このブログでは、 Hadoop Mapperの完全な紹介を提供します。 。私
このブログでは、Hadoop MapReduceのマッパーとは何か、Hadoopマッパーの仕組み、Mapreduceのマッパーのプロセス、HadoopがMapReduceでキーと値のペアを生成する方法について説明します。
HadoopMapperの概要
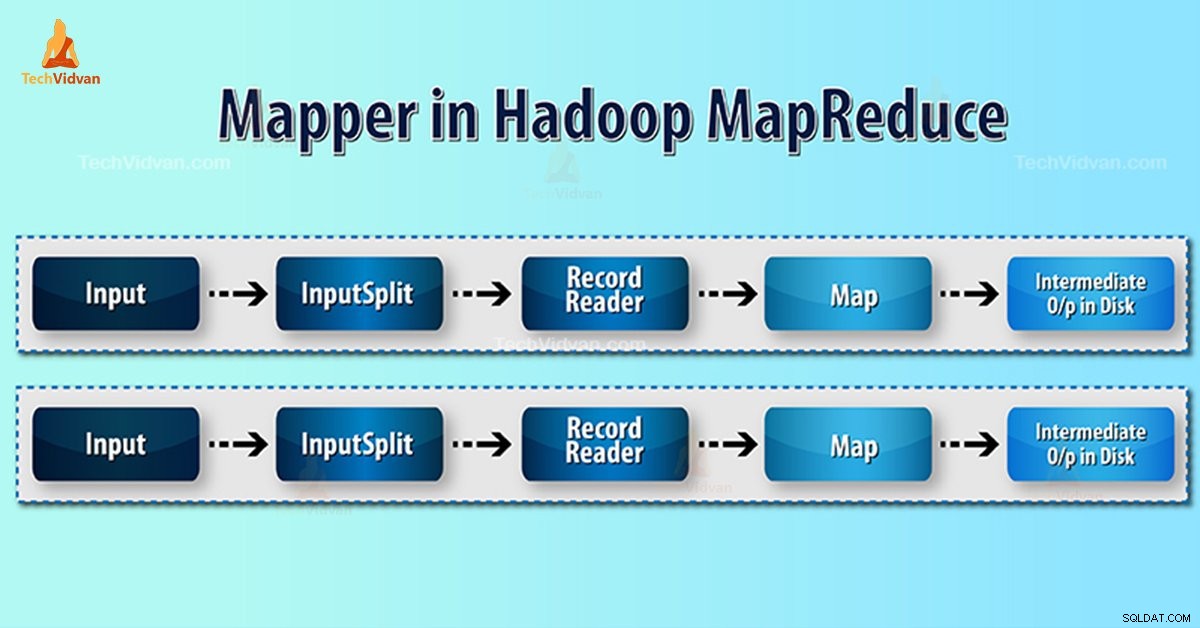
Hadoop Mapper RecordReaderによって生成された入力レコードを処理します 中間のキーと値のペアを生成します。中間出力は入力ペアとは完全に異なります。
マッパーの出力は、キーと値のペアの完全なコレクションです。各マッパータスクの出力を書き込む前に、キーに基づいて出力のパーティション化が行われます。したがって、パーティション化により、各キーのすべての値がグループ化されます。
Hadoop MapReduceは、InputSplitごとに1つのマップタスクを生成します。
Hadoop MapReduceは、データのキーと値のペアのみを理解します。したがって、データをマッパーに送信する前に、Hadoopフレームワークはデータをキーと値のペアに変換する必要があります。
Hadoopでキーと値のペアはどのように生成されますか?
Hadoopのマッパーとは何かを理解したので、Hadoopがキーと値のペアを生成する方法について説明します。
- InputSplit – これは、InputFormat。によって生成されたデータの論理表現です。 MapReduceプログラムでは、単一のマップタスクを含む作業単位を記述します。
- RecordReader- inputSplitと通信します。次に、データをマッパーによる読み取りに適したキーと値のペアに変換します。 RecordReaderは、デフォルトでTextInputFormatを使用してデータをキーと値のペアに変換します。
HadoopMapReduceのマッパープロセス
InputSplit ブロックの物理的表現をマッパーの論理に変換します。たとえば、100MBのファイルを読み取るには、2つのInputSplitが必要になります。ブロックごとに、フレームワークは1つのInputSplitを作成します。各InputSplitは1つのマッパーを作成します。
MapReduce InputSplitは、必ずしもデータブロックの数に依存するとは限りません 。 mapred.max.split.sizeプロパティを設定することで、分割の数を変更できます。 ジョブの実行中。
MapReduce RecordReaderは、ファイルの最後までデータを読み取り/キーと値のペアに変換する役割を果たします。 RecordReaderは、ファイルに存在する各行にバイトオフセットを割り当てます。
次に、マッパーはこのキーペアを受け取ります。マッパーは中間出力(削減するのが理解できるキーと値のペア)を生成します。
Hadoopのマップタスクはいくつですか?
マップタスクの数は、入力ファイルのブロックの総数によって異なります。 MapReduceマップでは、適切なレベルの並列処理は約10〜100マップ/ノードのようです。ただし、CPUライトマップタスクには300のマップがあります。
たとえば、ブロックサイズは128MBです。また、10TBの入力データが必要です。したがって、82,000のマップが生成されます。したがって、マップの数はInputFormatによって異なります。
マッパー=(合計データサイズ)/(入力分割サイズ)
例 –データサイズは1TBです。入力分割サイズは100MBです。
マッパー=(1000 * 1000)/ 100 =10,000
結論
したがって、Hadoopのマッパーはデータセットを取得し、それを別のデータセットに変換します。したがって、個々の要素をタプル(キー/値のペア)に分割します。
Hadoopマッパーについて質問がある場合は、このブロックが気に入っていただければ幸いです。以下のセクションにコメントを残してください。喜んで解決させていただきます。