SQLは、クエリに関する限り、リレーショナルデータベースを利用するための最も好ましい方法です。ユーザーは、SQLクエリ機能を採用しているMySQLやPostgreSQLなどのリレーショナルデータベースを使用していたと理解されています。一般に、SQLは理解しやすいため、特にリレーショナルデータベースで広く使用されるようになりました。
ただし、データベース内のさまざまなドキュメントを使用しようとすると、SQLは非常に複雑になります。一言で言えば、それは多くの挫折を伴うので、ドキュメントデータベースを対象としていません。たとえば、埋め込まれた配列ドキュメントを簡単にクエリすることはできません。または、返されたデータを反復およびフィルタリングして必要な結果を得るサブプログラムを設計する必要があります。したがって、これにより実行時間が増加します。ただし、SQLをよく理解していると、最初から始めるのではなく、ある時点からMongoDBを操作するためのより良い基盤が得られます。
このブログでは、Studio 3Tプログラムを使用して、さまざまなSQL結合クエリと、それらをMongoDBクエリに再設計してパフォーマンスを向上させる方法を示します。プログラムはこのリンクからダウンロードできます。
SQLをMongoDBに接続する
SQLを使用してMongoDBと通信できるいくつかのドライバーまたはインターフェースがあります(例:ODBC)。 ODBCは、OpenDatabaseConnectivityの略です。これは、アプリケーションがデータベース管理システムのデータにアクセスするための標準プロセスとしてSQLを使用して、そのデータにアクセスできるようにするための単なるインターフェイスです。相互運用性の利点が追加され、単一のアプリケーションが複数のデータベース管理システムにアクセスできるようになります。
このブログでは、SQLからコードを生成してテストし、集計エディターを介してコードを最適化して、MongoDBクエリを生成します。
SQLのチャートをMongoDBにマッピング
詳細に入る前に、これら2つのデータベース間の基本的な関係、特にクエリの概念におけるキーワードを理解する必要があります。
用語と概念
| SQL | MongoDB |
|---|---|
| テーブル 行 列 テーブル結合 | コレクション BSONドキュメント フィールド $lookup |
SQLの主キーは、基本的にレコード時間の順に行を配置する一意の列を定義します。一方、MongoDBの主キーは、ドキュメントを保持し、インデックス付きフィールドに重複する値が格納されないようにするための一意のフィールドです。
SomeninesがMongoDBDBAになる-MongoDBを本番環境に導入MongoDBDownloadを無料でデプロイ、監視、管理、スケーリングするために知っておくべきことを学びましょうSQLとMongoDBの相関関係
学生データがあり、このデータをSQLデータベースとMongoDBの両方に記録したいとします。単純な学生オブジェクトを次のように定義できます:
{
name: ‘James Washington’,
age: 15,
grade: A,
Score: 10.5
}SQLテーブルを作成する際には、列名とデータ型を定義する必要がありますが、MongoDBでは、最初の挿入時にコレクションが自動的に作成されます。
次の表は、SQLステートメントの一部をMongoDBで作成する方法を理解するのに役立ちます。
| SQLスキーマステートメント | MongoDBスキーマステートメント |
|---|---|
データベースにドキュメントを挿入するには | マングースなどのいくつかのモジュールを使用してスキーマ設計を定義し、相関関係を示すためにドキュメントを直接挿入するのではなく、オブジェクトのようにフィールドを定義できます。プライマリファイルIDは、ドキュメントの挿入中に自動的に生成されます。 コレクションを作成するための新しいドキュメントの挿入 |
| ADDステートメントを使用して、既存のテーブルに新しい列を追加します。 | コレクションドキュメントの構造は明確に定義されていないため、updateMany() を使用してドキュメントレベルでドキュメントを更新します。 |
| 列をドロップするには(単位) | フィールド(ユニット)をドロップするには |
| テーブルの生徒をドロップするには | コレクションの生徒をドロップするには |
| SQLSelectステートメント | MongoDBfindステートメント |
|---|---|
| すべての行を選択 | すべてのドキュメントを選択 |
| 特定の列のみを返すため。 | 特定のフィールドのみを返します。デフォルトでは、投影プロセスで特に指定されていない限り、_idフィールドが返されます。 _id:0を設定すると、返されるドキュメントのみが名前とグレードオブジェクトの値のみを持つことを意味します。 |
| 列の値が一致する特定の行を選択します。 | フィールド値が一致する特定のドキュメントを選択します。 |
| 提供された基準値として値にいくつかの文字が含まれる列を持つ行を選択する | 提供された基準値として値にいくつかの文字が含まれるフィールドを持つドキュメントを選択する |
| 主キーを使用して行を昇順で返すには。 | 主キーを使用して昇順でドキュメントを返すには |
| 返された行をいくつかの列(グレード)に従ってグループ化するには | 返されたドキュメントを特定のフィールド(グレード)に従ってグループ化するには |
| 返される行の数を制限し、一部をスキップする | 返されるドキュメントの数を制限し、行をスキップする |
| 重要なオプションは、クエリがどのように実行されるかを知ることです。したがって、explainメソッドを使用します。 | |
| SQLUpdateステートメント | MongoDB更新ステートメント |
|---|---|
| 15歳以上の生徒の成績列を更新します | ここでは、$ gt、$ lt、$lteなどの演算子を使用しています。 |
| 列の値をインクリメントする | |
| SQL削除ステートメント | MongoDBの削除ステートメント |
|---|---|
| すべての行を削除するには | すべてのドキュメントを削除します。 |
| 一部の列に特定の値がある特定の行を削除します。 | |
このサンプルマッピングテーブルを使用すると、次のトピックで学習する内容をよりよく理解できます。
SQLおよびStudio3T
Studio 3Tは、SQLとMongoDBの接続に役立つ利用可能なプログラムの1つです。 SQLを操作するために拡張するためのSQLクエリ機能があります。クエリはMongoシェルに解釈され、同等のMongoDB言語で単純なクエリコードが生成されます。単純なクエリを実行するだけでなく、Studio3Tアプリケーションは結合を実行できるようになりました。
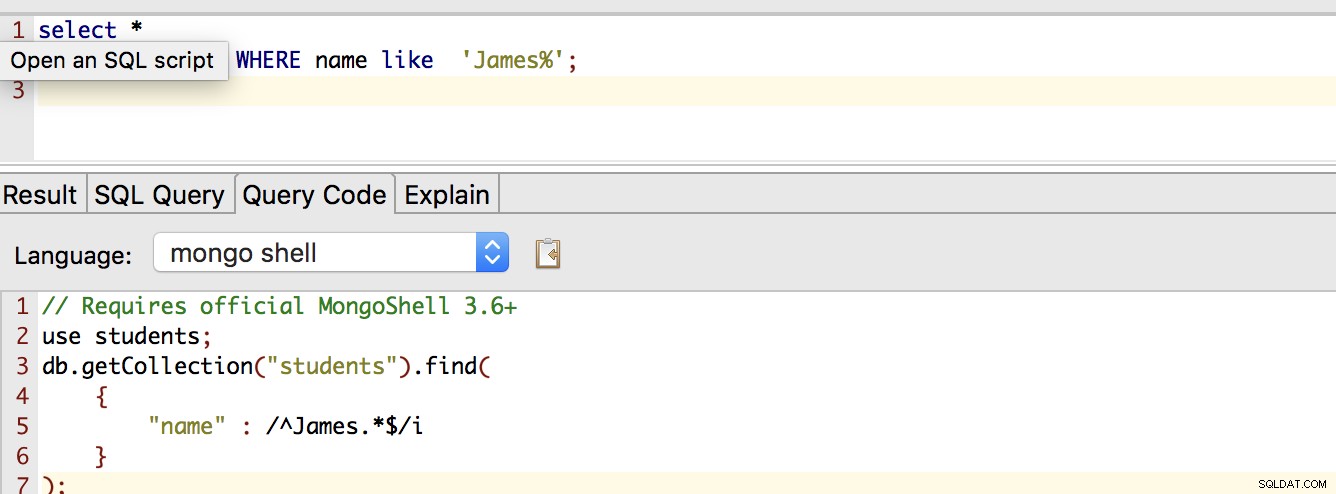
上記のサンプルデータの場合、Studio 3Tでデータベースを接続した後、SQLウィンドウを使用して、条件に一致するドキュメントを見つけることができます。例:
SELECT * FROM students WHERE name LIKE 'James%';名前フィールドが値Jamesに設定されているドキュメントがある場合は、そのドキュメントが返されます。同様に、[クエリコード]タブをクリックすると、同等のMongoDBコードを含むウィンドウが表示されます。上記のステートメントでは、次のようになります。
db.getCollection("students").find(
{
"name" : /^James.*$/i
}
);
概要
SQLに関する知識から、MongoDBをすばやく操作する方法が必要になる場合があります。 SQLとMongoDBの同等のコードとの基本的なコードの類似点をいくつか学びました。さらに、Studio 3Tなどの一部のプログラムには、SQLクエリをMongoDBと同等の言語に変換し、より良い結果を得るためにこのクエリを微調整するための十分に確立されたツールがあります。さて、私たちのほとんどにとって、これは私たちの仕事を簡単にし、最終的に私たちが持っているコードがデータベースのパフォーマンスに非常に最適であることを保証するための素晴らしいツールになります。このブログのパート2では、MongoDBのSQLINNERJOINについて学習します。