Hadoopクラスターのすべてを学びたいですか?
Hadoopは、コモディティハードウェアのクラスター全体で大量のデータを分析および保存するためのソフトウェアフレームワークです。この記事では、Hadoopクラスターについて学習します。
まず、クラスターの概要から始めましょう。
クラスターはノードのコレクションです。ノードは、ネットワーク内の接続/交差点に他なりません。
コンピュータークラスターは、ネットワークに接続され、相互に通信できるコンピューターの集合であり、単一のシステムとして機能します。
Hadoopクラスターとは何ですか?
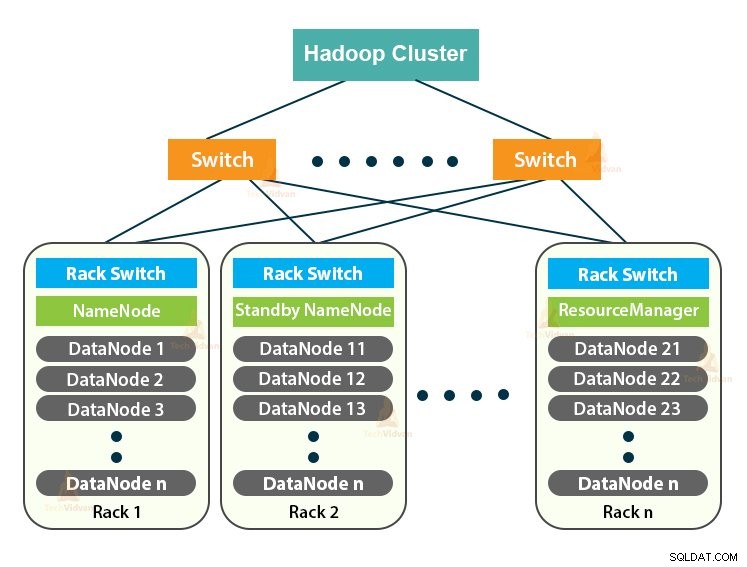
Hadoopクラスターは、大量のデータを分散して処理するために使用される単なるコンピュータークラスターです。
これは、分散コンピューティング環境で大量の非構造化データまたは構造化データを保存および分析するために設計された計算クラスターです。
Hadoopクラスターはシェアードナッシングシステムとも呼ばれます ネットワーク帯域幅を除いて、クラスター内のノード間で何も共有されないためです。これにより、処理の待ち時間が短縮されます。
したがって、大量のデータに対するクエリを処理する必要がある場合、クラスター全体のレイテンシーが最小限に抑えられます。
ここで、Hadoopクラスターのアーキテクチャーを調べてみましょう。
Hadoopクラスターはマスタースレーブアーキテクチャに従います。マスターノード、スレーブノード、クライアントノードで構成されています。
1。 Hadoopクラスターのマスター
Hadoopクラスターのマスターは、メモリとCPUの構成が高い高出力マシンです。 NameNodeとResourceManagerの2つのデーモンは、マスターノードで実行されます。
a。 NameNodeの機能
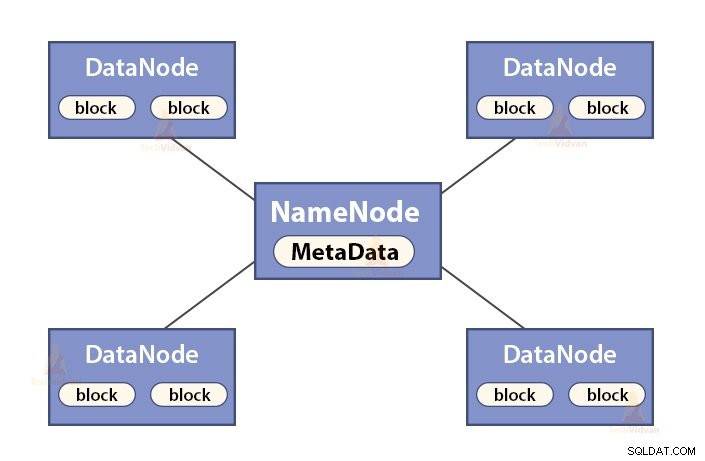
NameNodeは、 Hadoop HDFSのマスターノードです。 。 NameNodeは、ファイルシステムの名前空間を管理します。ファイルシステムのメタデータをメモリに保存して、すばやく取得できるようにします。したがって、ハイエンドマシンで構成する必要があります。
NameNodeの機能は次のとおりです。
- ファイルシステムの名前空間を管理します
- ファイルのブロック、ブロックの場所、権限などに関するメタデータを保存します。
- ファイルやディレクトリのオープン、クローズ、名前変更などのファイルシステム名前空間操作を実行します。
- DataNodeを維持および管理します。
b。リソースマネージャーの機能
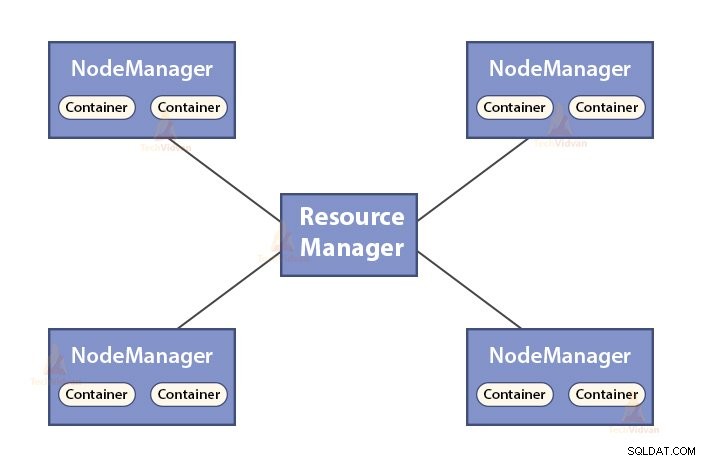
- ResourceManagerはYARNのマスターデーモンです。
- ResourceManagerは、システム内のすべてのアプリケーション間でリソースを調停します。
- クラスター内のライブノードとデッドノードを追跡します。
2。 Hadoopクラスターのスレーブ
Hadoopクラスターのスレーブは、安価なコモディティハードウェアです。 DataNodesとYARNNodeManagersの2つのデーモンは、スレーブノードで実行されます。
a。 DataNodeの機能
- DataNodesは、実際のビジネスデータを格納します。ファイルのブロックを保存します。
- NameNodeからの指示に基づいて、ブロックの作成、削除、複製を実行します。
- DataNodeは、クライアントの読み取り/書き込み操作を提供します。
b。 NodeManagerの機能
- NodeManagerはYARNのスレーブデーモンです。
- コンテナを担当し、リソースの使用状況(CPU、ディスク、メモリ、ネットワークなど)を監視し、ResourceManagerに報告します。
- NodeManagerは、実行中のノードの状態もチェックします。
3。 Hadoopクラスターのクライアントノード
Hadoopのクライアントノードは、マスターノードでもスレーブノードでもありません。すべてのクラスター設定でHadoopがインストールされています。
クライアントノードの機能
- クライアントノードはデータをHadoopクラスターにロードします。
- MapReduceジョブを送信し、そのデータの処理方法を説明します。
- 処理の完了後にジョブの結果を取得します。
ノードを追加することで、Hadoopクラスターをスケールアウトできます。これにより、Hadoopは線形にスケーラブルになります 。ノードを追加するたびに、それに応じてスループットが向上します。 「n」個のノードがある場合、1個のノードを追加すると、(1 / n)追加の計算能力が得られます。
1。シングルノードHadoopクラスター
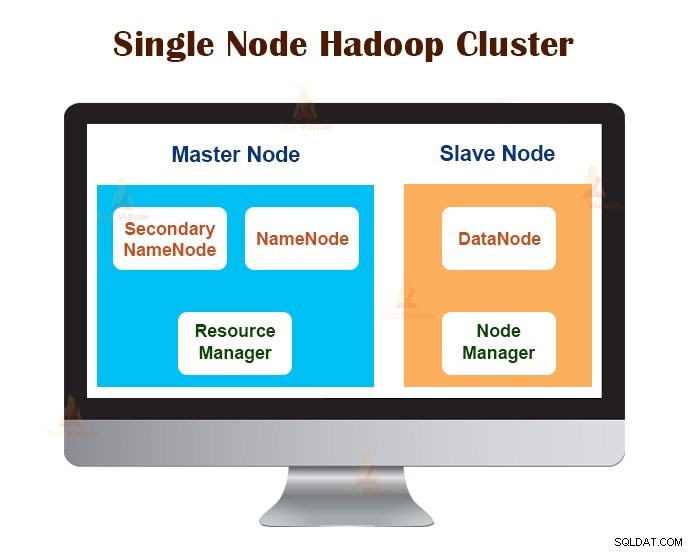
シングルノードHadoopクラスターは単一のマシンにデプロイされます。 NameNode、DataNode、ResourceManager、NodeManagerなどのすべてのデーモンは同じマシン/ホストで実行されます。
単一ノードのクラスター設定では、すべてが単一のJVMインスタンスで実行されます。 Hadoopユーザーは、JAVA_HOME変数を設定する以外に構成設定を行う必要はありませんでした。
単一ノードのHadoopクラスターのデフォルトのレプリケーション係数は常に1です。
2。マルチノードHadoopクラスター
マルチノードHadoopクラスターは複数のマシンにデプロイされます。マルチノードHadoopクラスター内のすべてのデーモンが稼働しており、異なるマシン/ホストで実行されています。
マルチノードHadoopクラスターは、マスタースレーブアーキテクチャに従います。デーモンNamenodeとResourceManagerは、ハイエンドのコンピューターマシンであるマスターノードで実行されます。
デーモンDataNodesとNodeManagersは、安価なコモディティハードウェアであるスレーブノード(ワーカーノード)で実行されます。
マルチノードHadoopクラスターでは、マスターサーバーの物理的な場所に関係なく、スレーブマシンは任意の場所に存在できます。
HDFS通信プロトコルは、TCP/IPプロトコルの上に階層化されています。クライアントは、NameNodeマシンの構成可能なTCPポートを介してNameNodeとの接続を確立します。
Hadoopクラスターは、ClientProtocolを介してクライアントへの接続を確立します。さらに、DataNodeはDataNodeプロトコルを使用してNameNodeと通信します。
リモートプロシージャコール(RPC)の抽象化は、クライアントプロトコルとDataNodeプロトコルをラップします。設計上、NameNodeはRPCを開始しません。クライアントまたはDataNodeによって発行されたRPCリクエストにのみ応答します。
Hadoopクラスターを構築するためのベストプラクティス
Hadoopクラスターのパフォーマンスは、CPU、メモリ、ネットワーク帯域幅、ハードドライブ、およびその他の適切に構成されたソフトウェアレイヤーを使用する適切なディメンションのハードウェアリソースに基づくさまざまな要因に依存します。
Hadoopクラスターの構築は簡単な作業ではありません。適切なハードウェアの選択、Hadoopクラスターのサイズ設定、Hadoopクラスターの構成などのさまざまな要素を考慮する必要があります。
それぞれを詳しく見ていきましょう。
1。 Hadoopクラスターに適したハードウェアの選択
多くの組織は、Hadoopインフラストラクチャをセットアップするときに、最適化されたHadoop環境をセットアップするために購入する必要のあるマシンの種類と、使用する必要のある理想的な構成を認識していないため、窮地に立たされています。
Hadoopクラスターに適切なハードウェアを選択するには、次の点を考慮する必要があります。
- クラスターが処理するデータの量。
- クラスターが処理するワークロードのタイプ(CPUバウンド、I / Oバウンド)。
- データコンテナなどのデータストレージ方法論、使用されているデータ圧縮技術(ある場合)。
- データ保持ポリシー、つまり、データをフラッシュする前にデータを保持する期間。
2。 Hadoopクラスターのサイズ設定
Hadoopクラスターのサイズを決定するには、HadoopユーザーがHadoopクラスターで処理するデータ量を重要な考慮事項にする必要があります。
処理するデータの量を知ることにより、データを効率的に処理するために必要なノードの数と、各ノードに必要なメモリ容量を決定するのに役立ちます。パフォーマンスと承認されたハードウェアのコストのバランスをとる必要があります。
3。 Hadoopクラスターの構成
Hadoopクラスターの理想的な構成を見つけるのは簡単な作業ではありません。 Hadoopフレームワークは、実行中のクラスターとジョブに適合させる必要があります。
Hadoopクラスターの理想的な構成を決定する最良の方法は、ベースラインを取得するために使用可能なデフォルト構成でHadoopジョブを実行することです。その後、ジョブ履歴ログファイルを分析して、リソースの弱点があるかどうか、またはジョブの実行にかかる時間が予想よりも長いかどうかを確認できます。
その場合は、構成を変更します。同じプロセスを繰り返すことで、ビジネス要件に最適なHadoopクラスター構成を調整できます。
Hadoopクラスターのパフォーマンスは、デーモンに割り当てられたリソースに大きく依存します。中小規模のデータコンテキストの場合、Hadoopは各DataNodeに1つのCPUコアを予約しますが、長いデータセットの場合、HDFSおよびMapReduceデーモン用に各DataNodeに2つのCPUコアを割り当てます。
Hadoopクラスターを本番環境にデプロイすると、ボリューム、多様性、速度のすべての次元に沿ってスケーリングする必要があることは明らかです。
本番環境に対応するために必要なさまざまな機能は、24時間体制の可用性、堅牢性、管理性、およびパフォーマンスです。 Hadoopクラスター管理はビッグデータイニシアチブの主要な側面です。
Hadoopクラスター管理に最適なツールには、次の機能が必要です。-
- 24時間365日の高可用性、リソースプロビジョニング、多様なセキュリティ、ワークロード管理、ヘルスモニタリング、パフォーマンスの最適化を保証する必要があります。また、1つ以上のノード間でジョブのスケジューリング、ポリシー管理、バックアップ、およびリカバリを提供する必要があります。
- 負荷分散、ホットスタンバイ、再同期、自動フェイルオーバーを備えた冗長HDFSNameNodeの高可用性を実装します。
- アプリケーションがすでに最大化されているHadoopクラスター上のリソースの不均衡なシェアを取得するのを防ぐポリシーベースの制御を適用します。
- Hadoopクラスター上でのソフトウェアレイヤーのデプロイを管理するための回帰テストの実行。これは、ジョブやデータがクラッシュしたり、日常業務でボトルネックが発生したりしないようにするためです。
Hadoopクラスターが提供するさまざまなメリットは次のとおりです。
1。スケーラブル
Hadoopクラスターはスケーラブルです。ダウンタイムや余分な労力をかけずに、Hadoopクラスターに任意の数のノードを追加できます。ノードを追加するたびに、それに応じてスループットが向上します。
2。堅牢性
Hadoopクラスターは、信頼性の高いストレージで最もよく知られています。 DataNode障害、NameNode障害、ネットワークパーティションなどの場合でも、データを確実に保存できます。 DataNodeは定期的にハートビート信号をNameNodeに送信します。
ネットワークパーティションでは、一連のDataNodeがNameNodeから切り離されます。これにより、NameNodeはこれらのDataNodeからハートビートを受信しません。 NameNodeは、これらのDataNodeを停止していると見なし、I/O要求を転送しません。
また、これらのDataNodeに格納されているブロックのレプリケーション係数は、指定された値を下回っています。その結果、NameNodeはこれらのブロックのレプリケーションを開始し、障害から回復します。
3。クラスターのリバランス
Hadoop HDFSアーキテクチャは、クラスターのリバランスを自動的に実行します。 DataNodeの空き領域がしきい値レベルを下回ると、HDFSアーキテクチャは、十分な領域が利用可能な他のDataNodeにデータを自動的に移動します。
4。費用対効果の高い
Hadoopクラスターのセットアップは、安価なコモディティハードウェアで構成されているため、費用対効果が高くなります。どの組織でも、高価なサーバーハードウェアに多くの費用をかけることなく、強力なHadoopクラスターを簡単にセットアップできます。
また、分散ストレージトポロジを備えたHadoopクラスターは、従来のシステムの制限を克服します。限られたストレージは、システムに安価なストレージユニットを追加するだけで拡張できます。
5。柔軟
Hadoopクラスターは、構造化、半構造化、非構造化のいずれかのタイプのデータを処理でき、ギガバイトからペタバイトまでのサイズのデータを処理できるため、柔軟性が高くなっています。
6。高速処理
Hadoopクラスターでは、分散環境でデータを並列処理できます。これにより、Hadoopに高速データ処理機能が提供されます。 Hadoopクラスターは、数分の1秒以内にテラバイトまたはペタバイトのデータを処理できます。
7。データの整合性
バグのあるソフトウェア、ストレージデバイスの障害などによるデータブロックの破損をチェックするために、Hadoopクラスターはファイルの各ブロックにチェックサムを実装します。破損したブロックが見つかった場合は、同じブロックのレプリカを含む別のDataNodeからブロックを探します。したがって、Hadoopクラスターはデータの整合性を維持します。
概要
この記事を読んだ後、Hadoopクラスターはビッグデータの分析と保存のために設計された特別な計算クラスターであると言えます。 Hadoopクラスターはマスタースレーブアーキテクチャに従います。
マスターノードはハイエンドのコンピューターマシンであり、スレーブノードは通常のCPUとメモリ構成のマシンです。また、Hadoopクラスターは、シングルノードHadoopクラスターと呼ばれる単一のマシンまたはマルチノードHadoopクラスターと呼ばれる複数のマシンにセットアップできることも確認しました。
この記事では、Hadoopクラスターを構築する際に従うべきベストプラクティスについても説明しました。また、スケーラビリティ、柔軟性、費用対効果など、Hadoopクラスターの多くの利点も確認しました。