Oracle SQLチュートリアルの学習の一環として、Oracleによるグループの詳細を以下に示します
単一値関数とは異なり、グループ関数は行のセットを操作し、グループごとに1つの行を返します。行のセットは、テーブル全体またはグループに分割されたテーブルの場合があります
Oracleのグループ関数のタイプは次のとおりです。
| AVG([Distinct / all] n) | 数値データ型のみ。 null値を無視した列nの平均値 |
| COUNT({* / [Distinct / all] expr}) | null値を含むのはグループ関数のみです。 where句を満たすselectステートメントの行数をカウントします。 Count(*)には、すべてのnull値と重複値が含まれます |
| MAX([Distinct / all] expr) | 任意のデータ型で使用できます。 null値を無視してexprの最大値を示します |
| MIN([Distinct / all] expr) | 任意のデータ型で使用できます。 。 null値を無視してexprの最小値を示します |
| STDDEV([Distinct / all] n) | 数値データ型のみ。 null値を無視してnの標準偏差を与えます |
| SUM([Distinct / all] n) | 数値データ型のみで、関数に他の算術演算子を含めることはできません。null値を無視してnの合計を提供します |
| VARIANCE([Distinct / all] n) | 数値データ型のみ。 null値を無視してnの分散を与えます |
構文:
SELECT col1, col2, … col_n, aggregate_function (aggregate_expression) FROM tables [WHERE conditions] GROUP BY col1, col2, … col_n Having group condition;
Oracleサーバーは次の手順を実行しました
- 最初に、where句に基づいて行が選択されます
- 行はグループ化されます
- グループ機能は各グループに適用されます
- having句の基準に一致するグループが表示されます
したがって、WHERE句が最初に評価され(クエリ結果を制限)、次にGROUP BY句(WHEREの結果をグループ化)、次にHAVING句(返されるグループを制限することで結果をさらに制限)が評価されます。
groupbyoracleに関するいくつかの重要なポイント
(1)GROUP BY:グループ関数の結果を1つの大きなデータテーブルから小さな論理グループに分解します。
(2)WHERE句はグループを制限できないため、HAVING句を使用します。
(3)GROUPBY句で列エイリアスを使用しないでください。
(4)HAVING:グループの表示を指定された条件を「持っている」グループに制限します。
(5)NVL関数を使用すると、GROUPBY関数の計算にnull値を含めることができます。
(6)集計関数ではない選択リスト内の列または式は、groupby句に含まれている必要があります
Oracleのグループ関数の例
最初にサンプルテーブルを作成してから、oraclesqlによるグループ化を試してみましょう
CREATE TABLE "DEPT"
( "DEPTNO" NUMBER(2,0),
"DNAME" VARCHAR2(14),
"LOC" VARCHAR2(13),
CONSTRAINT "PK_DEPT" PRIMARY KEY ("DEPTNO")
)
CREATE TABLE "EMP"
( "EMPNO" NUMBER(4,0),
"ENAME" VARCHAR2(10),
"JOB" VARCHAR2(9),
"MGR" NUMBER(4,0),
"HIREDATE" DATE,
"SAL" NUMBER(7,2),
"COMM" NUMBER(7,2),
"DEPTNO" NUMBER(2,0),
CONSTRAINT "PK_EMP" PRIMARY KEY ("EMPNO"),
CONSTRAINT "FK_DEPTNO" FOREIGN KEY ("DEPTNO")
REFERENCES "DEPT" ("DEPTNO") ENABLE
);
insert into DEPT values(10, 'ACCOUNTING', 'NEW YORK');
insert into dept values(20, 'RESEARCH', 'DALLAS');
insert into dept values(30, 'RESEARCH', 'DELHI');
insert into dept values(40, 'RESEARCH', 'MUMBAI');
insert into emp values( 7698, 'Blake', 'MANAGER', 7839, to_date('1-5-2007','dd-mm-yyyy'), 2850, null, 10 );
insert into emp values( 7782, 'Clark', 'MANAGER', 7839, to_date('9-6-2008','dd-mm-yyyy'), 2450, null, 10 );
insert into emp values( 7788, 'Scott', 'ANALYST', 7566, to_date('9-6-2012','dd-mm-yyyy'), 3000, null, 20 );
insert into emp values( 7789, 'TPM', 'ANALYST', 7566, to_date('9-6-2017','dd-mm-yyyy'), 3000, null, null );
insert into emp values( 7560, 'T1OM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, 20 );
insert into emp values( 7790, 'TOM', 'ANALYST', 7567, to_date('9-7-2017','dd-mm-yyyy'), 4000, null, null );
commit;
Select * from emp; 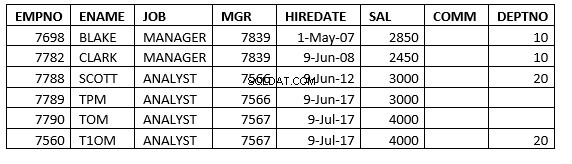
単一列
Select dept , avg(sal) from emp group by dept;からdept、avg(sal)を選択します。
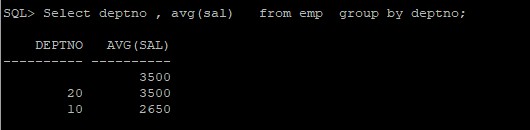
複数の列
Select deptno ,job, sum(sal) from emp group by deptno,job

カウント関数
SELECT dept, COUNT(*) AS "Np of employees" FROM emp WHERE sal < 15000
GROUP BY dept;
最小関数
SELECT dept, MIN(sal) AS "Lowest salary" FROM emp
GROUP BY dept;
この記事が気に入っていただければ幸いです
関連記事
oracleの分析関数:Oracle Analytic関数は、oracle句によるオーバーパーティションを使用して行のグループに基づいて集計値を計算します。これらは、Oracleの集計関数とは異なります。
oracleのランク:RANK、DENSE_RANK、およびROW_NUMBERはoracle分析です。 windowと呼ばれる行のグループ内の行をランク付けするために使用される関数
OracleのLead関数:OracleのLAG関数とOracleのLead関数、分析クエリでの使用方法、およびOraclesqlでの動作を確認してください
OracleのTop-Nクエリ:OracleのTop-NクエリとOracleクエリOracleデータベースのページネーションを実現するためのさまざまな方法については、このページをご覧ください。