以前のHadoop Hadoopの各コンポーネントを調査したブログ MapReduceプロセスの詳細。ここでは、非常に興味深いトピック、つまりHadoopでのマップのみのジョブについて説明します。
まず、マップについて簡単に紹介します。 および削減 Hadoop Mapreduceのフェーズ、次にHadoopMapReduceでのMaponlyジョブとは何かについて説明します。
最後に、このチュートリアルでは、Hadoopマップのみのジョブの長所と短所についても説明します。
Hadoopマップのみのジョブとは何ですか?
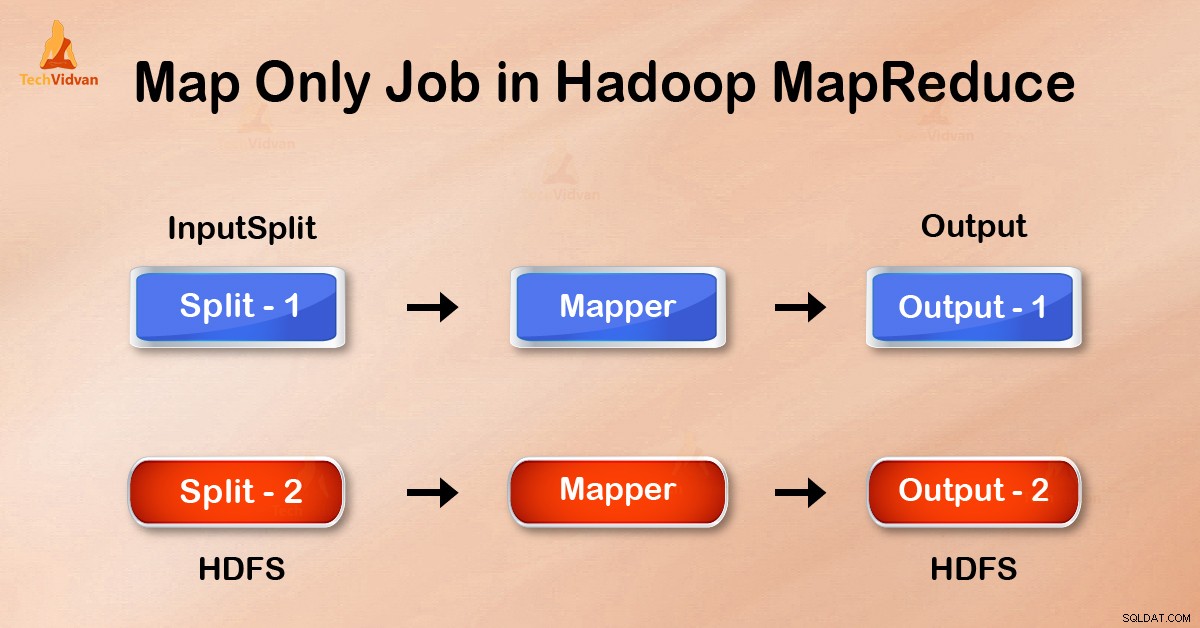
地図のみの仕事 Hadoopでは、マッパーが すべてのタスクを実行します。 リデューサーによるタスクは実行されません 。マッパーの出力が最終出力です。
MapReduceは、Hadoopのデータ処理レイヤーです。 HDFSに保存されている大規模な構造化データと非構造化データを処理します 。 MapReduceは、大量のデータも並行して処理します。
これは、ジョブ(送信されたジョブ)を一連の独立したタスク(サブジョブ)に分割することによって行われます。 Hadoopでは、MapReduceは処理をフェーズに分割することで機能します:マップ および削減 。
- 地図: これは処理の最初のフェーズであり、すべての複雑なロジックコードを指定します。データセットを取得し、別のデータセットに変換します。個々の要素をタプル(キーと値のペア)に分割します 。
- 削減: 処理の第2段階です。ここでは、集計/合計などの軽量処理を指定します。マップからの出力を入力として受け取ります。次に、キーに基づいてそれらのタプルを結合します。
この単語数の例から、2セットの並列プロセスがあると言えます。マップして削減します。マッププロセスでは、最初の入力が分割され、上記のようにすべてのマップノードに作業が分散されます。
次に、フレームワークは各単語を識別し、番号1にマップします。したがって、タプル(キーと値)のペアと呼ばれるペアを作成します。
最初のマッパーノードでは、ライオン、トラ、川の3つの単語を渡します。したがって、ノードの出力として3つのキーと値のペアが生成されます。 3つの異なるキーと値を1に設定し、同じプロセスをすべてのノードで繰り返します。
次に、これらのタプルをリデューサーノードに渡します。パーティショナーはシャッフルを実行します 同じキーを持つすべてのタプルが同じノードに移動するようにします。
リデュースプロセスで基本的に行われるのは、値の集約であり、同じキーを共有する値に対する操作です。
ここで、操作を実行するだけでよいシナリオを考えてみましょう。集計は必要ありません。そのような場合は、「マップのみのジョブ」を使用します。 ’。
マップのみのジョブでは、マップは InputSplitを使用してすべてのタスクを実行します 。レデューサーは仕事をしません。マッパーの出力が最終出力です。
MapReduceでReduceフェーズを回避する方法は?
job.setNumreduceTasks(0)を設定する ドライバーの構成では、フェーズの削減を回避できます。これにより、レデューサーの数が 0になります。 。したがって、唯一のマッパーが完全なタスクを実行します。
Hadoopでのマップのみのジョブの利点
MapReduceには、マップとリデュースフェーズの間のジョブ実行があり、キー、ソート、シャッフルのフェーズがあります。 シャッフル–並べ替え キーを昇順で並べ替える責任があります。次に、同じキーに基づいて値をグループ化します。このフェーズは非常に費用がかかります。
削減フェーズが必要ない場合は、回避する必要があります。削減フェーズを回避すると、並べ替えとシャッフルフェーズも排除されます。したがって、これによりネットワークの輻輳も回避されます。
その理由は、シャッフルでは、マッパーの出力が減少するように移動するためです。また、データサイズが大きい場合、大きなデータはレデューサーに移動する必要があります。
マッパーの出力は、reduceに送信する前にローカルディスクに書き込まれます。ただし、マップのみのジョブでは、この出力はHDFSに直接書き込まれます。これにより、さらに時間が節約され、コストも削減されます。
結論
したがって、マップのみのジョブは、シャッフル、ソート、およびフェーズの削減を回避することにより、ネットワークの輻輳を軽減することがわかりました。マップだけで全体的な処理を処理し、出力を生成します。 job.setNumreduceTasks(0)を使用する これは達成されます。
Hadoopでのマップのみのジョブに関するすべてをカバーしたので、Hadoopマップのみのジョブとその重要性を理解していただければ幸いです。ただし、コメントセクションで共有できるように質問がある場合は。