以前のHadoopチュートリアル 、Hadoopパーティショナーを調査しました 詳細に。次に、HadoopMapReduceのInputSplitについて説明します。
ここでは、Hadoop InputSplitとは何か、MapReduceでのInputSplitの必要性について説明します。また、これらのInputSplitがHadoopMapReduceでどのように作成されるかについても詳しく説明します。
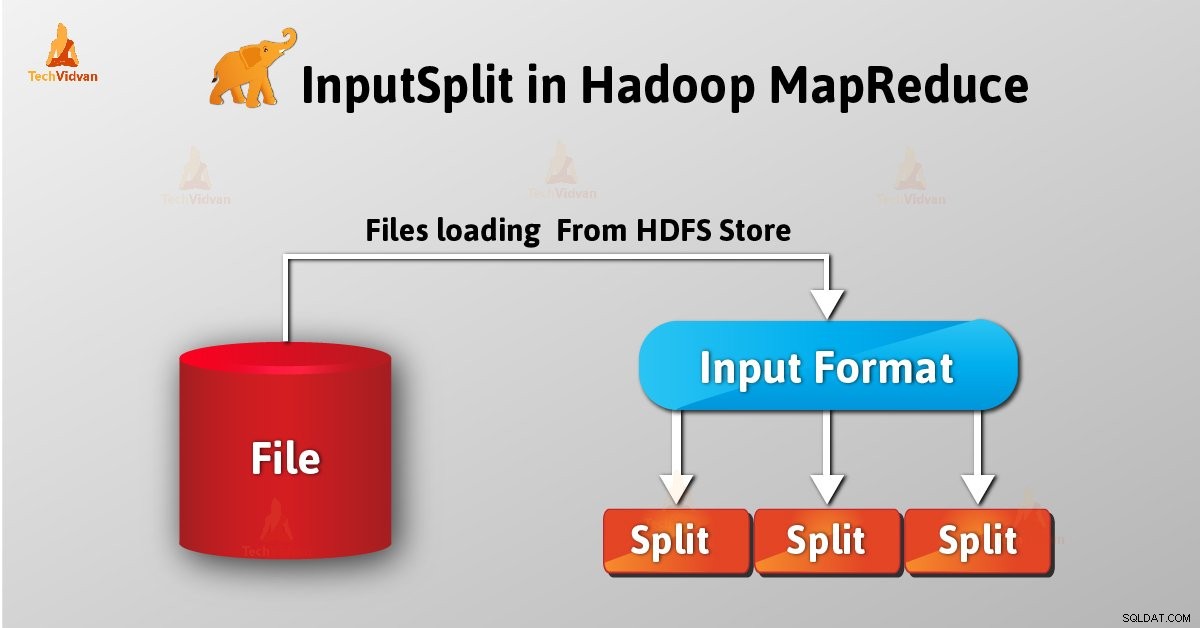
HadoopでのInputSplitの概要
InputSplitは、HadoopMapReduceのデータの論理表現です。個々のマッパーのデータを表します プロセス。したがって、マップタスクの数はInputSplitsの数と同じです。フレームワークは分割をレコードに分割し、マッパーが処理します。
MapReduceInputSplitの長さはバイト単位で測定されています。すべてのInputSplitには、保存場所(ホスト名文字列)があります。 MapReduceシステムは、ストレージの場所を使用して、マップタスクをスプリットのデータのできるだけ近くに配置します。
フレームワークは、分割のサイズ順にマップタスクを処理し、最大のものが最初に処理されるようにします(貪欲な近似アルゴリズム)。これにより、ジョブの実行時間が最小限に抑えられます。
焦点を当てるべき主なことは、Inputsplitには入力データが含まれていないということです。これは単なるデータへの参照です。
Hadoop MapReduceでInputSplitsはどのように作成されますか?
ユーザーとして、 InputFormat のように、HadoopでInputSplitを直接処理することはありません。 (InputFormatはInputsplitの作成とレコードへの分割を担当するため)それを作成します。 FileInputFormatは、ファイルを128MBのチャンクに分割します。
また、 mapredを設定することにより 。分 。分割 。サイズ mapred-siteのパラメータ 。xml ユーザーは要件に応じて値を変更できます。また、これにより、特定のMapReduceジョブの送信に使用されるJobオブジェクトのパラメーターをオーバーライドできます。
カスタムInputFormatを作成することで、ファイルを分割する方法を制御することもできます。
InputSplitはユーザー定義です。ユーザーは、MapReduceプログラムのデータのサイズに基づいて分割サイズを制御することもできます。したがって、MapReduceジョブの実行では、マップタスクの数はInputSplitsの数と等しくなります。
「getSplit()」を呼び出す 、クライアントはジョブの分割を計算します。次に、アプリケーションマスターに送信されます。アプリケーションマスターは、ストレージの場所を使用して、クラスター上でそれらを処理するマップタスクをスケジュールします。
その後、マップタスクは分割を createRecordReader()に渡します 方法。そこからRecordReaderを取得します 分割のため。次に、RecordReaderはレコード(キーと値のペア)を生成します 、これをマップ関数に渡します。
結論
結論として、InputSplitは、個々のマッパーが処理するデータを表していると言えます。分割ごとに1つのマップタスクが作成されます。したがって、InputFormatはInputSplitを作成します。
MapReduceのInputSplitについて質問がある場合は、以下のセクションにコメントを残してください。