Hadoop MapReduceについてすべてを知りたい場合は、適切な場所に着陸しました。このMapReduceチュートリアルは、HadoopMapReduceのすべてに関する完全なガイドを提供します。
このMapReduceの概要では、Hadoop MapReduceとは何か、MapReduceフレームワークがどのように機能するかを探ります。この記事では、MapReduce DataFlow、MapReduce、Mapper、Reducer、Partitioner、Cominer、Shuffling、Sorting、DataLocalityなどのさまざまなフェーズについても説明しています。
MapReduceフレームワークの利点も取り入れました。
まず、HadoopMapReduceが必要な理由を探りましょう。
MapReduceを選ぶ理由
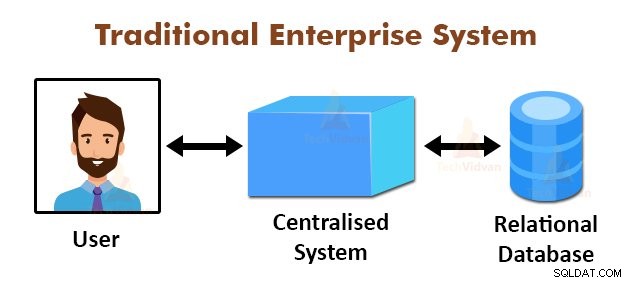
上の図は、従来のエンタープライズシステムの概略図を示しています。従来のシステムには通常、データを保存および処理するための集中型サーバーがあります。このモデルは、大量のスケーラブルなデータの処理には適していません。
また、このモデルは、標準のデータベースサーバーでは対応できませんでした。さらに、集中型システムでは、複数のファイルを同時に処理する際にボトルネックが多すぎます。
MapReduceアルゴリズムを使用することで、Googleはこのボトルネックの問題を解決しました。 MapReduceフレームワークは、タスクを小さな部分に分割し、タスクを多くのコンピューターに割り当てます。
その後、結果は一般的な場所で収集され、統合されて結果データセットが形成されます。
MapReduceフレームワークの概要
MapReduceは、Hadoopの処理レイヤーです。これは、タスクを一連の独立したタスクに分割することにより、大量のデータを並行して処理するために設計されたソフトウェアフレームワークです。
MapReduceが機能する方法でビジネスロジックを配置する必要があるだけで、フレームワークが残りの処理を行います。 MapReduceフレームワークは、ジョブを小さなタスクに分割し、これらのタスクをスレーブに割り当てることで機能します。
MapReduceプログラムは、関数型プログラミング構造、データのリストを処理するための特定のイディオムに影響される特定のスタイルで記述されています。
MapReduceでは、入力はリストの形式であり、フレームワークからの出力もリストの形式です。 MapReduceはHadoopの心臓部です。 Hadoopの効率と強力さは、MapReduceフレームワークの並列処理によるものです。
ここで、HadoopMapReduceがどのように機能するかを調べてみましょう。
Hadoop MapReduceはどのように機能しますか?
Hadoop MapReduceフレームワークは、ジョブを独立したタスクに分割し、これらのタスクをスレーブマシンで実行することで機能します。 MapReduceジョブは、マップフェーズとリデュースフェーズの2つのステージで実行されます。
両方のフェーズへの入力と両方のフェーズからの出力は、キーと値のペアです。 MapReduceフレームワークは、データの局所性の原則(後で説明)に基づいています。つまり、データが存在するノードに計算を送信します。
- マップフェーズ- マップフェーズでは、ユーザー定義のマップ関数が入力データを処理します。マップ関数では、ユーザーはビジネスロジックを配置します。マップフェーズからの出力は中間出力であり、ローカルディスクに保存されます。
- フェーズの削減– このフェーズは、シャッフルフェーズとリデュースフェーズの組み合わせです。リデュースフェーズでは、マップステージからの出力がレデューサーに渡され、そこで集約されます。削減フェーズの出力が最終出力です。削減フェーズでは、ユーザー定義の削減機能がマッパーの出力を処理し、最終結果を生成します。
MapReduceジョブ中に、HadoopフレームワークはMapタスクとReduceタスクをクラスター内の適切なマシンに送信します。
フレームワーク自体が、タスクの発行、タスクの完了の確認、クラスター周辺のノード間でのデータのコピーなど、データ受け渡しのすべての詳細を管理します。タスクは、ネットワークトラフィックを削減するために、データが存在するノードで実行されます。
MapReduceデータフロー
これらのキーと値のペアがどのように生成され、MapReduceが入力データをどのように処理するかを知りたいと思うかもしれません。このセクションでは、これらすべての質問に答えます。
次のデータを並列分散方式で処理するために、HadoopMapReduceのさまざまなフェーズからデータがどのように流れる必要があるかを見てみましょう。
1。 InputFiles
MapReduceプログラムによって処理される入力データセットは、InputFileに保存されます。 InputFileはHadoop分散ファイルシステムに保存されます。
2。 InputSplit
InputFilesのレコードは、論理モデルに分割されます。分割サイズは通常、HDFSブロックサイズと同じです。各分割は、個々のマッパーによって処理されます。
3。 InputFormat
InputFormatは、ファイル入力仕様を指定します。これは、InputFileからのレコードがキーと値のペアに変換されるRecordReaderへの方法を定義します。
4。 RecordReader
RecordReaderは、InputSplitからデータを読み取り、レコードをキーと値のペアに変換して、マッパーに提示します。
5。マッパー
マッパーは、RecordReaderからの入力としてキーと値のペアを受け取り、ユーザー定義のマップ関数を実装することによってそれらを処理します。各マッパーでは、一度に1つの分割が処理されます。
開発者は、ビジネスロジックをマップ関数に配置します。すべてのマッパーからの出力は中間出力であり、これもキーと値のペアの形式です。
6。シャッフルして並べ替え
Mappersによって生成された中間出力は、ネットワークの輻輳を減らすために、Reducerに渡される前にソートされます。ソートされた中間出力は、ネットワークを介してレデューサーにシャッフルされます。
7。レデューサー
Reducerは、ユーザー定義のreduce関数を実装することにより、Mapper出力を処理および集約します。レデューサーの出力は最終出力であり、Hadoop分散ファイルシステム(HDFS)に保存されます。
ここで、HadoopMapReduceフレームワークのいくつかの用語と高度な概念を調べてみましょう。
MapReduceのキーと値のペア
MapReduceフレームワークは、非静的スキーマを処理するため、キーと値のペアで機能します。データはキーと値のペアの形式で取得され、生成された出力もキーと値のペアの形式になります。
MapReduceキーの値のペアは、実行のためにMapReduceジョブによって受信されるレコードエンティティです。キーと値のペアの場合:
- キーは、ファイル内の行の先頭からの行オフセットです。
- 値は、ラインターミネータを除くラインコンテンツです。
MapReduce Partitioner
HadoopMapReducePartitionerはキースペースをパーティション化します。 MapReduceでキースペースを分割すると、各キーのすべての値がグループ化され、単一のキーのすべての値が同じレデューサーに送られるようになります。
このパーティショニングにより、適切なキーが適切なレデューサーに確実に送られるようにすることで、マッパーの出力をレデューサー全体に均等に分散できます。
デフォルトのMapReducerパーティショナーはHashPartitionerであり、ハッシュ値に基づいてキースペースをパーティション化します。
MapReduceコンバイナー
MapReduceコンバイナーは「Semi-Reducer」とも呼ばれます。これは、ネットワークの輻輳を軽減する上で主要な役割を果たします。 MapReduceフレームワークは、Mappersからの中間出力をReducerに渡す前に結合するCombinerを定義する機能を提供します。
レデューサーに渡す前のマッパー出力の集約は、フレームワークが少量のデータをシャッフルするのに役立ち、ネットワークの輻輳を低くします。
コンバイナーの主な機能は、マッパーの出力を同じキーで要約し、それをレデューサーに渡すことです。 Combinerクラスは、MapperクラスとReducerクラスの間で使用されます。
MapReduceのデータローカリティ
データの局所性とは、「データを計算に移動するのではなく、計算をデータに近づける」ことを指します。 アプリケーションによって要求された計算が、要求されたデータが存在するマシンで実行されると、はるかに効率的です。
これは、データサイズが大きい場合に非常に当てはまります。これは、ネットワークの輻輳を最小限に抑え、システムの全体的なスループットを向上させるためです。
この背後にある唯一の仮定は、アプリケーションが実行されているマシンにデータを移動するよりも、データが存在するマシンの近くに計算を移動する方がよいということです。
Apache Hadoopは大量のデータを処理するため、そのような大量のデータをネットワーク上で移動するのは効率的ではありません。したがって、フレームワークは、データを計算アルゴリズムに移動するのではなく、計算ロジックをデータに移動するデータローカリティという最も革新的な原則を考案しました。これはデータローカリティと呼ばれます。
MapReduceの利点
1。スケーラビリティ: MapReduceフレームワークは非常にスケーラブルです。これにより、組織は、数千テラバイトのデータの使用を伴う可能性のある大規模なマシンセットからアプリケーションを実行できます。
2。柔軟性: MapReduceフレームワークは、構造化、半構造化、または非構造化のいずれかで、あらゆるサイズとあらゆる形式のデータを処理する柔軟性を組織に提供します。
3。セキュリティと認証: MapReduceプログラミングモデルは高いセキュリティを提供します。データへの不正アクセスを保護し、クラスターのセキュリティを強化します。
4。費用対効果: フレームワークは、安価なマシンであるコモディティハードウェアのクラスター全体でデータを処理します。したがって、非常に費用対効果が高くなります。
5。高速: MapReduceはデータを並行して処理するため、非常に高速です。テラバイトのデータを処理するのに数分しかかかりません。
6。プログラミングの簡単なモデル: MapReduceプログラムは、Java、Python、Perl、Rなどの任意の言語で作成できます。したがって、誰でも簡単にMapReduceプログラムを学習および作成し、データ処理のニーズを満たすことができます。
MapReduceの使用法
1。ログ分析: MapReduceは、基本的にログファイルの分析に使用されます。フレームワークは大きなログファイルを分割し、マッパーがアクセスされたさまざまなWebページを検索します。
ログでWebページが見つかるたびに、キーと値のペアがレデューサーに渡されます。ここで、キーはWebページであり、値は「1」です。キーと値のペアをReducerに発行した後、Reducerは特定のWebページの数を集計します。
最終的な結果は、すべてのWebページのヒットの総数になります。
2。フルテキストのインデックス作成: MapReduceは、フルテキストのインデックス作成にも使用されます。 MapReduceのマッパーは、1つのドキュメント内のすべてのフレーズまたは単語をドキュメントにマップします。レデューサーはこれらのマッピングをインデックスに書き込みます。
3。 GoogleはPagerankの計算にMapReduceを使用しています。
4。逆Webリンクグラフ: MapReduceは、ReverseWeb-LinkGRaphでも使用されます。 Map関数は、Webページ(ソース)からの入力を取得して、URLターゲットとソースを出力します。
次に、reduce関数は、指定されたターゲットURLに関連付けられているすべてのソースURLのリストを連結し、ターゲットとソースのリストを返します。
5。ドキュメント内の単語数: MapReduceフレームワークは、単語がドキュメントに出現する回数をカウントするために使用できます。
概要
これはすべて、HadoopMapReduceチュートリアルに関するものです。フレームワークは、コモディティハードウェアのクラスター全体で大量のデータを並行して処理します。ジョブを独立したタスクに分割し、クラスター内のさまざまなノードで並行して実行します。
MapReduceは、従来のエンタープライズシステムのボトルネックを克服します。フレームワークは、キーと値のペアで機能します。ユーザーは、map関数とreduce関数の2つの関数を定義します。
ビジネスロジックはmap関数に組み込まれます。この記事では、MapReduceフレームワークのさまざまな高度な概念について説明しました。