があります。一般に、バックアップが実行されているサーバーを停止させる可能性のあるクエリは失敗します。それ以外の場合は、原因を調査する必要があります。
Chef、Puppet、Ansible、Terraform、SaltStackなどの自動化をIaCとして使用すると、より迅速なタスクを実行できます。他のサードパーティツールも使用して、高品質のグラフ画像の監視と提供を支援します。アラートおよびアラーム通知システムは、警告から重大なステータスレベルまで発生する可能性のある問題から通知するためにも非常に重要です。これは、ClusterControlがこの種の状況で非常に役立つ場所です。
ClusterControlを使用すると、多数のデータベースを簡単に管理でき、シャードタイプの環境でも簡単に管理できます。これは、1000回テストおよびインストールされており、データベース環境を運用しているDBA、エンジニア、またはDevOpsにアラームと通知を提供するプロダクションで実行されています。ステージングまたは開発、QAから本番環境に至るまで。
ClusterControlは、バックアップと復元も実行できます。大規模なデータベースの場合でも、UIにはスケジュールが用意されており、クラウド(AWS、Google Cloud、Azure)にアップロードするオプションもあるため、効率的で管理が簡単です。
バックアップ検証と、暗号化や圧縮などの多くのオプションもあります。たとえば、以下のスクリーンショットを参照してください(Xtrabackupを使用してMySQLのバックアップを作成する):
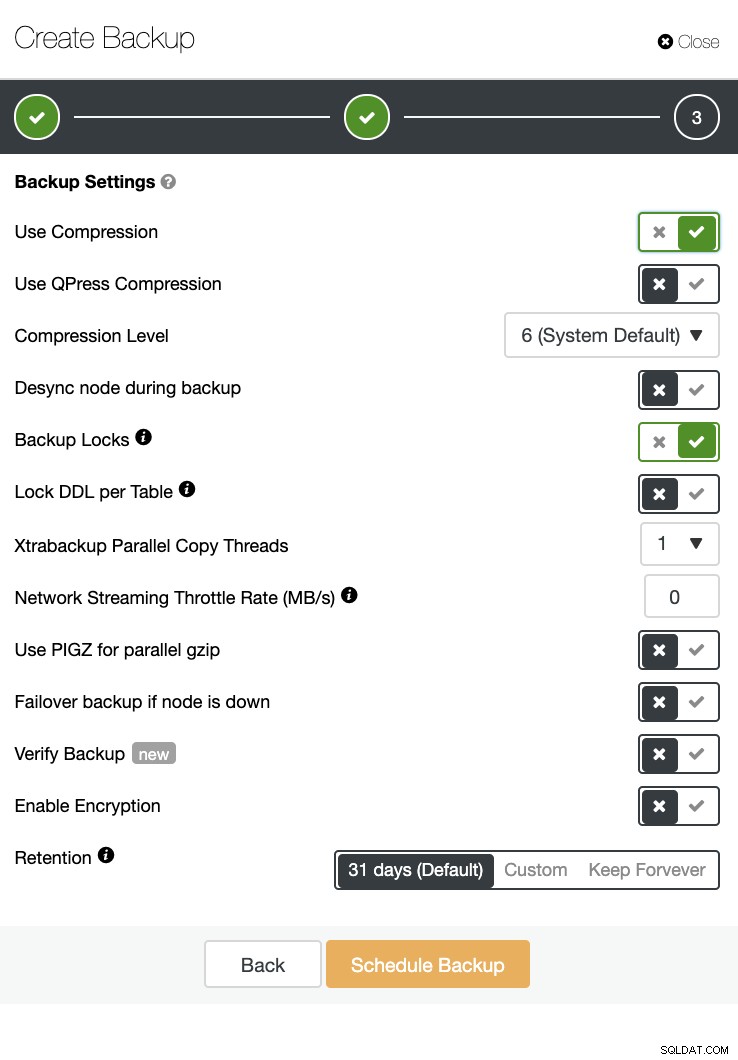
1000以上のような大規模なデータベースの管理は効率的に実行できますが、事前に決定して準備する必要があります。自動化などの適切なツールを使用したり、マネージドサービスにサブスクライブしたりすることで、大幅に役立ちます。コストはかかりますが、適切なツールが利用可能である限り、熟練したエンジニアを獲得するために費やされるサービスと予算のターンアラウンドを減らすことができます。