MySQLレプリケーションの自動フェイルオーバーは、長年にわたって議論されてきました。
それは良いことですか、悪いことですか?
MySQLの世界で長いメモリを持っている人は、主にソフトウェアが間違った決定をしたことが原因であった2012年のGitHubの停止を覚えているかもしれません。
その後、GitHubは、MySQL Replication、Corosync、Pacemaker、およびPerconaReplicationManagerの組み合わせに移行したばかりでした。 PRMは、スキーマの移行中に過負荷になったマスターのヘルスチェックに失敗した後、フェイルオーバーを実行することを決定しました。新しいマスターが選択されましたが、コールドキャッシュのためにパフォーマンスが低下しました。ビジーサイトからの高いクエリ負荷により、コールドマスターでPRMハートビートが再び失敗し、PRMが元のマスターへの別のフェイルオーバーをトリガーしました。そして、以下に要約するように、問題は続いた。
 出典:PerconaLive2013のHenrikIngoとMassimoBrignoli
出典:PerconaLive2013のHenrikIngoとMassimoBrignoli 数年早送りすると、GitHubはMySQLレプリケーションと自動フェイルオーバーを管理するための非常に洗練されたフレームワークで戻ってきました! Shlomi Noachが言うように:
「そのために、自動マスターフェイルオーバーを採用しています。人間がウェイクアップして障害のあるマスターを修正するのにかかる時間は、可用性の予想を超えており、そのようなフェイルオーバーの操作は簡単ではない場合があります。マスターの障害は30秒以内に自動的に検出および回復されると予想され、フェイルオーバーによって使用可能なホストの損失が最小限に抑えられると予想されます。」
ほとんどの企業はGitHubではありませんが、停止を好む企業はないと主張する人もいるかもしれません。停止はどのビジネスにとっても破壊的であり、コストもかかります。私の推測では、ほとんどの企業はおそらく何らかの自動フェイルオーバーが必要であり、それを実装しない理由は、おそらく既存のソリューションの複雑さ、そのようなソリューションを実装する能力の欠如、またはソフトウェアへの信頼の欠如です。そのような重要な決定。
MHA、MMM、MRM、mysqlfailover、Orchestrator、ClusterControlなど、多数の自動フェイルオーバーソリューションがあります(これらに限定されません)。それらのいくつかは何年もの間市場に出回っています、他のものはより最近のものです。これは良い兆候です。複数のソリューションは、市場が存在し、人々が問題に対処しようとしていることを意味します。
ClusterControl内で自動フェイルオーバーを設計したとき、いくつかの基本原則を使用しました。
-
フェイルオーバーする前に、マスターが本当に死んでいることを確認してください
フェイルオーバーソフトウェアがマスターとの接続を失うネットワークパーティションの場合、それはそれを見るのをやめます。ただし、マスターは正常に機能している可能性があり、残りのレプリケーショントポロジで確認できます。
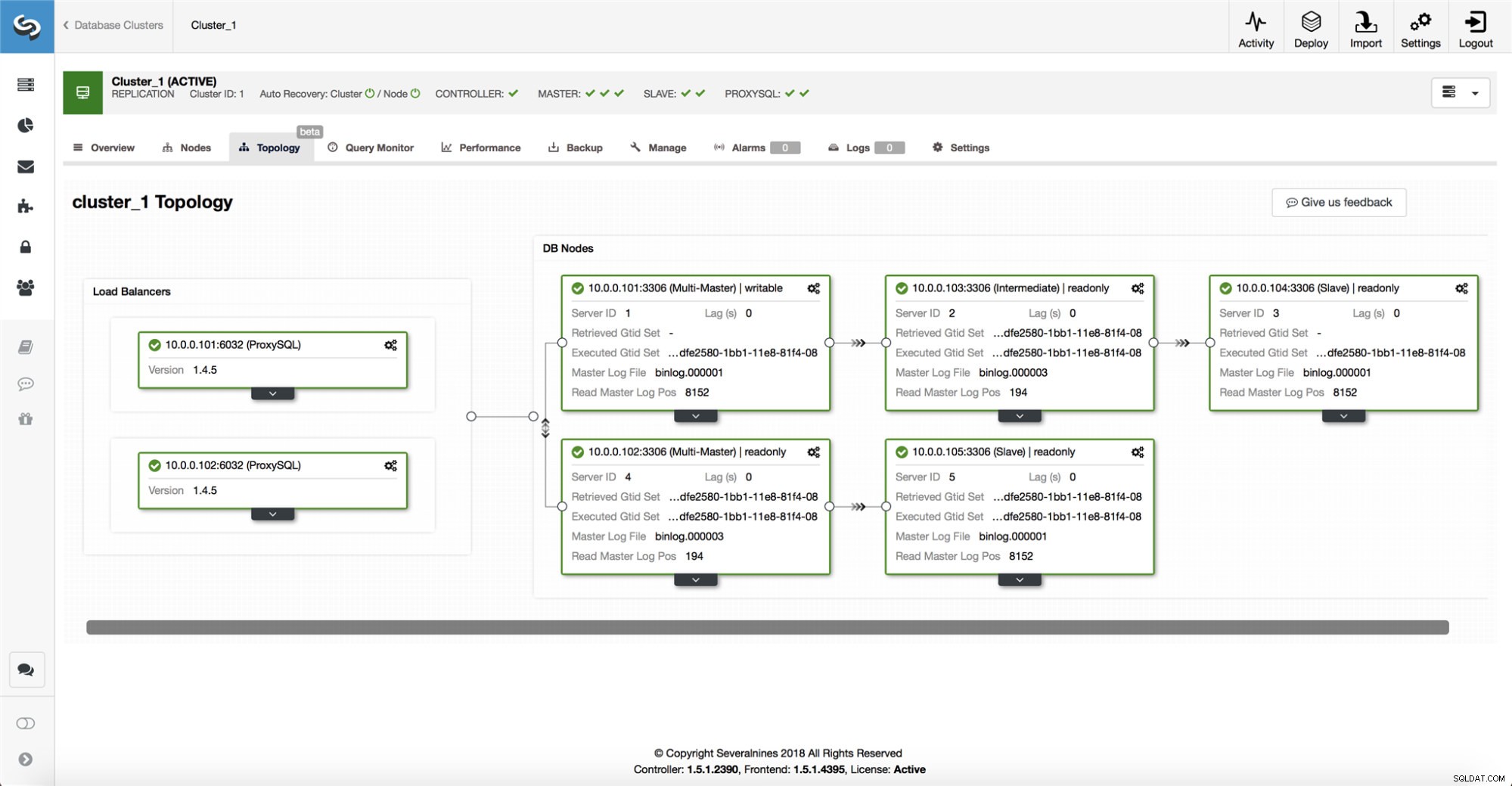
ClusterControlは、すべてのデータベースノード、および使用されているデータベースプロキシ/ロードバランサーから情報を収集し、トポロジの表現を構築します。スレーブがマスターを認識できる場合、またはClusterControlがマスターの状態について100%確信していない場合、フェイルオーバーは試行されません。
ClusterControlを使用すると、セットアップのトポロジやさまざまなノードのステータスを簡単に視覚化することもできます(これは、収集した情報に基づいた、ClusterControlによるシステムの状態の理解です)。
-
フェイルオーバーは1回のみ
羽ばたきについて多くのことが書かれています。可用性ツールが複数のフェイルオーバーを実行することを決定した場合、非常に厄介になる可能性があります。それは危険な状況です。選出された各マスターは、マスターの役割を保持していた期間が短い場合でも、どのサーバーにも複製されなかった独自の変更セットを持っている可能性があります。そのため、選出されたすべてのマスター間で一貫性が失われる可能性があります。
-
一貫性のないスレーブにフェイルオーバーしないでください
マスターとして昇格するスレーブを選択するときは、スレーブに矛盾がないことを確認します。誤ったトランザクション。これにより、レプリケーションが非常にうまく機能しなくなる可能性があります。
-
マスターにのみ書き込む
レプリケーションはマスターからスレーブに移動します。スレーブに直接書き込むと、発散するデータセットが作成され、それが潜在的な問題の原因となる可能性があります。 MySQLまたはMariaDBの最新バージョンでは、スレーブをread_onlyおよびsuper_read_onlyに設定しました。また、ProxySQLやMaxScaleなどのロードバランサーを使用して、基盤となるデータベーストポロジとその変更からアプリケーション層を保護することをお勧めします。ロードバランサーは、現在のマスターへの書き込みも強制します。
-
障害が発生したマスターを自動的に回復しない
マスターに障害が発生し、新しいマスターが選出された場合、ClusterControlは障害が発生したマスターの回復を試みません。なんで?そのサーバーにはまだ複製されていないデータが含まれている可能性があり、管理者は障害について調査する必要があります。 OK、引き続きClusterControlを構成して、障害が発生したマスターのデータを消去し、新しいマスターのスレーブとして参加させることができます。データを失っても問題がない場合は。ただし、デフォルトでは、ClusterControlは、誰かがマスターを確認してトポロジに再導入することを決定するまで、失敗したマスターをそのままにします。
では、フェイルオーバーを自動化する必要がありますか?レプリケーションをどのように構成したかによって異なります。複数の書き込み可能なマスターまたは複雑なトポロジを使用した循環レプリケーションのセットアップは、自動フェイルオーバーの候補としては適切ではない可能性があります。レプリケーションソリューションを設計するときは、上記の原則に固執します。
PostgreSQLの場合
PostgreSQLストリーミングレプリケーションに関しては、ClusterControlは同様の原則を使用してフェイルオーバーを自動化します。 PostgreSQLの場合、ClusterControlは、マスターとスレーブ間の非同期レプリケーションモデルと同期レプリケーションモデルの両方をサポートします。どちらの場合も、障害が発生した場合も、最新のデータを持つスレーブが新しいマスターとして選出されます。障害が発生したマスターは、レプリケーション設定に再参加するために自動的に回復/修正されることはありません。
故障したマスターがダウンし、ダウンしたままであることを確認するために取られるいくつかの保護対策があります。プロキシの負荷分散セットから削除され、たとえば次の場合に強制終了されます。ユーザーは手動で再起動します。 ClusterControlとマスターの間のネットワーク分割を検出することは、スレーブが複製元のマスターのステータスに関する情報を提供しないため、少し難しいです。したがって、データベース設定の前にあるプロキシは、マスターへの別のパスを提供できるため重要です。
MongoDB上
oplogを介したレプリカセット内のMongoDBレプリケーションは、binlogレプリケーションと非常に似ていますが、MongoDBが障害のあるマスターを自動的に回復するのはなぜですか?問題はまだ存在しており、MongoDBは、障害時にスレーブに複製されなかった変更をロールバックすることで問題に対処します。そのデータは削除されて「ロールバック」フォルダに配置されるため、データを復元するのは管理者の責任です。
詳細については、ClusterControlを確認してください。以下にコメントしたり質問したりしてください。