大量のデータを保存および処理するために最も採用されているフレームワークであるHadoopのアーキテクチャを探ります。
この記事では、Hadoopアーキテクチャーについて学習します。この記事では、Hadoopアーキテクチャーと、HadoopアーキテクチャーのコンポーネントであるHDFS、MapReduce、およびYARNについて説明します。この記事では、Hadoopアーキテクチャーの図とともに、Hadoopアーキテクチャーについて詳しく説明します。
それでは、Hadoopアーキテクチャから始めましょう。
Hadoopアーキテクチャ
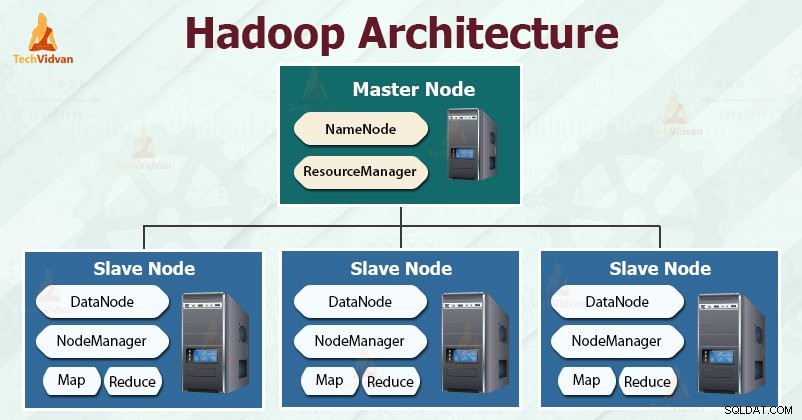
Hadoopの設計の目標は、増加するビッグデータを保存および分析する、安価で信頼性が高く、スケーラブルなフレームワークを開発することです。
Apache Hadoopは、さまざまなサイズと形式の大規模なデータセットを保存および処理するためにApacheSoftwareFoundationによって設計されたソフトウェアフレームワークです。
Hadoopはマスタースレーブに従います 膨大な量のデータを効果的に保存および処理するためのアーキテクチャ。マスターノードは、スレーブノードにタスクを割り当てます。
スレーブノードは、実際のデータを保存し、実際の計算/処理を実行する責任があります。マスターノードは、メタデータの保存とクラスター全体のリソースの管理を担当します。
スレーブノードは実際のビジネスデータを保存しますが、マスターはメタデータを保存します。
Hadoopアーキテクチャは3つのレイヤーで構成されています。それらは:
- ストレージレイヤー(HDFS)
- リソース管理レイヤー(YARN)
- 処理レイヤー(MapReduce)
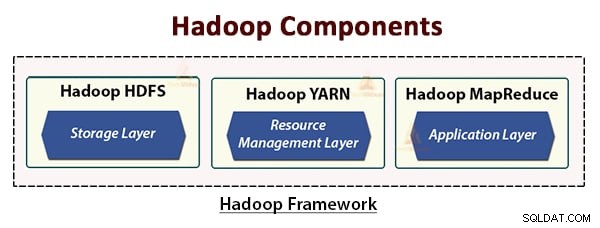
HDFS、YARN、およびMapReduceは、Hadoopフレームワークのコアコンポーネントです。
これらの3つのコアコンポーネントについて詳しく見ていきましょう。
1。 HDFS
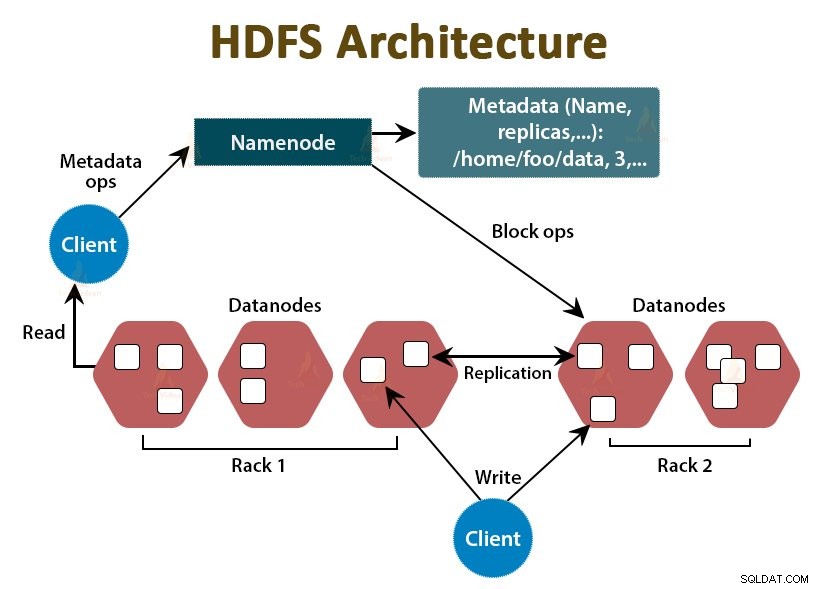
HDFSはHadoop分散ファイルシステムです 、安価なコモディティハードウェアで動作します。これはHadoopのストレージレイヤーです。 HDFSのファイルは、データブロックと呼ばれるブロックサイズのチャンクに分割されます。
これらのブロックは、クラスター内のスレーブノードに保存されます。ブロックサイズはデフォルトで128MBであり、要件に応じて構成できます。
Hadoopと同様に、HDFSもマスタースレーブアーキテクチャに従います。 NameNodeとDataNodeの2つのデーモンで構成されています。 NameNodeは、マスターノードで実行されるマスターデーモンです。 DataNodeは、スレーブノードで実行されるスレーブデーモンです。
NameNode
NameNodeは、ファイルシステムのメタデータ、つまり、ファイル名、ファイルのブロックに関する情報、ブロックの場所、アクセス許可などを格納します。データノードを管理します。
DataNode
DataNodeは、実際のビジネスデータを格納するスレーブノードです。 NameNode命令に基づいてクライアントの読み取り/書き込み要求を処理します。
DataNodesはファイルのブロックを保存し、NameNodeはブロックの場所や権限などのメタデータを保存します。
2。 MapReduce
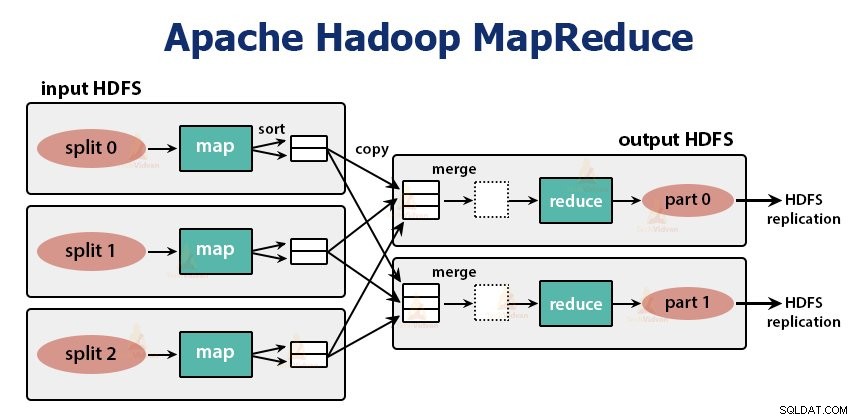
これは、Hadoopのデータ処理レイヤーです。これは、コモディティハードウェアのクラスター上で大量のデータ(範囲内でテラバイトからペタバイト)を並行して処理するアプリケーションを作成するためのソフトウェアフレームワークです。
MapReduceフレームワークは、
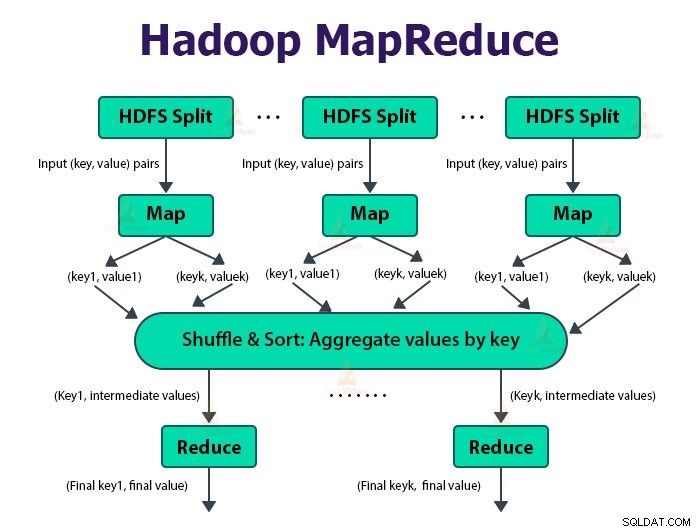
MapReduceジョブは、クライアントが実行したい作業の単位です。 MapReduceジョブは、主に入力データ、MapReduceプログラム、および構成情報で構成されます。 Hadoopは、MapReduceジョブをマップタスクである2つのタイプのタスクに分割して実行します。 およびタスクの削減 。 Hadoop YARNはこれらのタスクをスケジュールし、クラスター内のノードで実行されます。
いくつかの不利な条件により、タスクが失敗した場合、タスクは別のノードで自動的に再スケジュールされます。
ユーザーがマップ関数を定義します および削減機能 MapReduceジョブを実行するため。
map関数への入力とreduce関数からの出力は、キーと値のペアです。
マップタスクの機能は、データのロード、解析、フィルタリング、および変換です。 mapタスクの出力は、reduceタスクへの入力です。次に、Reduceタスクは、マップタスクの出力に対してグループ化と集計を実行します。
MapReduceタスクは2つのフェーズで実行されます-
1。マップフェーズ
a。 RecordReader
Hadoopは、MapReduceジョブへの入力を入力分割と呼ばれる固定サイズの分割に分割します または分割します。 RecordReaderは、これらの分割をレコードに変換し、データをレコードに解析しますが、レコード自体は解析しません。 RecordReader キーと値のペアでマッパー関数にデータを提供します。
b。地図
マップフェーズでは、Hadoopは、入力分割のレコードごとにマップ関数と呼ばれるユーザー定義関数を実行する1つのマップタスクを作成します。マップタスクの出力として、ゼロまたは複数の中間キーと値のペアを生成します。
マップタスクは、その出力をローカルディスクに書き込みます。次に、この中間出力は、ユーザー定義のreduce関数を実行して最終出力を生成するreduceタスクによって処理されます。ジョブが完了すると、マップ出力がフラッシュされます。
c。コンバイナー
単一のreduceタスクへの入力は、すべてのマップタスクから出力されるすべてのマッパーからの出力です。 Hadoopを使用すると、ユーザーはマップ出力で実行されるコンバイナー関数を定義できます。
コンバイナー データをReducerに渡す前に、マップフェーズでデータをグループ化します。これは、map関数の出力を組み合わせて、reduce関数への入力として渡されます。
d。パーティショナー
複数のレデューサーがある場合、マップタスクは出力をパーティション化し、それぞれがリデュースタスクごとに1つのパーティションを作成します。各パーティションには、多くのキーとそれに関連する値が存在する可能性がありますが、特定のキーのレコードはすべて1つのパーティションにあります。
Hadoopを使用すると、ユーザーはユーザー定義のパーティショニング機能を指定してパーティショニングを制御できます。通常、ハッシュ関数を使用してキーをバケット化するデフォルトのパーティショナーがあります。
2。フェーズを減らす:
リデュースタスクのさまざまなフェーズは次のとおりです。
a。並べ替えとシャッフル:
レデューサータスクは、シャッフルとソートのステップから始まります。このフェーズの主な目的は、同等のキーをまとめて収集することです。並べ替えとシャッフルフェーズでは、パーティショナーによって書き込まれたデータが、Reducerが実行されているノードにダウンロードされます。
各データを大きなデータリストに分類します。 MapReduceフレームワークはこの並べ替えを実行してシャッフルするため、reduceタスクで簡単に繰り返すことができます。
並べ替えとシャッフル フレームワークによって自動的に実行されます。開発者は、コンパレータオブジェクトを介して、キーの並べ替えとグループ化の方法を制御できます。
b。削減:
ユーザー定義のreduce関数であるReducerは、キーのグループ化ごとに1回実行されます。レデューサーは、いくつかの異なる方法でデータをフィルタリング、集約、および結合します。削減タスクが完了すると、OutputFormatに0個以上のキーと値のペアが与えられます。削減タスクの出力はHadoopHDFSに保存されます。
c。 OutputFormat
レデューサー出力を取得し、RecordWriterによってHDFSファイルに書き込みます。デフォルトでは、キーと値をタブで区切り、各レコードを改行文字で区切ります。
3。毛糸
YARNはYetAnother Resource Negotiatorの略です 。これは、Hadoopのリソース管理レイヤーです。 Hadoop2で導入されました。
YARNは、ジョブスケジューリングとリソース管理の機能を別々のデーモンに分割するという考えで設計されています。基本的な考え方は、アプリケーションごとにグローバルなResourceManagerとアプリケーションマスターを用意することです。この場合、アプリケーションは単一のジョブまたはジョブのDAGにすることができます。
YARNは、ResourceManager、NodeManager、およびアプリケーションごとのApplicationMasterで構成されています。
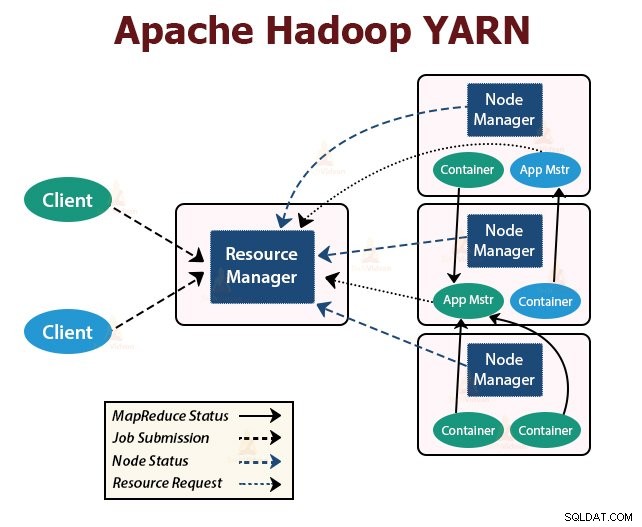
1。 ResourceManager
クラスタ内のすべてのアプリケーション間でリソースを調停します。
スケジューラとApplicationManagerの2つの主要コンポーネントがあります。
a。スケジューラ
- スケジューラーは、容量やキューなどを考慮して、クラスターで実行されているさまざまなアプリケーションにリソースを割り当てます。
- これは純粋なスケジューラです。アプリケーションのステータスを監視または追跡しません。
- スケジューラーは、アプリケーション障害またはハードウェア障害のいずれかが原因で失敗した失敗したタスクの再開を保証しません。
- アプリケーションのリソース要件に基づいてスケジューリングを実行します。
b。 ApplicationManager
- 彼らは仕事の提出を受け入れる責任があります。
- ApplicationManagerは、アプリケーション固有のApplicationMasterを実行するための最初のコンテナーをネゴシエートします。
- 障害時にApplicationMasterコンテナを再起動するためのサービスを提供します。
- アプリケーションごとのApplicationMasterは、スケジューラーからのコンテナーのネゴシエーションを担当します。ステータスと進捗状況を追跡および監視します。
2。 NodeManager:
NodeManagerはスレーブノードで実行されます。コンテナを担当し、CPU、メモリ、ディスク、ネットワークの使用状況であるマシンリソースの使用状況を監視し、それらをResourceManagerまたはスケジューラに報告します。
3。 ApplicationMaster:
アプリケーションごとのApplicationMasterは、フレームワーク固有のライブラリです。 ResourceManagerからのリソースのネゴシエーションを担当します。 NodeManagerと連携して、タスクを実行および監視します。
概要
この記事では、Hadoopアーキテクチャーについて学習しました。 Hadoopは、マスタースレーブトポロジに従います。マスターノードは、スレーブノードにタスクを割り当てます。アーキテクチャは、HDFS、YARN、MapReduceの3つのレイヤーで構成されています。
HDFSは、ビッグデータを保存するためのHadoopの分散ファイルシステムです。 MapReduceは、Hadoopクラスター内の膨大なデータを分散して処理するための処理フレームワークです。 YARNは、クラスター内のアプリケーション間のリソースを管理する責任があります。
HDFSデーモンのNameNodeとYARNデーモンのResourceManagerは、Hadoopクラスターのマスターノードで実行されます。 HDFSデーモンDataNodeとYARNNodeManagerはスレーブノードで実行されます。
HDFSとMapReduceフレームワークは同じノードのセットで実行されるため、クラスター全体で非常に高い総帯域幅が得られます。
学び続けてください!!