ClusterControlは、データベースシステムに影響を与えるさまざまなタイプの一般的な障害に自動的に対応するために、いくつかの回復アルゴリズムでプログラムされています。さまざまなタイプのデータベーストポロジとデータベース関連のプロセス管理を理解し、クラスターを回復するための最良の方法を決定するのに役立ちます。ある意味で、ClusterControlはデータベースの可用性を向上させます。
一部のトポロジマネージャは、MHA、Orchestrator、mysqlfailoverなどのクラスタリカバリのみを対象としていますが、ノードリカバリは自分で処理する必要があります。 ClusterControlは、クラスターレベルとノードレベルの両方でリカバリをサポートします。
ClusterControlでサポートされているリカバリコンポーネントは2つあります。つまり、
これら2つのコンポーネントは、サービスの可用性を可能な限り高くするために最も重要なものです。 ClusterControlの上にトポロジマネージャーが既にある場合は、自動回復機能を無効にして、他のトポロジマネージャーに処理させることができます。 ClusterControlにはすべての可能性があります。
自動リカバリ機能は、オン/オフを切り替えるだけで有効または無効にでき、クラスタまたはノードのリカバリで機能します。緑のアイコンは有効を意味し、赤のアイコンは無効を意味します。次のスクリーンショットは、データベースクラスターリストのどこにあるかを示しています。
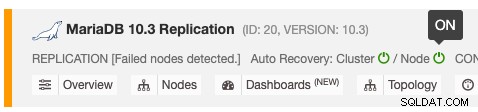
回復動作を制御するために使用できるClusterControlパラメーターは3つあります。すべてのパラメーターはデフォルトでtrueに設定されています(ブール整数0または1で設定):
- enable_autorecovery-クラスターとノードのリカバリを有効にします。このパラメーターは、enable_cluster_recoveryおよびenable_node_recoveryのスーパーセットです。 0に設定すると、サブセットパラメータがオフになります。
- enable_cluster_recovery-ClusterControlは、有効になっている場合、クラスターリカバリを実行します。
- enable_node_recovery-ClusterControlは、有効になっている場合、ノードの回復を実行します。
クラスターリカバリは、クラスタトポロジ全体を起動するためのリカバリの試みを対象としています。たとえば、マスタースレーブレプリケーションでは、使用可能なスレーブの数に関係なく、常に少なくとも1つのマスターが稼働している必要があります。 ClusterControlは、レプリケーションクラスターに対して少なくとも1回はトポロジを修正しようとしますが、NDBクラスターやガレラクラスターなどのマルチマスターレプリケーションに対しては無限に修正を試みます。
ノードリカバリは、ノードがClusterControlの知識なしに停止された場合など、ノードリカバリの問題をカバーします。たとえば、SSHコンソールからのシステム停止コマンドやOOMプロセスによる強制終了などです。
ClusterControlは、データベースノードへのプロセスと接続を監視することにより、断続的な障害が発生した場合にデータベースノードを回復できます。このプロセスでは、systemdと同様に機能し、ClusterControl UIを介して意図的に停止しない限り、MySQLサービスが開始および実行されていることを確認します。
ノードがオンラインに戻ると、ClusterControlはデータベースノードへの接続を確立し、必要なアクションを実行します。 ClusterControlがノードを回復するために行うことは次のとおりです。
- systemd / chkconfig/initが監視対象のサービス/プロセスを30秒間起動するのを待ちます
- 監視対象のサービス/プロセスがまだダウンしている場合、ClusterControlはデータベースサービスを自動的に開始しようとします。
- ClusterControlが監視対象のサービス/プロセスを回復できない場合、アラームが発生します。
データベースのシャットダウンがユーザーによって開始された場合、ClusterControlは特定のノードの回復を試みないことに注意してください。ユーザーは、[ノード]->[ノードアクション]->[ノードの開始]に移動するか、OSコマンドを明示的に使用して、ClusterControlUIを介して起動し直す必要があります。
リカバリには、ProxySQL、HAProxy、MaxScale、Keepalived、Prometheusエクスポーター、garbdなどのすべてのデータベース関連サービスが含まれます。 ClusterControlが「デーモン」と呼ばれるプログラムを使用してエクスポータープロセスをデーモン化するPrometheusエクスポーターに特に注意してください。 ClusterControlは、ヘルスチェックと検証のためにエクスポーターのリスニングポートに接続しようとします。したがって、回復中に誤ったアラームが発生しないように、ClusterControlサーバーとPrometheusサーバーからエクスポーターポートを開くことをお勧めします。
ClusterControlはデータベーストポロジを理解し、リカバリを実行する際のベストプラクティスに従います。 Galera Cluster、NDB Cluster、MongoDB Replicasetなどのフォールトトレランスが組み込まれているデータベースクラスターの場合、フェイルオーバープロセスは、クォーラム計算、ハートビート、および役割の切り替え(存在する場合)を介してデータベースサーバーによって自動的に実行されます。 ClusterControlはプロセスを監視し、トポロジビューでの変更の反映や、レプリカセット内の新しいプライマリノードなどの新しい役割の監視および管理コンポーネントの調整など、視覚化に必要な調整を行います。
MySQL/MariaDBレプリケーションやPostgreSQL/TimescaleDBストリーミングレプリケーションなど、自動リカバリを備えたフォールトトレランスが組み込まれていないデータベーステクノロジの場合、ClusterControlは、データベースベンダー。リカバリが失敗した場合は、ユーザーの介入が必要です。もちろん、これに関するアラーム通知が届きます。
混合/ハイブリッドトポロジ、たとえば、GaleraクラスターまたはNDBクラスターに接続されている非同期スレーブでは、クラスターリカバリが有効になっている場合、ノードはClusterControlによってリカバリされます。
MySQL/MariaDBレプリケーション
ClusterControlは、次のMySQL/MariaDBレプリケーションセットアップのリカバリをサポートしています。
- MySQLGTIDを使用したマスタースレーブ
- MariaDBGTIDを使用したマスタースレーブ
- GTIDなしのマスタースレーブ(MySQLとMariaDBの両方)
- MySQLGTIDを使用するマスターマスター
- MariaDBGTIDのマスターマスター
ClusterControlは、クラスターリカバリを実行するときに、次のパラメーターを尊重します。
- enable_cluster_autorecovery
- auto_manage_readonly
- repl_password
- repl_user
- replication_auto_rebuild_slave
- Replication_check_binlog_filter_bf_failover
- Replication_check_external_bf_failover
- Replication_failed_reslave_failover_script
- Replication_failover_blacklist
- Replication_failover_events
- Replication_failover_wait_to_apply_timeout
- Replication_failover_whitelist
- Replication_onfail_failover_script
- Replication_post_failover_script
- replication_post_switchover_script
- Replication_post_unsuccessful_failover_script
- Replication_pre_failover_script
- replication_pre_switchover_script
- replication_skip_apply_missing_txs
- replication_stop_on_error
各パラメータの詳細については、ドキュメントページを参照してください。
ClusterControlは、マスタースレーブレプリケーションを監視および管理するときに次のルールに従います。
- すべてのノードは、(その役割に関係なく)read_only=ONおよびsuper_read_only=ONで開始されます。
- 一度に操作できるのは1つのマスター(read_only =OFF)のみです。
- MySQL変数report_hostを使用してトポロジをマッピングします。
- 一度にread_only=OFFのノードが2つ以上ある場合、ClusterControlは、偶発的な書き込みから保護するために、両方のマスターでread_only=ONを自動的に設定します。読み取り専用を無効にして実際のマスターを選択するには、ユーザーの介入が必要です。 [ノード]->[ノードアクション]->[読み取り専用を無効にする]に移動します。
アクティブなマスターがダウンした場合、ClusterControlは次の順序でマスターフェイルオーバーを実行しようとします。
- マスターに到達できなくなってから3秒後、ClusterControlはアラームを発します。
- スレーブの可用性を確認します。少なくとも、1つのスレーブがClusterControlから到達可能である必要があります。
- GTIDが有効になっている場合、ClusterControlは誤ったトランザクションの確率を計算します。
- 誤ったトランザクションが検出されない場合、選択されたものが新しいマスターとして昇格します。
- スレーブを起動し、読み取り専用を有効にします。
- スレーブプロモーションが失敗した場合、ClusterControlはリカバリジョブを中止します。リカバリジョブを再度トリガーするには、ユーザーの介入またはcmonサービスの再起動が必要です。
- 古いマスターが再び利用可能になると、読み取り専用として開始され、レプリケーションの一部にはなりません。ユーザーの介入が必要です。
同時に、次のアラームが発生します:
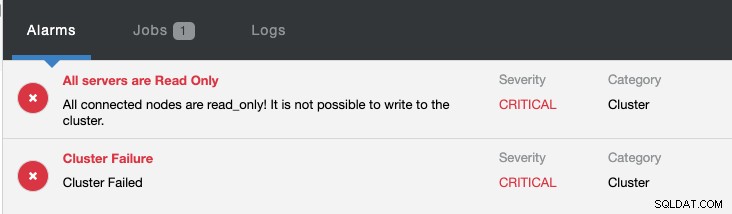
ClusterControlでMySQLレプリケーションフェイルオーバーを構成および管理する方法の詳細については、MySQLレプリケーションのフェイルオーバーの概要-101ブログおよびMySQLレプリケーションの自動フェイルオーバー-ClusterControl1.4の新機能をご覧ください。
PostgreSQL/TimescaleDBストリーミングレプリケーション
ClusterControlは、次のPostgreSQLレプリケーションセットアップのリカバリをサポートしています。
- PostgreSQLストリーミングレプリケーション
- TimescaleDBストリーミングレプリケーション
ClusterControlは、クラスターリカバリを実行するときに、次のパラメーターを尊重します。
- enable_cluster_autorecovery
- repl_password
- repl_user
- replication_auto_rebuild_slave
- Replication_failover_whitelist
- Replication_failover_blacklist
各パラメータの詳細については、ドキュメントページを参照してください。
ClusterControlは、PostgreSQLストリーミングレプリケーションのセットアップを管理および監視するための次のルールに従います。
- wal_levelは「replica」(またはPostgreSQLのバージョンによっては「hot_standby」)に設定されます。
- スレーブノードにrecovery.confファイルを設定します。これにより、ノードが読み取り専用が有効になっているホットスタンバイになります。
アクティブマスターがダウンした場合、ClusterControlは次の順序でクラスターリカバリを実行しようとします。
- マスターに到達できなくなってから10秒後、ClusterControlはアラームを発生させます。
- 10秒間の正常な待機タイムアウトの後、ClusterControlはマスターフェイルオーバージョブを開始します。
- 利用可能なすべてのノードでreplayLocationとreceiveLocationをサンプリングして、最も高度なノードを特定します。
- pg_rewindを使用して同期状態を確認します。
- スレーブプロモーションが失敗した場合、ClusterControlはリカバリジョブを中止します。リカバリジョブを再度トリガーするには、ユーザーの介入またはcmonサービスの再起動が必要です。
- 古いマスターが再び使用可能になると、強制的にシャットダウンされ、レプリケーションの一部にはなりません。ユーザーの介入が必要です。さらに下を参照してください。
古いマスターがオンラインに戻ったときに、PostgreSQLサービスが実行されている場合、ClusterControlはPostgreSQLサービスを強制的にシャットダウンします。これは、サーバーがリカバリファイル(recovery.conf)なしで起動されるため、サーバーが誤って書き込まれるのを防ぐためです。つまり、書き込み可能になります。次の行がpostgresql-{day}.logに表示されることを期待する必要があります:
2019-11-27 05:06:10.091 UTC [2392] LOG: database system is ready to accept connections
2019-11-27 05:06:27.696 UTC [2392] LOG: received fast shutdown request
2019-11-27 05:06:27.700 UTC [2392] LOG: aborting any active transactions
2019-11-27 05:06:27.703 UTC [2766] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.704 UTC [2758] FATAL: terminating connection due to administrator command
2019-11-27 05:06:27.709 UTC [2392] LOG: background worker "logical replication launcher" (PID 2419) exited with exit code 1
2019-11-27 05:06:27.709 UTC [2414] LOG: shutting down
2019-11-27 05:06:27.735 UTC [2392] LOG: database system is shut downサーバーが05:06:10頃にオンラインに戻った後、PostgreSQLが開始されましたが、ClusterControlはその17秒後の05:06:27頃に高速シャットダウンを実行します。これが望ましくない場合は、このクラスターのノードリカバリを一時的に無効にすることができます。
PostgreSQLレプリケーション101のPostgresレプリケーションの自動フェイルオーバーとフェイルオーバーを確認して、ClusterControlを使用してPostgreSQLレプリケーションフェイルオーバーを構成および管理する方法の詳細を確認してください。
ClusterControl自動リカバリは、データベースクラスタトポロジを理解し、ダウンまたは劣化したクラスタを完全に動作するクラスタにリカバリできます。これにより、データベースサービスの稼働時間が大幅に向上します。今すぐClusterControlを試して、SLAとデータベースの可用性で9を達成してください。あなたのナインを知らないのですか?このクールなナイン計算機をチェックしてください。