MongoDBは、さまざまな入力データセットソースをサポートするNoSQLデータベースです。柔軟なJSONのようなドキュメントにデータを保存できます。つまり、フィールドやメタデータはドキュメントごとに異なり、データ構造は時間の経過とともに変更される可能性があります。ドキュメントモデルは、アプリケーションコード内のオブジェクトにマッピングすることにより、データを簡単に操作できるようにします。 MongoDBは、そのコアで分散データベースとしても知られているため、高可用性、水平スケーリング、および地理的分散が組み込まれており、使いやすいです。モデルトレーニングのパラメータをシームレスに変更する機能が付属しています。データサイエンティストは、データの構造化をこのモデル生成と簡単に統合できます。
機械学習とは何ですか?
機械学習は、コンピューターに人間と同じように学習して行動させ、時間の経過とともに自律的に学習を改善する科学です。学習のプロセスは、データのパターンを探し、私たちが提供する例に基づいて将来より良い決定を下すために、例、直接の経験、または指導などの観察またはデータから始まります。主な目的は、人間の介入や支援なしにコンピューターが自動的に学習し、それに応じてアクションを調整できるようにすることです。
MongoDBは、MongoDBからのデータを使用して機械学習モデルを構築する開発者とデータサイエンティスト向けに、ネイティブドライバーと認定コネクタの両方を提供します。 PyMongoは、MongoDB構文をPythonコードに埋め込むための優れたライブラリです。 MongoDBのすべての関数とメソッドをインポートして、機械学習コードで使用できます。これは、単一のコードで多言語機能を取得するための優れた手法です。追加の利点は、これらのプログラミング言語の基本的な機能を使用して、効率的なアプリケーションを作成できることです。
豊富なセカンダリインデックスを備えたMongoDBクエリ言語を使用すると、開発者は、データを多次元でクエリおよび分析できるアプリケーションを構築できます。複雑な集計とMapReduceジョブを介して、単一のキー、範囲、テキスト検索、グラフ、地理空間クエリでデータにアクセスでき、ミリ秒単位で応答を返します。
分散データベースクラスター全体でデータ処理を並列化するために、MongoDBは集約パイプラインとMapReduceを提供します。 MongoDB集約パイプラインは、データ処理パイプラインの概念に沿ってモデル化されています。ドキュメントは、MongoDB内で実行されるネイティブ操作を使用して、ドキュメントを集約された結果に変換する多段階パイプラインに入ります。最も基本的なパイプラインステージは、クエリのように動作するフィルターと、出力ドキュメントの形式を変更するドキュメント変換を提供します。他のパイプライン操作は、特定のフィールドごとにドキュメントをグループ化および並べ替えるためのツールと、ドキュメントの配列を含む配列のコンテンツを集約するためのツールを提供します。さらに、pipselineステージでは、ドキュメントのコレクション全体の平均または標準偏差の計算や文字列の操作などのタスクに演算子を使用できます。 MongoDBは、カスタムJavaScript関数を使用してマップを実行し、ステージを削減する、データベース内のネイティブMapReduce操作も提供します。
MongoDBは、ネイティブクエリフレームワークに加えて、ApacheSpark用の高性能コネクタも提供します。このコネクターは、Python、R、Scala、Javaを含むSparkのすべてのライブラリーを公開します。 MongoDBデータは、機械学習、グラフ、ストリーミング、SQLAPIを使用して分析するためのDataFramesおよびDatasetsとして具体化されます。
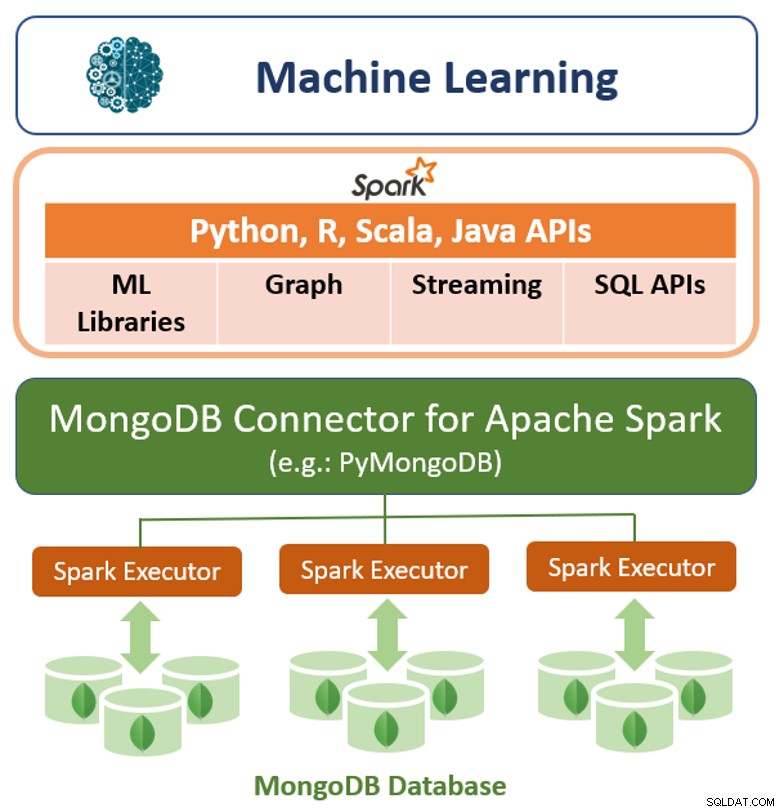
Apache Spark用のMongoDBコネクターは、MongoDBの集約パイプラインとセカンダリを利用できますインデックスを作成して、必要な範囲のデータのみを抽出、フィルタリング、処理します。たとえば、特定の地域にいるすべての顧客を分析します。これは、セカンダリインデックスまたはデータベース内集計のいずれもサポートしない単純なNoSQLデータストアとは大きく異なります。このような場合、Sparkプロセスに必要なデータのサブセットのみであっても、Sparkは単純な主キーに基づいてすべてのデータを抽出する必要があります。これは、データサイエンティストやエンジニアにとって、処理のオーバーヘッドが増え、ハードウェアが増え、調査にかかる時間が長くなることを意味します。大規模な分散データセット全体のパフォーマンスを最大化するために、Apache Spark用のMongoDBコネクタは、復元力のある分散データセット(RDD)をソースMongoDBノードと同じ場所に配置できるため、クラスター全体のデータ移動を最小限に抑え、レイテンシーを削減できます。
パフォーマンス、スケーラビリティ、冗長性
パフォーマンスが高くスケーラブルなデータベースレイヤーの上に機械学習プラットフォームを構築することで、モデルのトレーニング時間を短縮できます。 MongoDBは、スループットを最大化し、機械学習ワークロードのレイテンシーを最小化するための多くのイノベーションを提供します。
- WiredTigerは、MongoDBのデフォルトのストレージエンジンとして知られており、世界で最も広く展開されている組み込みデータ管理ソフトウェアであるBerkeleyDBのアーキテクトによって開発されました。 WiredTigerは、最新のマルチコアアーキテクチャに対応しています。 WiredTigerは、ハザードポインター、ロックフリーアルゴリズム、高速ラッチ、メッセージパッシングなどのさまざまなプログラミング手法を使用して、CPUコアおよびクロックサイクルごとの計算作業を最大化します。ディスク上のオーバーヘッドとI/Oを最小限に抑えるために、WiredTigerはコンパクトなファイル形式とストレージ圧縮を使用します。
- レイテンシーに最も敏感な機械学習アプリケーションの場合、MongoDBはインメモリーストレージエンジンで構成できます。 WiredTigerに基づくこのストレージエンジンは、従来のディスクベースのデータベースが提供する豊富なクエリの柔軟性、リアルタイム分析、およびスケーラブルな容量を犠牲にすることなく、インメモリコンピューティングの利点をユーザーに提供します。
- モデルトレーニングを並列化し、入力データセットを単一ノードを超えてスケーリングするために、MongoDBは、コモディティハードウェアのクラスター全体に処理とデータを分散するシャーディングと呼ばれる手法を使用します。 MongoDBシャーディングは完全に弾力性があり、入力データセットが大きくなるか、ノードが追加および削除されると、クラスター全体でデータのバランスが自動的に調整されます。
- MongoDBクラスター内で、各シャードからのデータは、別々のノードでホストされている複数のレプリカに自動的に分散されます。 MongoDBレプリカセットは、障害が発生した場合にトレーニングデータを回復するための冗長性を提供し、チェックポイントのオーバーヘッドを削減します。
MongoDBの調整可能な一貫性
MongoDBはデフォルトで強い整合性があり、機械学習アプリケーションがデータベースに書き込まれた内容をすぐに読み取ることができるため、結果整合性のあるシステムによって課せられる開発者の複雑さを回避できます。強一貫性は、機械学習アルゴリズムに最も正確な結果を提供します。ただし、一部のシナリオでは、MongoDBセカンダリレプリカセットメンバーのクラスター全体にクエリを分散することで、特定のパフォーマンス目標に対して一貫性をトレードすることが許容されます。
MongoDBのドキュメントデータモデルを使用すると、開発者やデータサイエンティストは、データ品質を管理するための高度な検証ルールを放棄することなく、データベース内のあらゆる形式の構造のデータを簡単に保存および集約できます。スキーマは、コストのかかるスキーマの変更やリレーショナルデータベースシステムによる再設計に起因するアプリケーションやデータベースのダウンタイムなしで動的に変更できます。
モデルをデータベースに保存し、Pythonを使用してモデルをロードすることも、簡単で非常に必要な方法です。 MongoDBはオープンソースのドキュメントデータベースであり、主要なNoSQLデータベースでもあるため、MongoDBを選択することも利点です。 MongoDBは、apachespark分散フレームワークのコネクターとしても機能します。
MongoDBの動的な性質
MongoDBの動的な性質により、機械学習アプリケーションの開発におけるデータベース操作タスクでの使用が可能になります。これは、データセットとデータベースの分析を実行するための非常に効率的で簡単な方法です。分析の出力は、機械学習モデルのトレーニングに使用できます。データアナリストと機械学習プログラマーがMongoDBを習得し、それをさまざまなアプリケーションに適用することをお勧めします。 MongoDBの集約フレームワークは、多数のアプリケーションのデータ分析を実行するためのデータサイエンスワークフローに使用されます。
MongoDBは、柔軟なデータモデル、豊富なプログラミング、データモデル、クエリモデル、および機械学習アルゴリズムのトレーニングと使用を従来のリレーショナルデータベースよりもはるかに簡単にする調整可能な一貫性など、いくつかの異なる機能を提供します。 MongoDBをバックエンドデータベースとして実行すると、機械学習データの保存と強化が可能になり、永続性と効率の向上が可能になります。