データベーステーブルの列の値には二重引用符がありません。
結果グリッドからデータをコピーすると、SQLDeveloperはコピー操作の一部としてデータを追加します。 (おそらくそうしないように頼む方法はありますが、すぐにはわかりません。)取得する最初の値の末尾に改行文字があるため、これを行っています。私がそうすれば、あなたが見ているものを複製することができます:
select 'Testdata' || chr(10) from dual
union all
select 'Testdata' from dual;
スクリプトとして実行すると、スクリプト出力ウィンドウに次のように表示されます。
'TESTDATA
---------
Testdata
Testdata
ここで改行は失われ、そこからコピーアンドペーストしても改行は保持されません。ステートメントとして実行すると、クエリ結果ウィンドウのデータは同じように見えます:
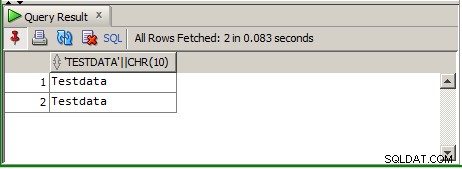
しかし、そのデータをグリッドからコピーして貼り付けると(Notepad ++だけでなく、どこにでも)、次のようにも表示されます。
"Testdata
"
Testdata
...したがって、改行は保持され、二重引用符で囲まれているため、貼り付けられたものはすべて(Excelを対象としていると思います)、改行文字を含む単一の値であると理解されます。
問題は、それらが実際には明確ではないということです。 1つには改行があり、もう1つには改行がありません。
それを無視して同じものとして扱いたい場合は、末尾の改行を削除できます:
select distinct rtrim(col, chr(10))
from your_table;
同じサンプルデータを使用したデモ:
-- CTE for sample data
with your_table (col) as (
select 'Testdata' || chr(10) from dual
union all
select 'Testdata' from dual
)
select col
from your_table;
COL
---------
Testdata
Testdata
-- CTE for sample data
with your_table (col) as (
select 'Testdata' || chr(10) from dual
union all
select 'Testdata' from dual
)
select distinct rtrim(col, chr(10)) as col
from your_table;
COL
---------
Testdata