ページフォールトは、大規模なデータを含む大規模なアプリケーションで主に発生する一般的なエラーです。これは、MongoDBデータベースが仮想メモリからではなく物理メモリからデータを読み取るときに発生します。ページフォールトエラーは、MongoDBがデータベースのアクティブなメモリで利用できないデータを取得しようとしたときに発生するため、ディスクからの読み取りを強制されます。これにより、スループット操作の待ち時間が長くなり、クエリが遅れているように見えます。
チューニングによるMongoDBのパフォーマンスの調整は、アプリケーションの実行を最適化する重要なコンポーネントです。データベースは、ディスクに保持されている情報を処理するように拡張されていますが、ディスクにアクセスしようとして、RAMに大量のデータをキャッシュするのが習慣です。データベースからのデータの保存とアクセスにはコストがかかるため、アプリケーションがデータにアクセスできるようにする前に、まず情報をディスクに保存する必要があります。ディスクはRAMデータキャッシュと比較して遅いという事実のために、結果としてプロセスはかなりの時間を消費します。したがって、MongoDBは、ページフォールトの発生をすべてのインシデントの要約として1秒で報告するように設計されています
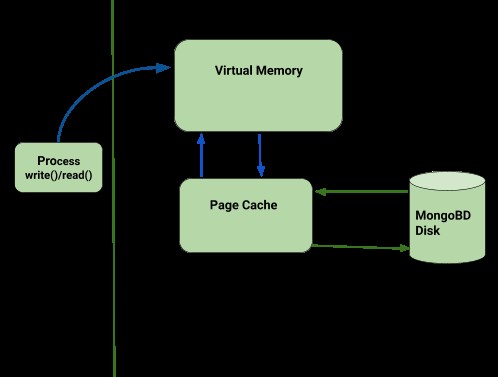
MongoDBのデータ移動トポロジ
クライアントからのデータは仮想メモリに移動し、ページキャッシュが書き込まれるときにデータを読み取り、次の図に示すようにデータがディスクに保存されます。
MongoDBページフォールトを見つける方法
ページフォールトは、MongoDBのデータの一貫性を保証するロックパフォーマンスを通じて検出できます。特定の操作がキューに入れられるか長時間実行されると、MongoDBのパフォーマンスが低下し、ロックを待機するときに操作の速度が低下します。ロック関連の遅延は散発的であり、アプリケーションのパフォーマンスに影響を与えることがあるため、これは速度低下につながります。ロックが分割されている場合(locks.timeAcquiringMicros by locks.acquireWaitCount)、ロックはアプリケーションのパフォーマンスに影響を与えます。これにより、特定のロックモードを待機する平均時間が得られます。 Locks.deadLockCountは、経験したすべてのロック取得の行き詰まりの合計を示します。 globalLock.totalTimeが調和的に高い場合、ロックを期待するリクエストが多数あります。より多くのリクエストがロックを待機するにつれて、より多くのRAMが消費され、これがページフォールトにつながります。
mem.mappedを使用して、開発者がmongodが使用している合計メモリを精査できるようにすることもできます。 Mem.mappedは、MMAPv1ストレージエンジンのメモリ量(メガバイト(MB))をチェックするためのサーバーオペレーターです。 mem.mapped演算子がシステムメモリの合計量よりも大きい値を示した場合、そのような大量のメモリ使用量はデータベースのページフォールトにつながるため、ページフォールトが発生します。
MongoDBでページフォールトが発生する方法
MongoDBでのページの読み込みは、空きメモリが不足している場合に備えて、空きメモリの可用性に依存します。オペレーティングシステムは次のことを行う必要があります。
- データベースが使用を停止したページを探し、そのページをメモリディスクに書き込みます。
- ディスクから読み取った後、要求されたページをメモリにロードします。
これらの2つのアクティビティは、ページの読み込み中に行われるため、アクティブメモリでの読み取りに比べて多くの時間を消費し、ページフォールトが発生します。
以下は、ページフォールトを解決するためのいくつかの方法です。
- 十分なRAMを備えたデバイスに垂直方向にスケーリングするか、水平方向にスケーリングする:特定のデータセットに十分なRAMがない場合、正しいアプローチは、サーバーにリソースを追加するために、RAMが多いデバイスに垂直方向にスケーリングしてRAMメモリを増やすことです。垂直スケーリングは、複数のサーバーに負荷を分散させないことでMongoDBのパフォーマンスを向上させるための最良かつ簡単な方法の1つです。垂直方向にスケーリングするとRAMが増えるため、水平方向にスケーリングすると、シャーディングされたクラスターにシャードを追加できます。簡単に言うと、水平スケーリングとは、データベースがさまざまなチャンクに分割され、複数のサーバーに格納される場所です。水平スケーリングにより、開発者はその場でサーバーを追加できます。これにより、ダウンタイムがゼロにならないため、データベースのパフォーマンスが大幅に向上します。垂直スケーリングと水平スケーリングは、データベースの操作中に動作するメモリを増やすことにより、ページフォールトの発生を減らします。
- データの適切なインデックス作成:コレクションスキャンを引き起こさない効率的なクエリが確実に行われるように、適切なインデックスを使用します。適切なインデックス付けにより、データベースがコレクション内の各ドキュメントを反復処理しないようにし、ページフォールトエラーの発生の可能性を解決します。コレクションスキャンは、コレクション全体がRAMに読み込まれるときにクエリエンジンによって検査されるため、ページフォールトエラーが発生します。コレクションスキャンのほとんどのドキュメントはアプリに返されないため、後続のクエリごとに不要なページフォールトが発生し、回避するのは簡単ではありません。さらに、過剰なインデックスはRAMの非効率的な使用につながる可能性があり、これはページフォールトエラーにつながる可能性があります。したがって、開発者がページフォールトエラーを解決しようとする場合は、適切なインデックス作成が最も重要です。 MongoDBは、データベースを使用するときにデプロイする必要のあるインデックスを決定するための支援を提供します。これらは、ユーザーと共有ユーザーのインデックス作成方法に関する必要な情報を提供するSlowQueryAnalyzerの両方を提供します。
- MongoDBの最新バージョンに移行してから、アプリケーションをWiredTigerに移動します。これは、ページフォールトが新しいバージョンやWiredTigerとは対照的に、MMAPv1ストレージエンジンでのみ一般的であるため、ページフォールトエラーの発生を回避する場合に必要です。 MMAPv1ストレージエンジンは非推奨になり、MongoDBはそれをサポートしなくなりました。 WiredTigerはMongoDBの現在のデフォルトのストレージエンジンであり、MMAPv1ストレージエンジンと比較してはるかに優れたMultiVersionConcurrencyControlを備えています。 WiredTigerを使用すると、MongoDBはファイルシステムキャッシュと、1GB(50%0f(RAM-1GB))または256MBの非常に大きなサイズのWiredTiger内部キャッシュの両方を使用できます。
- システムで使用できるRAMの合計を追跡します。これは、NewRelicモニタリングのGoogleCloudMonitoringなどのサービスを使用して実行できます。さらに、BindPlaneは前述のクラウド監視サービスで利用できます。監視システムの使用は、発生したページフォールトに対応するのではなく、発生する前にページフォールトに対抗できるようにする予防的な手段です。 BindPlaneを使用すると、モニターはページフォールトの発生に対して一定のアラートを設定できます。また、アラートにより、インデックスの数、インデックスサイズ、およびファイルサイズを認識できます。
- データが一般的なワーキングセットに構成され、推奨よりも多くのRAMを使用しないようにします。 MongoDBは、頻繁にアクセスされるデータとインデックスが割り当てられたメモリに完全に収まる場合に最適に機能するデータベースシステムです。 RAMサイズは、データベースのパフォーマンスを最適化する際の重要な側面であるため、アプリをデプロイする前に、常に十分なRAMメモリがあることを確認する必要があります。
- シャードを追加するか、シャードクラスターをデプロイすることで、mongodインスタンス間で負荷を分散します。ターゲットコレクションが配置されている場所でシェーディングを有効にすることは非常に重要です。まず、mongoシェルでmongoに接続し、以下の方法を使用します。
-
sh.shardCollection()次に、このメソッドでインデックスを作成します。
作成されたインデックスはシャードキーをサポートします。つまり、作成されたコレクションがすでにデータを受信または保存している場合です。ただし、コレクションにデータがない(空の)場合は、以下のメソッドを使用して、ssh.shardCollectionの一部としてインデックスを作成します:sh.shardCollection()db.collection.createIndex(keys, options) - これに続いて、mongoDBが提供する2つの戦略のいずれかが行われます。
- ハッシュシェーディング
sh.shardCollection("<database>.<collection>", { <shard key field> : "hashed" } ) - 範囲ベースのシェーディング
sh.shardCollection("<database>.<collection>", { <shard key field> : 1, ... } )
- ハッシュシェーディング
-
- シャードを追加するか、シャードクラスターをデプロイして負荷を分散します
- MongoDBの新しいバージョンに移動してから、WiredTigerに進みます
- RAMが多いデバイスの場合は垂直方向または水平方向にスケーリングします
- 推奨RAMを使用し、使用済みRAMスペースを追跡します
いくつかのページフォールト(単独)には短時間かかりますが、多数のページフォールト(集約)がある状況では、データベースが大量のデータを読み取っていることを示しています。ディスク。集約が発生すると、ページフォールトにつながるMongoBD読み取りロックがさらに発生します。
MongoDBを使用する場合、システムのRAMのサイズとクエリの数は、アプリケーションのパフォーマンスに大きく影響する可能性があります。 MongoDBのアプリケーションのパフォーマンスは、物理メモリで使用可能なRAMに大きく依存しており、アプリケーションが単一のクエリを実行するのにかかる時間に影響を与えます。 RAMが十分にあると、ページフォールトの発生が減少し、アプリケーションのパフォーマンスが向上します。