これまで、Hadoopの紹介について説明してきました。 およびHadoopHDFS 詳細に。このチュートリアルでは、HadoopReducerの詳細な説明を提供します。
ここでは、MapReduceのReducerとは何か、Hadoop MapReduceでReducerがどのように機能するか、Hadoop Reducerのさまざまなフェーズ、HadoopMapReduceでReducerの数を変更する方法について説明します。
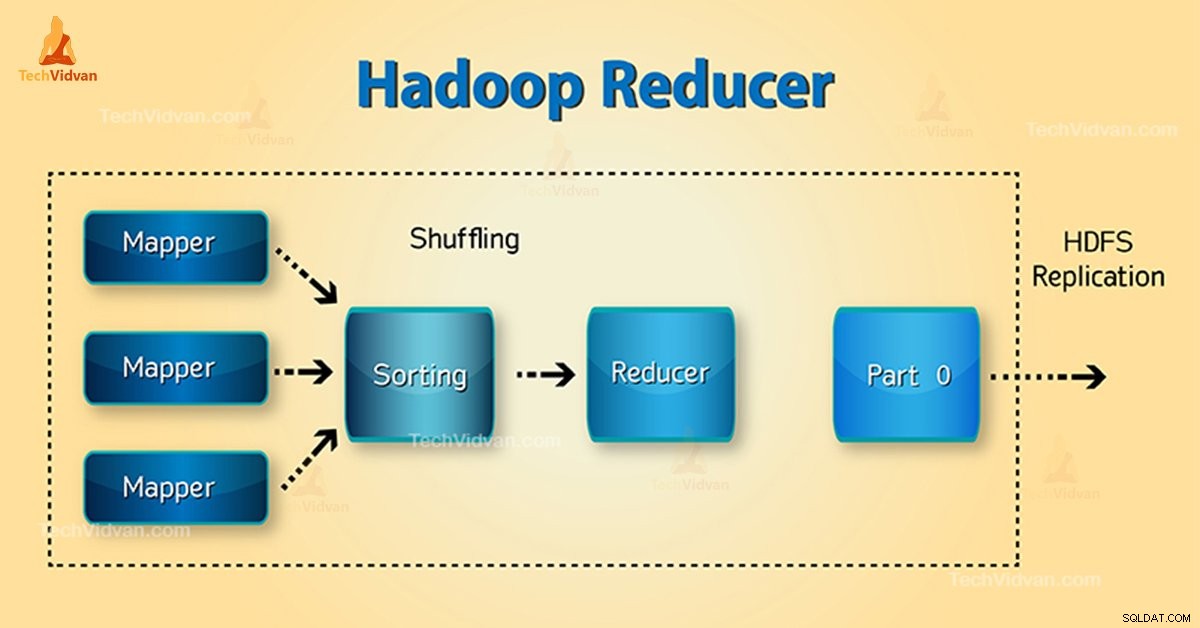
Hadoopレデューサーとは何ですか?
レデューサー Hadoop MapReduceでは、キーを共有する一連の中間値をより小さな値のセットに減らします。
MapReduceジョブ実行フローでは、Reducerは中間のキーと値のペアのセットを取ります マッパーによって作成されました 入力として。次に、Reducerはキーと値のペアを集約、フィルタリング、および結合します。これには、幅広い処理が必要です。
MapReduceジョブ実行では、キーとレデューサーの間で1対1のマッピングが行われます。それらは互いに独立しているため、並行して実行されます。 MapReduceのレデューサーの数はユーザーが決定します。
Hadoopリデューサーのフェーズ
レデューサーの3つのフェーズは次のとおりです。
1。シャッフルフェーズ
これは、マッパーからのソートされた出力がレデューサーへの入力であるフェーズです。 HTTPを使用するフレームワークは、このフェーズのすべてのマッパーの出力の関連するパーティションをフェッチします。ソートフェーズ
2。並べ替えフェーズ
これは、さまざまなマッパーからの入力が、さまざまなマッパーの同様のキーに基づいて再度並べ替えられるフェーズです。
シャッフルとソートの両方が同時に発生します。
3。フェーズを減らす
このフェーズは、シャッフルとソートの後に発生します。削減タスクは、キーと値のペアを集約します。 OutputCollector.collect()を使用 プロパティでは、reduceタスクの出力がファイルシステムに書き込まれます。レデューサー出力はソートされていません。
HadoopMapReduceのレデューサーの数
ユーザーは、 Job.setNumreduceTasks(int)を使用してレデューサーの数を設定します 財産。したがって、次の式による適切な数のレデューサー:
0.95または1.75に(<ノード数> * <ノードあたりの最大コンテナ数>)を掛けたもの
したがって、0.95では、すべてのレデューサーがすぐに起動します。次に、マップが終了したら、マップ出力の転送を開始します。
より高速なノードは、1.75でレデューサーの最初のラウンドを終了します。次に、ロードバランシングの機能を大幅に向上させるレデューサーの第2波を起動します。
レデューサーの数の増加に伴い:
- フレームワークのオーバーヘッドが増加します。
- 負荷分散が増加します。
- 失敗のコストは減少します。
結論
したがって、Reducerはマッパーの出力を入力として受け取ります。次に、キーと値のペアを処理して出力を生成します。レデューサー出力が最終出力です。このブログが気に入った場合、またはHadoop Reducerに関連する質問がある場合は、コメントを残して共有してください。
お役に立てば幸いです。