本番データベースの円滑な運用を確保することは簡単な作業ではなく、その作業に役立つツールやユーティリティが多数あります。正常性の監視、サーバーパフォーマンス、クエリの分析、展開、フェイルオーバーの管理、アップグレードに使用できるツールがあり、リストは続きます。データベースインフラストラクチャの管理および監視プラットフォームとしてのClusterControlは、展開から監視、継続的な管理およびスケーリングまでのライフサイクル全体を管理する機能で際立っています。
ClusterControlは、自動データベースフェイルオーバー、転送中/保存中の暗号化、バックアップ管理、ポイントインタイムリカバリ、Prometheus統合、データベーススケーリングなどの重要な機能を提供しますが、これらは市場の他のエンタープライズ管理/監視ツールにあります。ただし、簡単には見つけられない機能がいくつかあります。このブログ投稿では、市場に出回っている他の管理および監視ツールにはない9つの機能を紹介します(この記事の執筆時点)。
バックアップは、回復できることがわかるまでは文字通りバックアップではありません。実際に回復できることを確認する必要があります。 ClusterControlを使用すると、新しいサーバーをスピンして復元をテストすることにより、バックアップが作成された後にバックアップを検証できます。バックアップの検証は、ディザスタリカバリが発生した場合に目標復旧時点(RPO)ポリシーを確実に満たすための重要なプロセスです。検証プロセスは、新しいスタンドアロンホスト(ClusterControlが復元前に必要なデータベースパッケージをインストールする場所)またはバックアップ検証専用のサーバーで復元を実行します。
バックアップ検証を構成するには、既存のバックアップを選択して[復元]をクリックするだけです。復元して確認するオプションがあります:
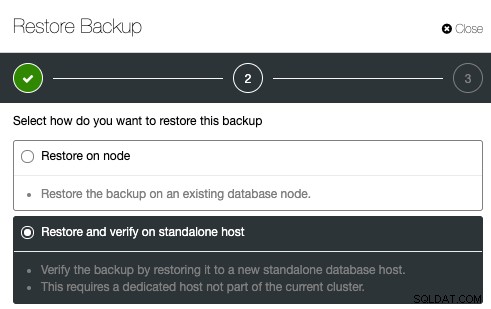
次に、必要なサーバーのIPアドレスを指定するだけです。復元と確認:
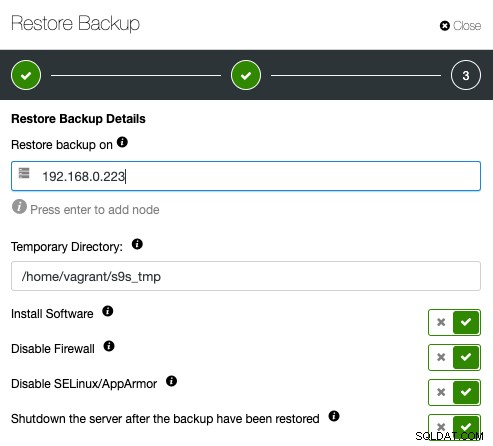
指定されたホストがパスワードなしのSSH経由でアクセス可能であることを事前に確認してください。また、プロビジョニングプロセスの下にいくつかのオプションがあります。復元後に検証サーバーをシャットダウンして、バックアップの検証後にコストとリソースを節約することもできます。 ClusterControlは、復元プロセスの終了コードを探し、復元ログを観察して、検証が失敗したか成功したかを確認します。
GUIによるProxySQL管理の簡素化
多くの人は、システムを構成するときに、グラフィカルユーザーインターフェイスを使用する方が効率的で、人為的エラーが発生しにくいことに同意します。 ProxySQLは重要なデータベースレイヤーの一部であり(その上にありますが)、一般的な問題や問題を見つけるためにDBAの目に十分に見える必要があります。 ClusterControlは、ProxySQL用の包括的なグラフィカルユーザーインターフェイスを提供します。
ProxySQLインスタンスは、新しいホストにデプロイすることも、既存のインスタンスをClusterControlにインポートすることもできます。 ClusterControlは、データベースサーバーへの単一エンドポイントアクセスのために、仮想IPアドレス(Keepalivedによって提供される)と統合されるようにProxySQLを構成できます。また、クエリバックエンド、低速クエリ、上位クエリ、クエリヒット、およびその他の多数の監視統計などの主要なProxySQLコンポーネントに対する監視の洞察も提供します。以下は、新しいクエリルールを追加する方法を示すスクリーンショットです。
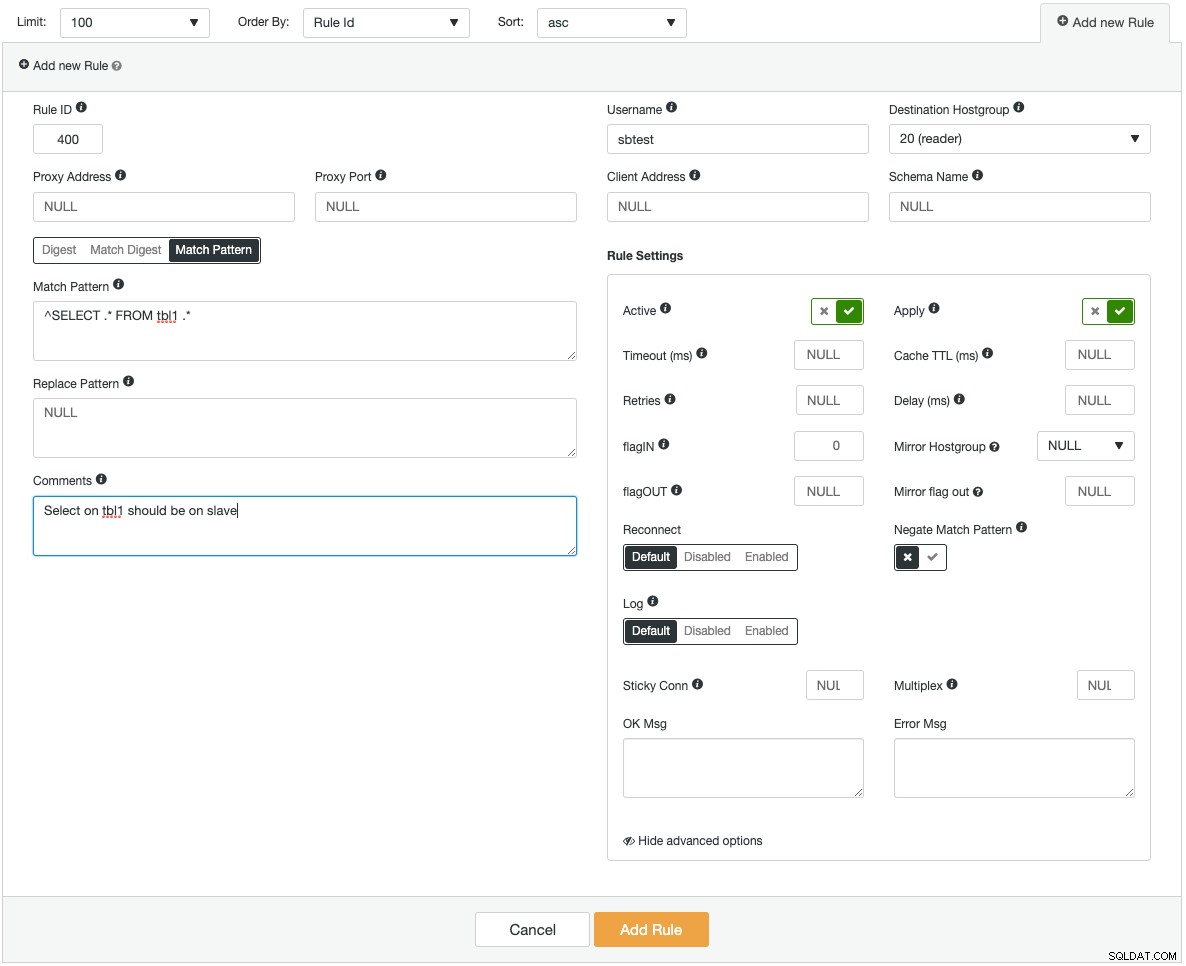
非常に複雑なクエリルールを追加する場合は、グラフィカルユーザーインターフェイスを介して追加する方が快適です。すべてのフィールドには、クエリルールフォームに入力するときに役立つツールチップがあります。 ProxySQL構成を追加または変更する場合、ClusterControlは、変更がランタイムに加えられ、永続性のためにディスクに保存されることを確認します。
ClusterControl 1.7.4は、ProxySQL1.xとProxySQL2.xの両方をサポートするようになりました。
運用レポートは、データベースインフラストラクチャの概要レポートのセットであり、オンザフライで生成することも、さまざまな受信者に送信するようにスケジュールすることもできます。これらのレポートはさまざまなチェックで構成され、さまざまな日常のDBAタスクに対応しています。 ClusterControlの運用レポートの背後にある考え方は、データベースとそのプロセスのステータスを明確に理解するために、最も関連性の高いすべてのデータを1つのドキュメントにまとめてすばやく分析できるようにすることです。
ClusterControlを使用すると、日次システムレポート、パッケージアップグレードレポート、スキーマ変更レポート、バックアップと可用性などのクラスター間環境レポートをスケジュールできます。これらのレポートは、環境の安全性と運用性を維持するのに役立ちます。また、ギャップを修正する方法に関する推奨事項も表示されます。レポートは、SysOps、DevOps、または特定のシステムの状態に関する定期的なステータス更新を取得したいマネージャーに宛てて送信できます。
以下は、可用性に関してメールボックスに送信される毎日の運用レポートのサンプルです。
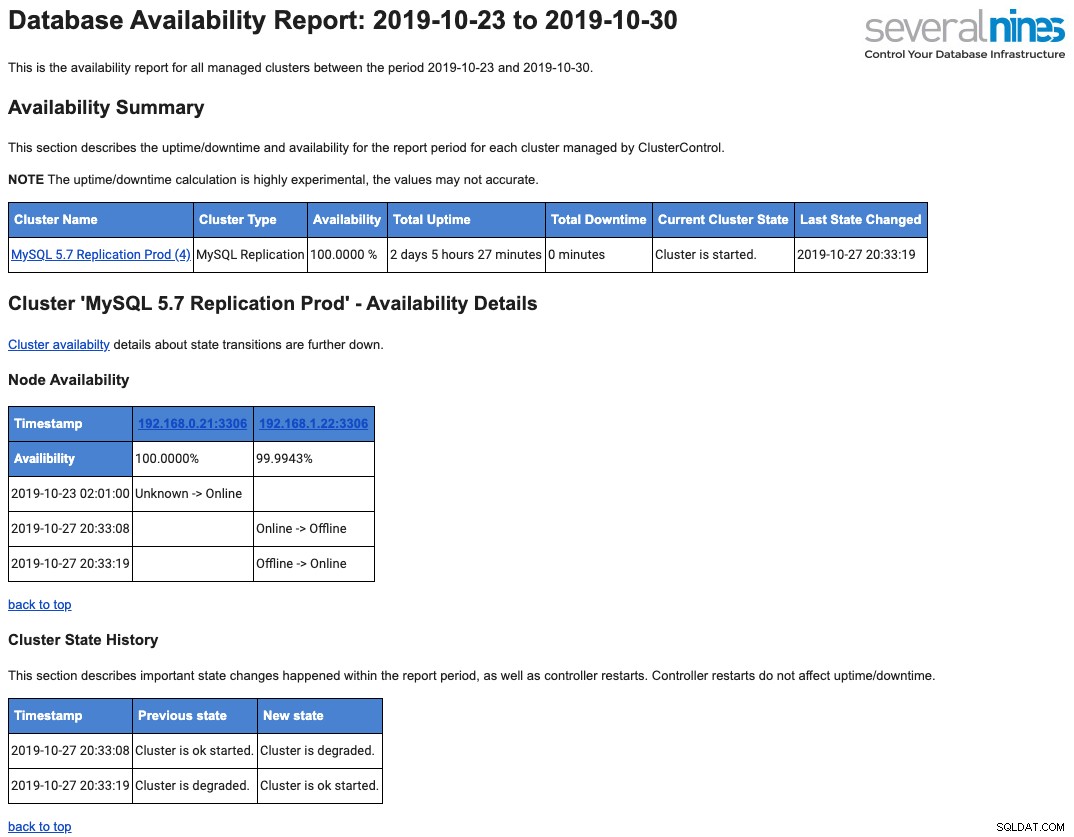
これについては、このブログ投稿「ClusterControlでのデータベース運用レポートの概要」で詳しく説明しています。
ClusterControlを使用すると、最新の完全バックアップまたは増分バックアップを介してスレーブ(新しいスレーブまたは壊れたスレーブ)をステージングできます。それほどエキサイティングではないように聞こえますが、100 GB以上の大規模なデータセットがある場合、この機能は非常に大きなものになります。スレーブを再同期するときの一般的な方法は、現在のマスターのバックアップをストリーミングすることです。これには、データベースのサイズによっては時間がかかります。これにより、マスターに追加の負担がかかり、マスターのパフォーマンスが危険にさらされる可能性があります。
バックアップを介してスレーブを再同期するには、[ノード]ページでスレーブノードを選択し、[ノードアクション]->[レプリケーションスレーブの再構築]->[バックアップからの再構築]に移動します。ドロップダウンには、PITR互換のバックアップのみが表示されます:
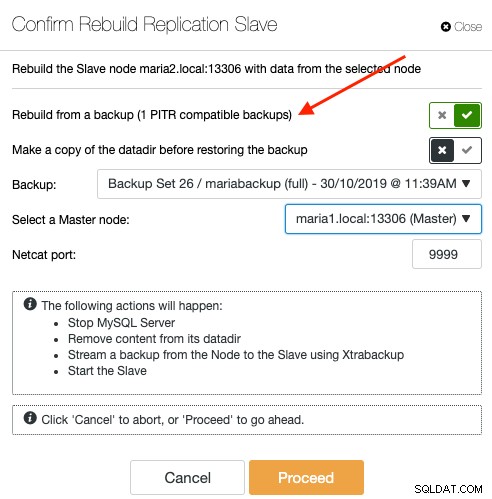
バックアップからスレーブを再同期しても、マスターに追加のオーバーヘッドは発生しません。ClusterControlは、バックアップをバックアップストレージの場所からスレーブに抽出してストリーミングし、最終的にスレーブとマスター間のレプリケーションリンクを構成します。レプリケーションリンクが確立されると、スレーブは後でマスターに追いつきます。マスターはプロセス全体を通して手つかずであり、[アクティビティ]->[ジョブ]で全体の進行状況を監視できます。
ガレラクラスターは、MySQLまたはMariaDBの高可用性を実装する場合に非常に人気がありますが、管理コマンドが間違っていると、悲惨な結果を招く可能性があります。さまざまな条件下でGaleraClusterをブートストラップする方法については、このブログ投稿をご覧ください。これは、Galera Clusterのブートストラップには多くの変数があり、細心の注意を払って実行する必要があることを示しています。そうしないと、データが失われたり、スプリットブレインが発生したりする可能性があります。 ClusterControlはデータベーストポロジを理解し、データベースクラスタを適切にブートストラップするために何をすべきかを正確に認識しています。 ClusterControlを介してクラスターをブートストラップするには、[クラスターアクション]-> [ブートストラップクラスター]をクリックします:
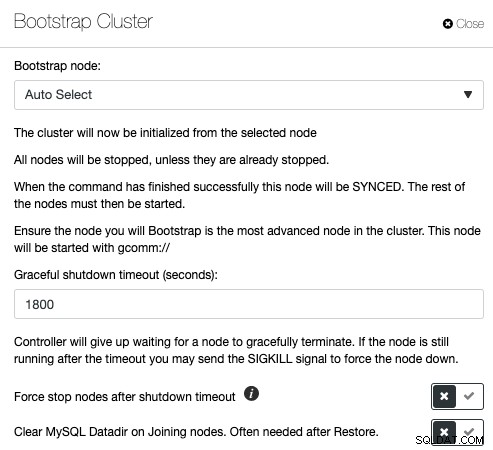
ClusterControlに適切なブートストラップノードを自動的に選択させるか、リストからデータベースノードの1つを選択して参照ノードにし、ジョイナーノードのMySQLデータディレクトリを消去してSSTを強制する初期ブートストラップを実行するオプションがあります。ブートストラップされたノード。ブートストラッププロセスが失敗した場合、ClusterControlはMySQLエラーログをプルします。
手動ブートストラップを実行する場合は、「最も高度なノードの検索」機能を使用して、ClusterControlによって報告された最も高度なノードでクラスターブートストラップ操作を実行することもできます。
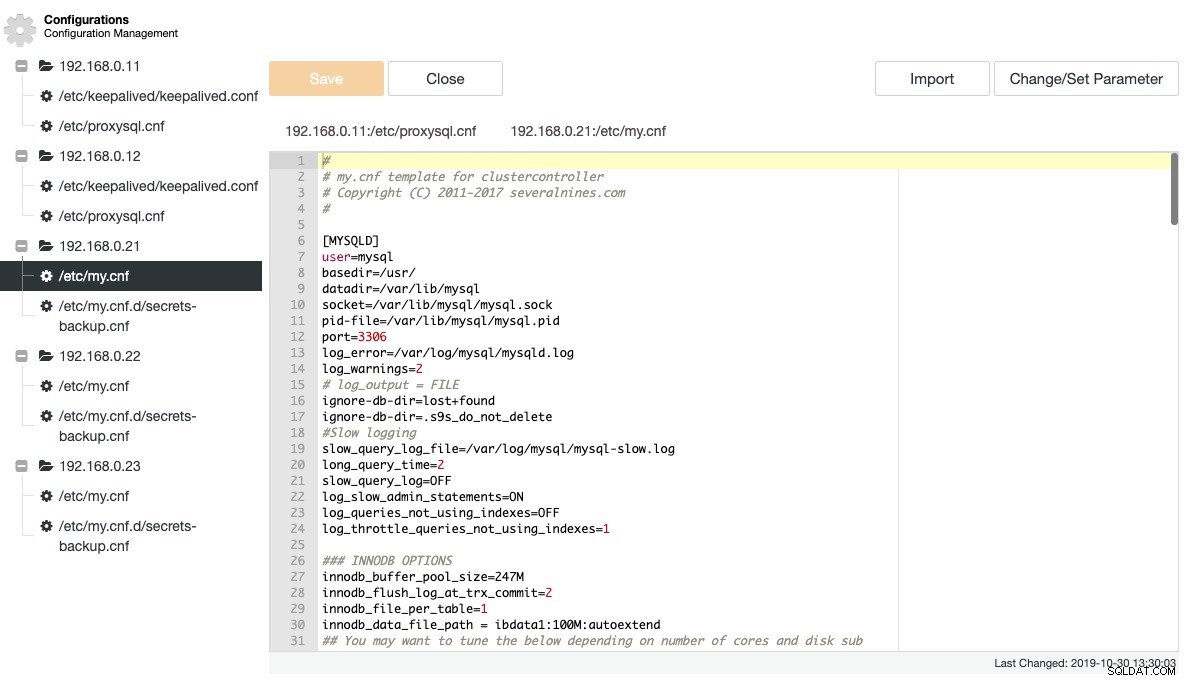
ClusterControlは、いくつかの重要な構成ファイルとログファイルを取得し、それらをClusterControl内のツリー構造で表示します。これらのファイルを一元的に表示することは、分散データベースのセットアップを効率的に理解してトラブルシューティングするための鍵です。これらのファイルをテーリング/グレッピングする従来の方法は、ClusterControlでは長い間使用されていません。次のスクリーンショットは、このクラスターに関連するすべての構成ファイルを1つのビューに一覧表示したClusterControlの構成ファイルマネージャーを示しています(もちろん、構文が強調表示されています)。
ClusterControlは、データベースクラスターの構成オプションを変更する際の反復性を排除します。複数のノードで構成オプションを変更することは、単一のインターフェースを介して実行でき、それに応じてデータベースノードに適用されます。 [パラメータの変更/設定]をクリックすると、変更するデータベースインスタンスを選択し、構成グループ、パラメータ、および値を指定できます。
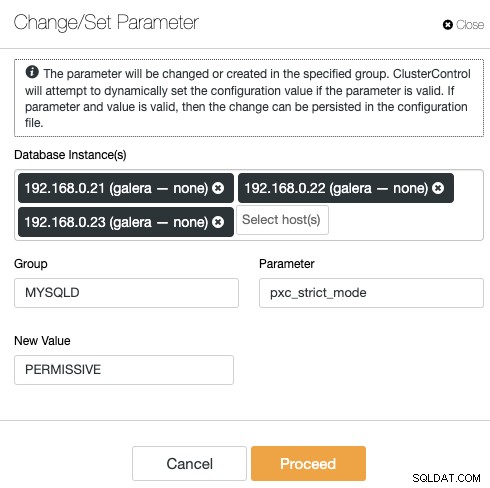
構成ファイルに新しいパラメーターを追加したり、既存のパラメーターを変更したりできます。オプションが変数検証プロセスに合格した場合、パラメーターは選択されたデータベースノードのランタイムと構成ファイルに適用されます。一部の変数ではサーバーの再起動が必要になる場合があり、その場合はClusterControlから通知されます。
ClusterControlを使用すると、既存のMySQL Galeraクラスターのクローンをすばやく作成できるため、他のクラスターにデータセットの正確なコピーを作成できます。 ClusterControlは、既存のクラスターをロックしたりダウンタイムを発生させたりすることなく、オンラインでクローン作成操作を実行します。同期が完了した後、両方のクラスターが互いに独立していることを除けば、クラスターのスケールアウト操作に似ています。クローン化されたクラスターは、必ずしも既存のクラスターと同じクラスターサイズである必要はありません。 「1ノードクラスタ」から始めて、後の段階でより多くのデータベースノードでスケールアウトすることができます。
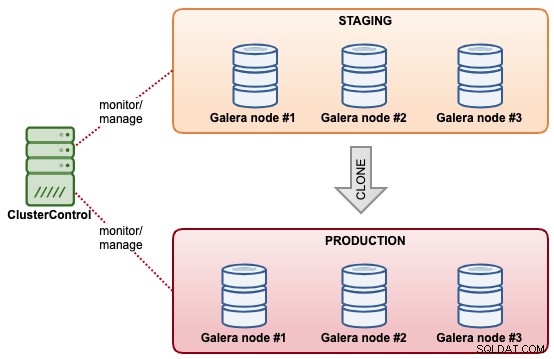
ClusterControlが提供するもう1つの同様の機能は、「バックアップからクラスターを作成」です。この機能は、ClusterControl 1.7.1で導入されました。特に、既存のバックアップから新しいクラスターを作成できるGaleraクラスターおよびPostgreSQLクラスター向けです。クラスターの複製とは異なり、この操作では、複製されたクラスターがソースクラスターと同じ状態にならないというトレードオフにより、ソースクラスターに追加の負荷がかかりません。
このトピックについては、このブログ投稿「MySQLまたはPostgreSQLデータベースクラスターのクローンを作成する方法」で詳しく説明しています。
ほとんどのデータベース管理ツールではデータベースのバックアップが可能であり、論理バックアップのみのデータベース復元をサポートしているのはほんの一握りです。 ClusterControlは、論理バックアップだけでなく、完全バックアップか増分バックアップかに関係なく、物理バックアップの完全復元もサポートします。物理バックアップの復元には、基本的にバックアップの準備、準備したデータのデータディレクトリへのコピー、正しい権限/所有権の割り当て、ノード全体のデータの一貫性を維持するための正しい順序での起動を含む、いくつかの重要な手順(特に増分バックアップ)が必要です。クラスタ内のすべてのメンバー。 ClusterControlは、これらすべての操作を自動的に実行します。
クラスタの一部ではない別のノードに物理バックアップを復元することもできます。 ClusterControlでは、このオプションは「バックアップからクラスターを作成」と呼ばれます。 「1ノードクラスタ」から始めて、別のサーバーで復元プロセスをテストしたり、データベースクラスタを別の場所にコピーしたりできます。
ClusterControlは、外部バックアップ(ClusterControlを介さずに作成されたバックアップ)の復元もサポートします。復元するときに、バックアップをClusterControlサーバーにアップロードし、バックアップファイルへの物理パスを指定するだけです。 ClusterControlが残りの処理を行います。
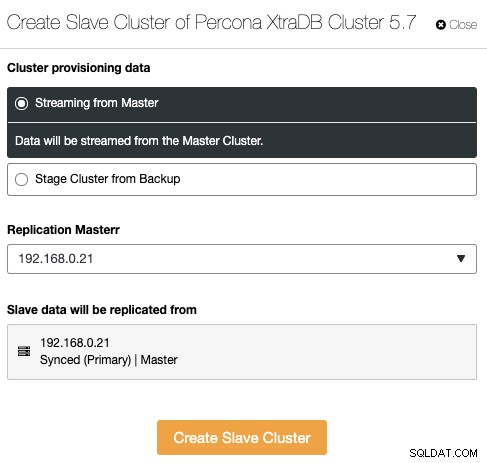
これは、ClusterControl1.7.4で導入された新機能です。 ClusterControlは、クラスタークラスターレプリケーションを処理および監視できるようになりました。これにより、基本的に、地理的に複数の場所にある複数のクラスターセット間で非同期データベースレプリケーションが拡張されます。クラスターはマスタークラスター(読み取り/書き込みを処理するアクティブクラスター)として設定でき、スレーブクラスターは読み取り専用クラスター(読み取りも処理できるスタンバイクラスター)として設定できます。 ClusterControlは、Galera Clusterの非同期クラスタークラスターレプリケーション(バイナリログを有効にする必要があります)と、PostgreSQLストリーミングレプリケーションのマスタースレーブレプリケーションもサポートしています。
別のクラスターから複製された新しいクラスターを作成するには、[クラスターアクション]-> [スレーブクラスターの作成]に移動します:
上記の展開の結果は、データベースクラスターリストダッシュボードに明確に表示されます:
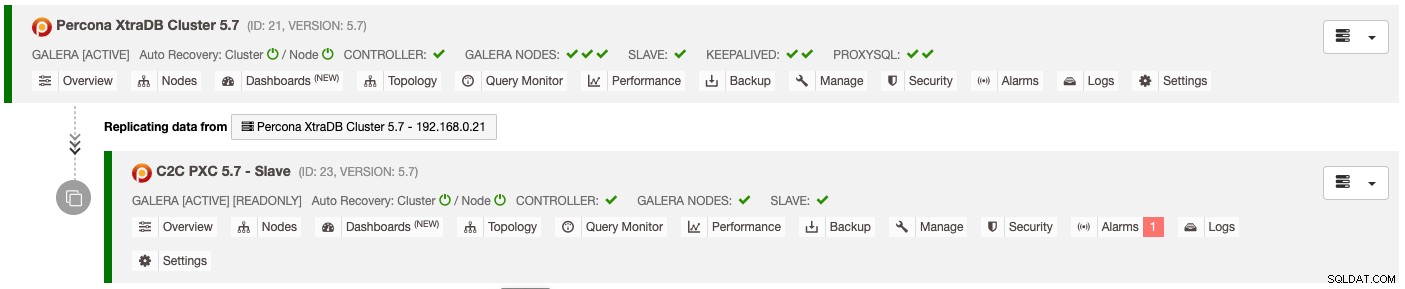
スレーブクラスターは自動的に読み取り専用として構成され、プライマリクラスターから複製され、スタンバイクラスターとして機能します。災害がプライマリクラスターに発生し、セカンダリサイトをアクティブ化する場合は、[ノード]-> [ノードアクション]ドロップダウンで使用できる[読み取り専用を無効にする]メニューを選択して、アクティブクラスターとして昇格させます。