メンテナンスは、運用チームが避けられないものです。サーバーは、最新のソフトウェア、ハードウェア、テクノロジーに対応して、システムを安定させ、可能な限りリスクを最小限に抑えて実行すると同時に、新しい機能を利用して全体的なパフォーマンスを向上させる必要があります。
間違いなく、特に重要なシステムに関しては、システム管理者が実行する必要のあるメンテナンスタスクの長いリストがあります。一部のタスクは、毎日、毎週、毎月、毎年など、定期的に実行する必要があります。いくつかは、緊急に、すぐに行わなければなりません。それでも、メンテナンス操作が別の大きな問題につながることはなく、ビジネスの中断を避けるために、メンテナンスは特別な注意を払って処理する必要があります。
メンテナンスの進行中は、疑わしい状態や誤ったアラームが発生することがよくあります。これは、メンテナンス期間中は、メンテナンスタスクが完了するまでサーバーが正常に動作しないためです。オープンソースデータベース用の包括的な管理および監視プラットフォームであるClusterControlは、これらの状況を理解するように構成して、提供する監視および自動化機能を犠牲にすることなく、メンテナンスルーチンを簡素化できます。
メンテナンスモード
ClusterControlはバージョン1.4.0でメンテナンスモードを導入しました。このモードでは、個々のノードをメンテナンスに入れることができ、ClusterControlが指定された期間アラームを発生させて通知を送信するのを防ぎます。メンテナンスモードは、ClusterControl UIから設定することも、「s9s」と呼ばれるClusterControlCLIツールを使用して設定することもできます。 UIから、ノード->ノードの選択->ノードアクション->メンテナンスモードのスケジュールに移動します。 :
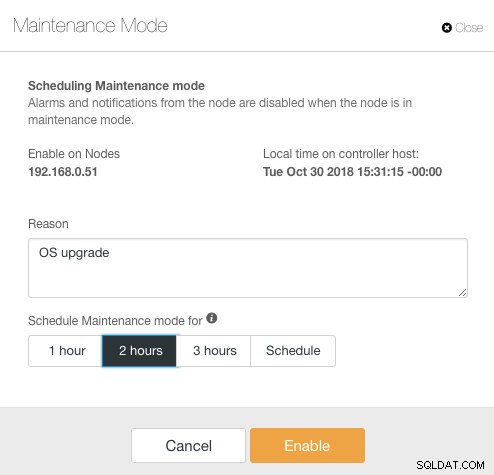
ここでは、事前定義された時間のメンテナンス期間を設定するか、それに応じてスケジュールすることができます。監査の目的に役立つ、アップグレードをスケジュールする理由を書き留めることもできます。メンテナンスモードがアクティブになると、次の通知が表示されます。
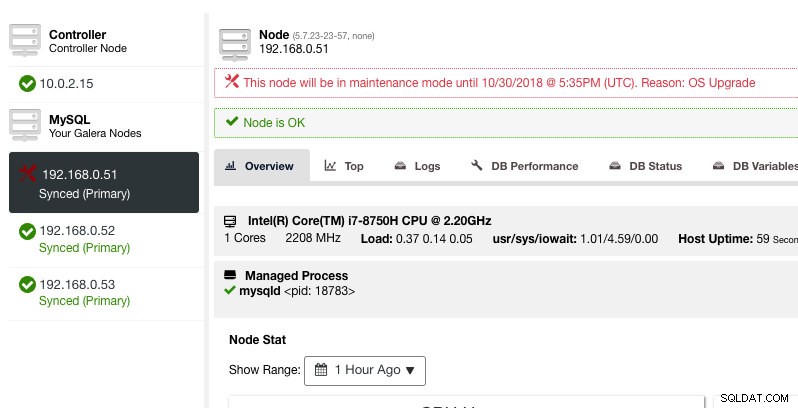
ClusterControlはノードを劣化させないため、状態を変更するアクションを実行しない限り、ノードの状態はそのままになります。このノードのアラームと通知は、メンテナンス期間が終了すると再びアクティブになります。または、オペレーターがノードアクション->メンテナンスモードの無効化に移動して明示的に無効にします。 。
自動ノードリカバリが有効になっている場合、ClusterControlはメンテナンスモードのステータスに関係なく常にノードをリカバリすることに注意してください。 ClusterControlがメンテナンスタスクに干渉しないように、ノードリカバリを無効にすることを忘れないでください。これは、上部の概要バーから実行できます。
メンテナンスモードは、ClusterControlCLIまたは「s9s」を介して構成することもできます。 「s9smaintenance」コマンドを使用して、メンテナンス期間を一覧表示および操作できます。次のコマンドラインは、ノード192.168.1.121の1時間のメンテナンスウィンドウを明日スケジュールします。
$ s9s maintenance --create \
--nodes=192.168.1.121 \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="Upgrading software."詳細と例については、s9sのメンテナンスドキュメントを参照してください。
クラスター全体のメンテナンスモード
この記事の執筆時点では、メンテナンスモードの構成は管理対象ノードごとに構成する必要があります。クラスタ全体のメンテナンスでは、クラスタの管理対象ノードごとにスケジューリングプロセスを繰り返す必要があります。クラスタ内にノードの数が多い場合、または2つのタスク間のメンテナンス間隔が非常に短い場合、これは実用的でない可能性があります。
幸い、ClusterControl CLI(別名s9s)は、この制限を克服するための回避策として使用できます。 「s9sノード」を使用して、クラスター内の管理対象ノードを一覧表示および操作できます。このリストを繰り返して、「s9smaintenance」コマンドを使用してクラスター全体のメンテナンスモードを一度にスケジュールできます。
これをよりよく理解するために例を見てみましょう。次の3ノードのPerconaXtraDBクラスターについて考えてみます。
$ s9s nodes --list --cluster-name='PXC57' --long
STAT VERSION CID CLUSTER HOST PORT COMMENT
coC- 1.7.0.2832 1 PXC57 10.0.2.15 9500 Up and running.
go-M 5.7.23 1 PXC57 192.168.0.51 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.52 3306 Up and running.
go-- 5.7.23 1 PXC57 192.168.0.53 3306 Up and running.
Total: 4クラスターには、合計4つのノード(1つのClusterControlノードを持つ3つのデータベースノード)があります。最初の列であるSTATは、ノードの役割とステータスを示します。最初の文字はノードの役割です。「c」はコントローラーを意味し、「g」はGaleraデータベースノードを意味します。メンテナンスのためにデータベースノードのみをスケジュールする場合、出力をフィルターで除外して、報告されたSTATの先頭に「g」が付いているホスト名またはIPアドレスを取得できます。
$ s9s nodes --list --cluster-name='PXC57' --long --batch | grep ^g | awk {'print $5'}
192.168.0.51
192.168.0.52
192.168.0.53簡単な反復で、クラスター内のすべてのノードに対してクラスター全体のメンテナンスウィンドウをスケジュールできます。次のコマンドは、forループを使用して、クラスター内で見つかったすべてのIPアドレスに基づいてメンテナンスの作成を繰り返します。ここで、明日同じ時間にメンテナンス操作を開始し、1時間後に終了する予定です。
$(s9sノード--list --cluster-id ='PXC57' --long --batch | grep ^ g | awk {'print $ 5'});のホストの$ for host in $(s9s nodes --list --cluster-id='PXC57' --long --batch | grep ^g | awk {'print $5'}); do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now + 1 day' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 1 day + 1 hour' '+%Y-%m-%d %H:%M:%S')" \
--reason="OS upgrade"; done
f92c5370-004d-4735-bba0-8c1bd26b9b98
9ff7dd8c-f2cb-4446-b14b-a5c2b915b853
103d715d-d0bc-4402-9326-1a053bc5d36b3つのUUIDのプリントアウトが表示されます。これは、すべてのメンテナンス期間を識別する一意の文字列です。次に、次のコマンドで確認できます。
$ s9s maintenance --list --long
ST UUID OWNER GROUP START END HOST/CLUSTER REASON
-h f92c537 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.51 OS upgrade
-h 9ff7dd8 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.52 OS upgrade
-h 103d715 admin admins 2018-10-31 16:02:00 2018-10-31 17:02:00 192.168.0.53 OS upgrade
Total: 3上記の出力から、すべてのデータベースノードのスケジュールされたメンテナンス時間のリストを取得しました。スケジュールされた時間中、ClusterControlは、クラスターに異常が見つかった場合にアラームを発生させたり、通知を送信したりしません。
メンテナンスモードの反復
バックアップ、ハウスキーピング、クリーンアップタスクなど、一部のメンテナンスルーチンは定期的に実行する必要があります。メンテナンス期間中は、サーバーの動作が異なることが予想されます。ただし、サービス障害、一時的なアクセス不能、または高負荷は、監視システムに大混乱をもたらすことは間違いありません。頻繁で短い間隔のメンテナンススロットの場合、これは非常に煩わしいことが判明する可能性があり、発生した誤ったアラームをスキップすると、夜間の睡眠が改善される可能性があります。
ただし、メンテナンスモードを有効にすると、厳密な監視が一定期間無視されるため、サーバーがより大きなリスクにさらされる可能性があります。したがって、メンテナンスモードを有効にする前に、実行するメンテナンス操作の性質を理解しておくことをお勧めします。次のチェックリストは、メンテナンスモードポリシーを決定するのに役立ちます。
- 影響を受けるノード-どのノードがメンテナンスに関与していますか?
- 結果-メンテナンス操作が進行中の場合、ノードはどうなりますか?アクセスできない、高負荷になる、または再起動されますか?
- 期間-メンテナンス操作が完了するまでにどのくらいの時間がかかりますか?
- 頻度-メンテナンス操作を実行する頻度はどれくらいですか?
それをユースケースに入れましょう。 ClusterControlノードを持つ3ノードのPerconaXtraDBクラスターがあるとします。サーバーがすべて仮想マシンで実行されており、VMバックアップポリシーでは、すべてのVMを毎日午前1時から1ノードずつバックアップする必要があるとします。このバックアップ操作中、ノードは最大約10分間フリーズし、ClusterControlによって管理および監視されているノードは、バックアップが完了するまでアクセスできなくなります。ガレラクラスターの観点からは、クラスターはクォーラムのままであり、プライマリコンポーネントは影響を受けないため、この操作によってクラスター全体がダウンすることはありません。
メンテナンスタスクの性質に基づいて、次のように要約できます。
- 影響を受けるノード-クラスターID1のすべてのノード(3つのデータベースノードと1つのClusterControlノード)。
- 結果-バックアップされているVMは、完了するまでアクセスできなくなります。
- 期間-各VMバックアップ操作は、完了するまでに約5〜10分かかります。
- 頻度-VMバックアップは、最初のノードで午前1時から毎日実行されるようにスケジュールされています。
次に、メンテナンスモードをスケジュールするための実行計画を立てることができます。
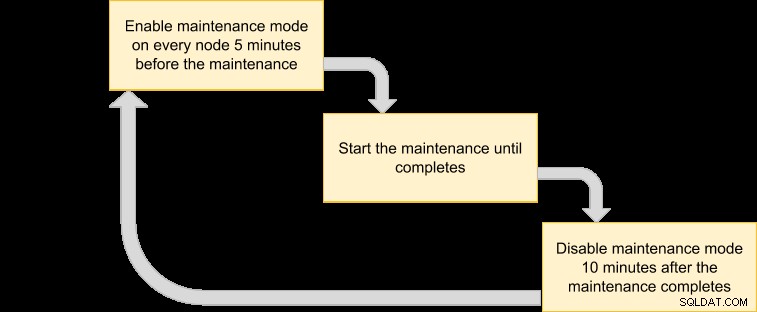
クラスター内のすべてのノードをVMマネージャーでバックアップする必要があるため、対応するクラスターIDのノードをリストするだけです。
$ s9s nodes --list --cluster-id=1
192.168.0.51 10.0.2.15 192.168.0.52 192.168.0.53上記の出力を使用して、クラスター全体のメンテナンスをスケジュールできます。たとえば、次のコマンドを実行すると、ClusterControlは、現在から次の50分まで、クラスターID1の下にあるすべてのノードのメンテナンスモードをアクティブにします。
$(s9sノード--list --cluster-id =1);のホストの$ for host in $(s9s nodes --list --cluster-id=1); do \
s9s maintenance --create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="Backup VM"; done上記のコマンドを使用して、スクリプトに入れることで実行ファイルに変換できます。ファイルを作成します:
$ vim /usr/local/bin/enable_maintenance_modeそして、次の行を追加します:
for host in $(s9s nodes --list --cluster-id=1)
do \
s9s maintenance \
--create \
--nodes=$host \
--start="$(date -d 'now' '+%Y-%m-%d %H:%M:%S')" \
--end="$(date -d 'now + 50 minutes' '+%Y-%m-%d %H:%M:%S')" \
--reason="VM Backup"
done保存して、ファイルのアクセス許可が実行可能であることを確認してください:
$ chmod 755 /usr/local/bin/enable_maintenance_mode次に、cronを使用して、VMバックアップ操作が午前1:00に開始される直前に、スクリプトが毎日5分から午前1:00に実行されるようにスケジュールします。
$ crontab -e
55 0 * * * /usr/local/bin/enable_maintenance_modecronデーモンをリロードして、スクリプトがキューに入れられていることを確認します。
$ systemctl reload crond # or service crond reloadそれでおしまい。これで、メンテナンスが完了するまで、誤ったアラームやメール通知に悩まされることなく、日常のメンテナンス操作を実行できます。
ボーナスメンテナンス機能-ノードリカバリのスキップ
自動リカバリを有効にすると、ClusterControlはノードの障害を検出するのに十分スマートであり、メンテナンスモードのステータスに関係なく、30秒の猶予期間後に障害が発生したノードのリカバリを試みます。 ClusterControlは、特定のノードのノード回復を意図的にスキップするように構成できることをご存知ですか?これは、メンテナンスの期間と結果を知らずに緊急のメンテナンスを実行する必要がある場合に非常に役立ちます。
たとえば、ファイルシステムの破損が発生し、ハードリブート後にファイルシステムのチェックと修復が必要になったとします。この操作を完了するために必要な時間を事前に決定することは困難です。したがって、フラグファイルを使用して、NodeのリカバリをスキップするようにClusterControlに通知するだけです。
まず、ClusterControlノードの/etc/cmon.d/cmon_X.cnf(XはクラスターID)内に次の行を追加します。
node_recovery_lock_file=/root/do_not_recover次に、cmonサービスを再起動して、変更をロードします。
$ systemctl restart cmon # service cmon restart最後に、指定されたファイルがClusterControlリカバリのためにスキップするノードに存在することを確認します。
$ touch /root/do_not_recover自動リカバリーおよび保守モードの状況に関係なく、ClusterControlは、このフラグ・ファイルが存在しない場合にのみノードをリカバリーします。管理者は、データベースノードでファイルを作成および削除する責任があります。
それだけです、皆さん。メンテナンスをお楽しみください!