PythonとSQLは、データアナリストにとって最も重要な言語の2つです。
この記事では、PythonとSQLを接続するために知っておく必要のあるすべてのことを説明します。
リレーショナルデータベースから機械学習パイプラインに直接データをプルする方法、Pythonアプリケーションからのデータを独自のデータベースに保存する方法、またはその他のユースケースを思いつく方法を学びます。
一緒にカバーします:
- PythonとSQLを一緒に使用する方法を学ぶ理由
- Python環境とMySQLサーバーをセットアップする方法
- PythonでMySQLサーバーに接続する
- 新しいデータベースの作成
- テーブルとテーブルの関係の作成
- テーブルにデータを入力する
- データの読み取り
- レコードの更新
- レコードの削除
- Pythonリストからのレコードの作成
- 将来、これらすべてを実行するための再利用可能な関数を作成する
それは非常に便利で非常にクールなものがたくさんあります。始めましょう!
始める前の簡単なメモ:このGitHubリポジトリには、このチュートリアルで使用されているすべてのコードを含むJupyterNotebookがあります。一緒にコーディングすることを強くお勧めします!
ここで使用されているデータベースとSQLコードはすべて、Towards Data Scienceに投稿された以前のSQL入門シリーズのものです(記事の表示に問題がある場合はご連絡ください。無料で表示するためのリンクをお送りします)。
SQLとリレーショナルデータベースの背後にある概念に精通していない場合は、そのシリーズを紹介します(さらに、freeCodeCampにはもちろん膨大な量のすばらしいものがあります!)
データアナリストとデータサイエンティストにとって、Pythonには多くの利点があります。膨大な範囲のオープンソースライブラリにより、データアナリストにとって非常に便利なツールになっています。
パンダ、データ分析用のNumPyとVaex、視覚化用のMatplotlib、seabornとBokeh、機械学習アプリケーション用のTensorFlow、scikit-learn、PyTorch(さらに多くの)があります。
(比較的)簡単な学習曲線と汎用性により、Pythonが最も急速に成長しているプログラミング言語の1つであることは不思議ではありません。
したがって、データ分析にPythonを使用している場合は、質問する価値があります。このすべてのデータはどこから来ているのでしょうか。
データセットには多種多様なソースがありますが、多くの場合、特にエンタープライズビジネスでは、データはリレーショナルデータベースに保存されます。リレーショナルデータベースは、あらゆる種類のデータを作成、読み取り、更新、および削除するための非常に効率的で強力な、広く使用されている方法です。
最も広く使用されているリレーショナルデータベース管理システム(RDBMS)(Oracle、MySQL、Microsoft SQL Server、PostgreSQL、IBM DB2)はすべて、構造化照会言語(SQL)を使用してデータにアクセスし、データを変更します。
各RDBMSはわずかに異なるフレーバーのSQLを使用するため、あるために記述されたSQLコードは、通常、(通常はかなりマイナーな)変更なしでは別のRDBMSでは機能しないことに注意してください。ただし、概念、構造、および操作はほとんど同じです。
これは、作業中のデータアナリストにとって、SQLを深く理解することが非常に重要であることを意味します。 PythonとSQLを一緒に使用する方法を知っていると、データの操作に関してさらに多くの利点が得られます。
この記事の残りの部分では、その方法を正確に説明します。
このチュートリアルと一緒にコーディングするには、独自のPython環境をセットアップする必要があります。
私はAnacondaを使用していますが、これを行う方法はたくさんあります。さらにヘルプが必要な場合は、「Pythonのインストール方法」をグーグルで検索してください。 Binderを使用して、関連するJupyterNotebookと一緒にコーディングすることもできます。
MySQL Community Serverは無料で、業界で広く使用されているため、使用します。 Windowsを使用している場合は、このガイドがセットアップに役立ちます。 MacおよびLinuxユーザー向けのガイドもあります(ただし、Linuxディストリビューションによって異なる場合があります)。
それらを設定したら、それらを相互に通信させる必要があります。
そのためには、MySQLConnectorPythonライブラリをインストールする必要があります。これを行うには、指示に従うか、pipを使用します:
pip install mysql-connector-pythonパンダも使用する予定ですので、パンダもインストールしてください。
pip install pandasPythonのすべてのプロジェクトと同様に、最初に実行したいのはライブラリをインポートすることです。
プロジェクトの開始時に使用するすべてのライブラリをインポートすることをお勧めします。そうすれば、コードを読んだりレビューしたりする人々は、何が起こるかを大まかに知っているので、驚くことはありません。
このチュートリアルでは、MySQLコネクタとパンダの2つのライブラリのみを使用します。
import mysql.connector
from mysql.connector import Error
import pandas as pdError関数を個別にインポートして、関数から簡単にアクセスできるようにします。
MySQLサーバーへの接続
この時点で、システムにMySQLCommunityServerをセットアップする必要があります。次に、そのサーバーへの接続を確立できるようにするコードをPythonで作成する必要があります。
def create_server_connection(host_name, user_name, user_password):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionこのようなコードで再利用可能な関数を作成することはベストプラクティスであり、最小限の労力でこれを何度も使用できます。これが書かれると、将来的にもすべてのプロジェクトで再利用できるようになります。将来的には、感謝するでしょう!
ここで何が起こっているのかを理解するために、この行を1行ずつ見ていきましょう:
最初の行は、関数に名前を付け(create_server_connection)、その関数が取る引数に名前を付けています(host_name、user_name、user_password)。
次の行は、サーバーが複数の開いている接続と混同されないように、既存の接続をすべて閉じます。
次に、Pythonのtry-exceptブロックを使用して、潜在的なエラーを処理します。最初の部分は、引数でユーザーが指定した詳細を使用してmysql.connector.connect()メソッドを使用してサーバーへの接続を作成しようとします。これが機能する場合、関数は幸せな小さな成功メッセージを出力します。
ブロックのexcept部分は、エラーがあるという不幸な状況で、MySQLサーバーが返すエラーを出力します。
最後に、接続が成功すると、関数は接続オブジェクトを返します。
実際には、関数の出力を変数に割り当て、それが接続オブジェクトになることで、これを使用します。次に、他のメソッド(カーソルなど)を適用して、他の便利なオブジェクトを作成できます。
connection = create_server_connection("localhost", "root", pw)これにより、成功メッセージが生成されます:

接続が確立されたので、次のステップはサーバー上に新しいデータベースを作成することです。
このチュートリアルでは、これを1回だけ実行しますが、これを再利用可能な関数として記述し、将来のプロジェクトで再利用できる便利な関数を作成します。
def create_database(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
print("Database created successfully")
except Error as err:
print(f"Error: '{err}'")この関数は、connection(接続オブジェクト)とquery(次のステップで記述するSQLクエリ)の2つの引数を取ります。接続を介してサーバーでクエリを実行します。
接続オブジェクトでcursorメソッドを使用してカーソルオブジェクトを作成します(MySQLコネクタはオブジェクト指向プログラミングパラダイムを使用するため、親オブジェクトからプロパティを継承するオブジェクトが多数あります)。
このカーソルオブジェクトには、execute、executemany(このチュートリアルで使用します)などのメソッドと、他のいくつかの便利なメソッドがあります。
それが役立つ場合は、カーソルオブジェクトをMySQLサーバーターミナルウィンドウで点滅しているカーソルへのアクセスを提供するものと考えることができます。
次に、データベースを作成して関数を呼び出すクエリを定義します。

このチュートリアルで使用されるすべてのSQLクエリは、SQLチュートリアルシリーズの概要で説明されています。完全なコードは、このGitHubリポジトリの関連するJupyter Notebookにあるため、SQLコードがこの中で何をするかについては説明しません。チュートリアル。
ただし、これはおそらく可能な限り最も単純なSQLクエリです。あなたが英語を読むことができれば、おそらくそれが何をするのかを理解することができます!
上記の引数を指定してcreate_database関数を実行すると、サーバーに「school」というデータベースが作成されます。
私たちのデータベースが「学校」と呼ばれるのはなぜですか?おそらく今は、このチュートリアルで実装しようとしていることを正確に詳しく調べる良い機会になるでしょう。
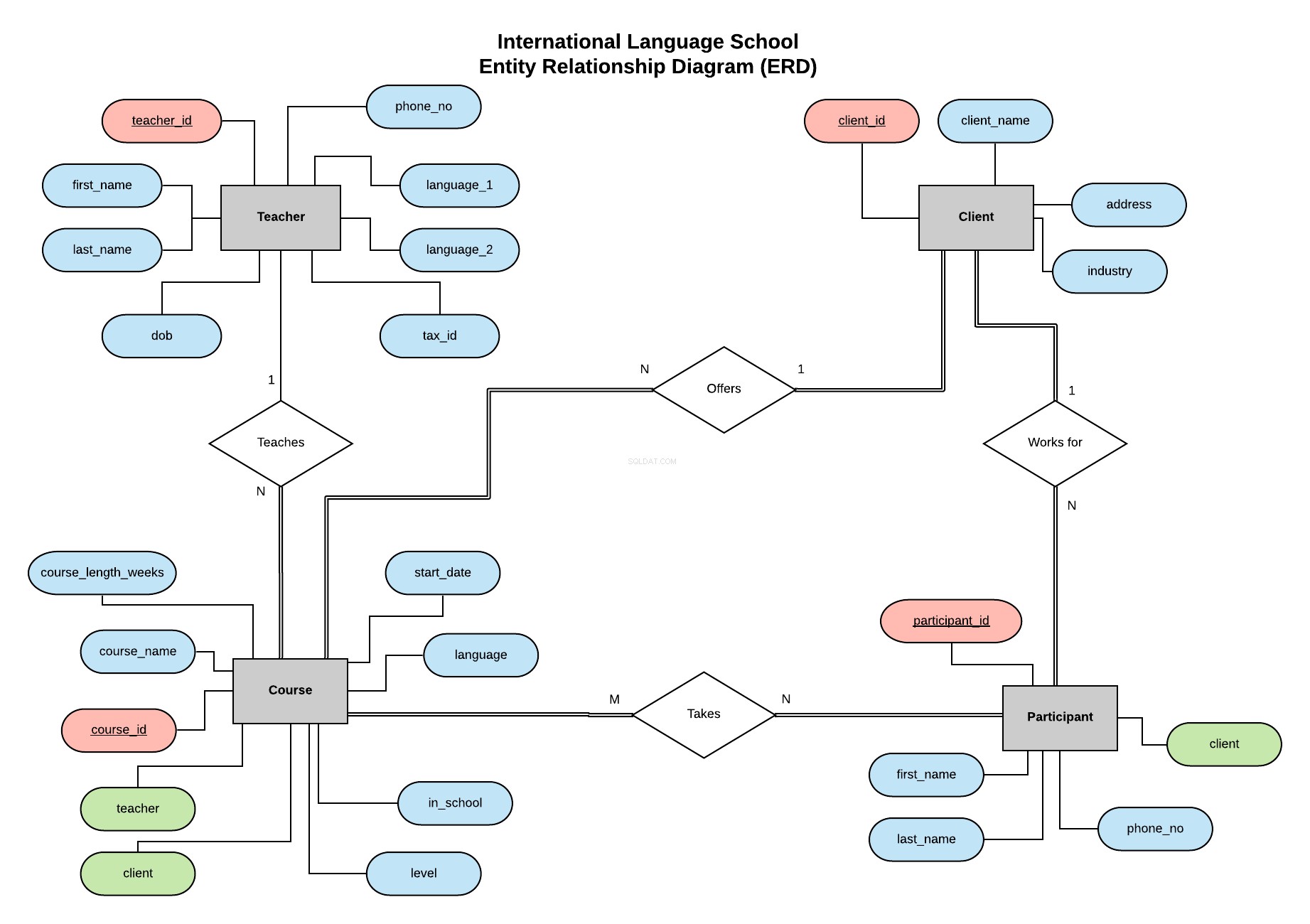
前回のシリーズの例に続いて、国際語学学校のデータベースを実装します。これは、企業のクライアントに専門的な語学レッスンを提供する架空の語学研修学校です。
この実体関連図(ERD)は、実体(教師、クライアント、コース、参加者)をレイアウトし、それらの間の関係を定義します。
ERDとは何か、およびERDを作成してデータベースを設計する際に考慮すべきことに関するすべての情報は、この記事に記載されています。
生のSQLコード、データベース要件、およびデータベースに入力するデータはすべてこのGitHubリポジトリに含まれていますが、このチュートリアルを実行するときにすべてが表示されます。
MySQLサーバーでデータベースを作成したので、create_server_connection関数を変更して、このデータベースに直接接続できます。
1つのMySQLサーバーに複数のデータベースが存在する可能性があることに注意してください。そのため、関心のあるデータベースに常に自動的に接続する必要があります。
私たちはこのようにこれを行うことができます:
def create_db_connection(host_name, user_name, user_password, db_name):
connection = None
try:
connection = mysql.connector.connect(
host=host_name,
user=user_name,
passwd=user_password,
database=db_name
)
print("MySQL Database connection successful")
except Error as err:
print(f"Error: '{err}'")
return connectionこれはまったく同じ関数ですが、もう1つの引数(データベース名)を取り、それを引数としてconnect()メソッドに渡します。
(今のところ)作成する最後の関数は、非常に重要な関数、つまりクエリ実行関数です。これにより、Pythonに文字列として格納されているSQLクエリを取得し、cursor.execute()メソッドに渡してサーバー上で実行します。
def execute_query(connection, query):
cursor = connection.cursor()
try:
cursor.execute(query)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")この関数は、前のcreate_database関数とまったく同じですが、connection.commit()メソッドを使用して、SQLクエリで詳細に説明されているコマンドが実装されていることを確認します。
これが主力の関数になります。この関数を(create_db_connectionとともに)使用して、テーブルを作成し、それらのテーブル間の関係を確立し、テーブルにデータを入力し、データベースのレコードを更新および削除します。
SQLの専門家であれば、この関数を使用すると、Pythonスクリプトから直接、横になっている可能性のある複雑なコマンドやクエリをすべて実行できます。これは、データを管理するための非常に強力なツールになる可能性があります。
これで、サーバーへのSQLコマンドの実行を開始し、データベースの構築を開始する準備が整いました。最初にやりたいことは、必要なテーブルを作成することです。
先生のテーブルから始めましょう:
create_teacher_table = """
CREATE TABLE teacher (
teacher_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
language_1 VARCHAR(3) NOT NULL,
language_2 VARCHAR(3),
dob DATE,
tax_id INT UNIQUE,
phone_no VARCHAR(20)
);
"""
connection = create_db_connection("localhost", "root", pw, db) # Connect to the Database
execute_query(connection, create_teacher_table) # Execute our defined queryまず、SQLコマンド(ここで詳しく説明します)を適切な名前の変数に割り当てます。
この場合、複数行の文字列にPythonのトリプルクォート表記を使用してSQLクエリを格納し、それをexecute_query関数にフィードして実装します。
この複数行のフォーマットは、純粋に人間がコードを読むためのものであることに注意してください。 SQLコマンドがこのように分散されている場合、SQLもPythonも「気にしません」。構文が正しい限り、両方の言語がそれを受け入れます。
ただし、コードを読む人間の利益のために(たとえそれが将来のことになるとしても!)、コードをより読みやすく理解しやすくするためにこれを行うことは非常に便利です。
SQLの演算子のCAPITALIZATIONについても同じことが言えます。これは広く使用されている規則であり、強くお勧めしますが、コードを実行する実際のソフトウェアでは大文字と小文字が区別されず、「CREATETABLEteacher」と「createtableteacher」は同じコマンドとして扱われます。

このコードを実行すると、成功メッセージが表示されます。これは、MySQLサーバーのコマンドラインクライアントでも確認できます:
素晴らしい!次に、残りのテーブルを作成しましょう。
create_client_table = """
CREATE TABLE client (
client_id INT PRIMARY KEY,
client_name VARCHAR(40) NOT NULL,
address VARCHAR(60) NOT NULL,
industry VARCHAR(20)
);
"""
create_participant_table = """
CREATE TABLE participant (
participant_id INT PRIMARY KEY,
first_name VARCHAR(40) NOT NULL,
last_name VARCHAR(40) NOT NULL,
phone_no VARCHAR(20),
client INT
);
"""
create_course_table = """
CREATE TABLE course (
course_id INT PRIMARY KEY,
course_name VARCHAR(40) NOT NULL,
language VARCHAR(3) NOT NULL,
level VARCHAR(2),
course_length_weeks INT,
start_date DATE,
in_school BOOLEAN,
teacher INT,
client INT
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, create_client_table)
execute_query(connection, create_participant_table)
execute_query(connection, create_course_table)これにより、4つのエンティティに必要な4つのテーブルが作成されます。
次に、それらの間の関係を定義し、参加者とコーステーブルの間の多対多の関係を処理するためのもう1つのテーブルを作成します(詳細については、ここを参照してください)。
これはまったく同じ方法で行います:
alter_participant = """
ALTER TABLE participant
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
alter_course = """
ALTER TABLE course
ADD FOREIGN KEY(teacher)
REFERENCES teacher(teacher_id)
ON DELETE SET NULL;
"""
alter_course_again = """
ALTER TABLE course
ADD FOREIGN KEY(client)
REFERENCES client(client_id)
ON DELETE SET NULL;
"""
create_takescourse_table = """
CREATE TABLE takes_course (
participant_id INT,
course_id INT,
PRIMARY KEY(participant_id, course_id),
FOREIGN KEY(participant_id) REFERENCES participant(participant_id) ON DELETE CASCADE,
FOREIGN KEY(course_id) REFERENCES course(course_id) ON DELETE CASCADE
);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, alter_participant)
execute_query(connection, alter_course)
execute_query(connection, alter_course_again)
execute_query(connection, create_takescourse_table)これで、適切な制約、主キー、および外部キーの関係とともに、テーブルが作成されました。
次のステップは、テーブルにいくつかのレコードを追加することです。ここでも、execute_queryを使用して、既存のSQLコマンドをサーバーにフィードします。もう一度Teacherテーブルから始めましょう。
pop_teacher = """
INSERT INTO teacher VALUES
(1, 'James', 'Smith', 'ENG', NULL, '1985-04-20', 12345, '+491774553676'),
(2, 'Stefanie', 'Martin', 'FRA', NULL, '1970-02-17', 23456, '+491234567890'),
(3, 'Steve', 'Wang', 'MAN', 'ENG', '1990-11-12', 34567, '+447840921333'),
(4, 'Friederike', 'Müller-Rossi', 'DEU', 'ITA', '1987-07-07', 45678, '+492345678901'),
(5, 'Isobel', 'Ivanova', 'RUS', 'ENG', '1963-05-30', 56789, '+491772635467'),
(6, 'Niamh', 'Murphy', 'ENG', 'IRI', '1995-09-08', 67890, '+491231231232');
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_teacher)これは機能しますか? MySQLコマンドラインクライアントで再度確認できます:
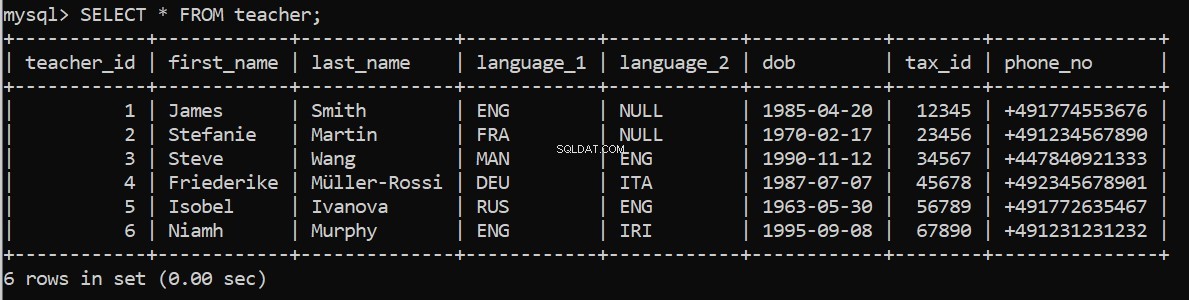
次に、残りのテーブルにデータを入力します。
pop_client = """
INSERT INTO client VALUES
(101, 'Big Business Federation', '123 Falschungstraße, 10999 Berlin', 'NGO'),
(102, 'eCommerce GmbH', '27 Ersatz Allee, 10317 Berlin', 'Retail'),
(103, 'AutoMaker AG', '20 Künstlichstraße, 10023 Berlin', 'Auto'),
(104, 'Banko Bank', '12 Betrugstraße, 12345 Berlin', 'Banking'),
(105, 'WeMoveIt GmbH', '138 Arglistweg, 10065 Berlin', 'Logistics');
"""
pop_participant = """
INSERT INTO participant VALUES
(101, 'Marina', 'Berg','491635558182', 101),
(102, 'Andrea', 'Duerr', '49159555740', 101),
(103, 'Philipp', 'Probst', '49155555692', 102),
(104, 'René', 'Brandt', '4916355546', 102),
(105, 'Susanne', 'Shuster', '49155555779', 102),
(106, 'Christian', 'Schreiner', '49162555375', 101),
(107, 'Harry', 'Kim', '49177555633', 101),
(108, 'Jan', 'Nowak', '49151555824', 101),
(109, 'Pablo', 'Garcia', '49162555176', 101),
(110, 'Melanie', 'Dreschler', '49151555527', 103),
(111, 'Dieter', 'Durr', '49178555311', 103),
(112, 'Max', 'Mustermann', '49152555195', 104),
(113, 'Maxine', 'Mustermann', '49177555355', 104),
(114, 'Heiko', 'Fleischer', '49155555581', 105);
"""
pop_course = """
INSERT INTO course VALUES
(12, 'English for Logistics', 'ENG', 'A1', 10, '2020-02-01', TRUE, 1, 105),
(13, 'Beginner English', 'ENG', 'A2', 40, '2019-11-12', FALSE, 6, 101),
(14, 'Intermediate English', 'ENG', 'B2', 40, '2019-11-12', FALSE, 6, 101),
(15, 'Advanced English', 'ENG', 'C1', 40, '2019-11-12', FALSE, 6, 101),
(16, 'Mandarin für Autoindustrie', 'MAN', 'B1', 15, '2020-01-15', TRUE, 3, 103),
(17, 'Français intermédiaire', 'FRA', 'B1', 18, '2020-04-03', FALSE, 2, 101),
(18, 'Deutsch für Anfänger', 'DEU', 'A2', 8, '2020-02-14', TRUE, 4, 102),
(19, 'Intermediate English', 'ENG', 'B2', 10, '2020-03-29', FALSE, 1, 104),
(20, 'Fortgeschrittenes Russisch', 'RUS', 'C1', 4, '2020-04-08', FALSE, 5, 103);
"""
pop_takescourse = """
INSERT INTO takes_course VALUES
(101, 15),
(101, 17),
(102, 17),
(103, 18),
(104, 18),
(105, 18),
(106, 13),
(107, 13),
(108, 13),
(109, 14),
(109, 15),
(110, 16),
(110, 20),
(111, 16),
(114, 12),
(112, 19),
(113, 19);
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, pop_client)
execute_query(connection, pop_participant)
execute_query(connection, pop_course)
execute_query(connection, pop_takescourse)すばらしい!これで、Pythonコマンドのみを使用して、MySQLのリレーション、制約、およびレコードを備えたデータベースを作成しました。
理解しやすいように、この手順を段階的に実行してきました。しかし、この時点で、これはすべて1つのPythonスクリプトに非常に簡単に記述でき、ターミナルの1つのコマンドで実行できることがわかります。強力なもの。
これで、使用できる機能データベースができました。データアナリストとして、あなたはあなたが働いている組織の既存のデータベースと接触する可能性があります。これらのデータベースからデータをプルして、Pythonデータパイプラインにフィードできるようにする方法を知っておくと非常に便利です。これが次に取り組むことです。
このために、もう1つの関数が必要になります。今回は、cursor.commit()の代わりにcursor.fetchall()を使用します。この機能を使用すると、データベースからデータを読み取り、変更を加えることはありません。
def read_query(connection, query):
cursor = connection.cursor()
result = None
try:
cursor.execute(query)
result = cursor.fetchall()
return result
except Error as err:
print(f"Error: '{err}'")繰り返しますが、execute_queryと非常によく似た方法でこれを実装します。簡単なクエリで試して、どのように機能するかを確認してみましょう。
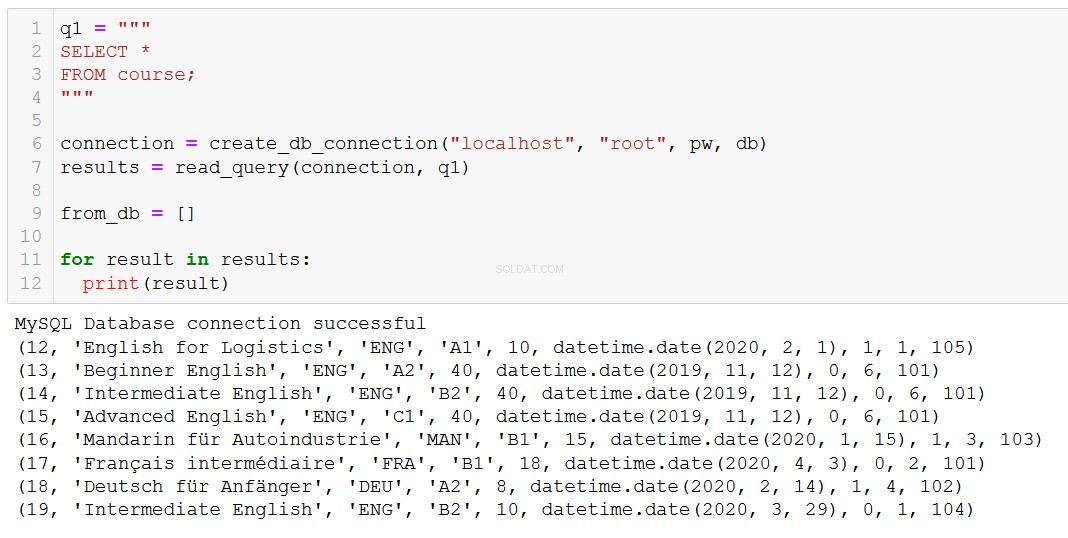
q1 = """
SELECT *
FROM teacher;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q1)
for result in results:
print(result)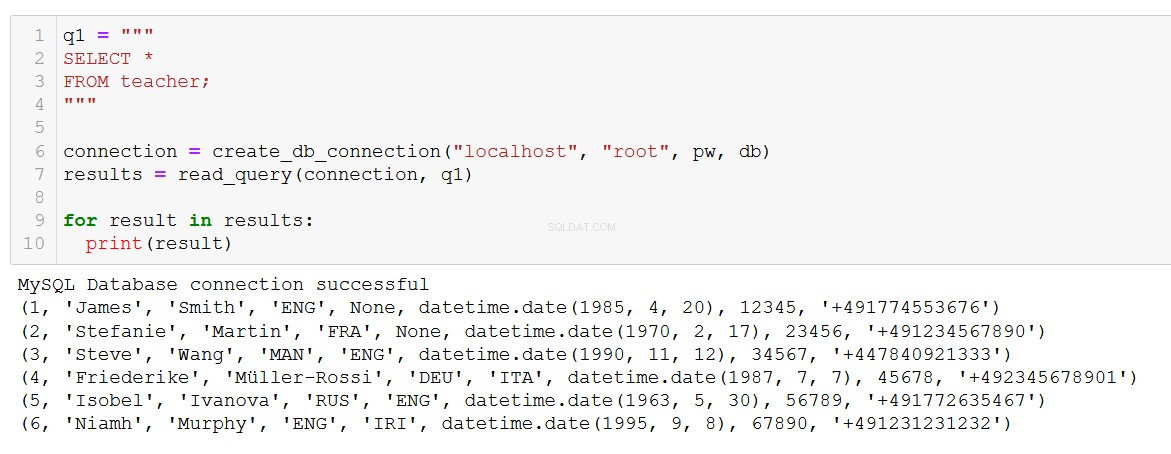
まさに私たちが期待していることです。この関数は、コーステーブルとクライアントテーブルのJOINを含む、より複雑なクエリでも機能します。
q5 = """
SELECT course.course_id, course.course_name, course.language, client.client_name, client.address
FROM course
JOIN client
ON course.client = client.client_id
WHERE course.in_school = FALSE;
"""
connection = create_db_connection("localhost", "root", pw, db)
results = read_query(connection, q5)
for result in results:
print(result)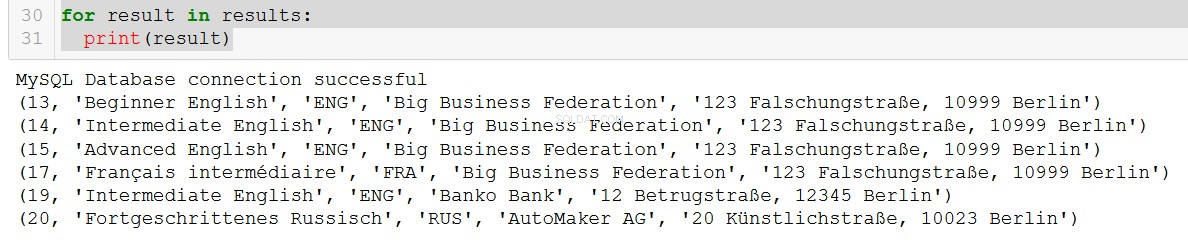
非常に素晴らしい。
Pythonのデータパイプラインとワークフローでは、これらの結果をさまざまな形式で取得して、より便利にしたり、操作できるようにしたりすることができます。
いくつかの例を見て、それをどのように行うことができるかを見てみましょう。
#Initialise empty list
from_db = []
# Loop over the results and append them into our list
# Returns a list of tuples
for result in results:
result = result
from_db.append(result)
# Returns a list of lists
from_db = []
for result in results:
result = list(result)
from_db.append(result)
Pythonを使用するデータアナリストにとって、パンダは私たちの美しく信頼できる旧友です。データベースからの出力をDataFrameに変換するのは非常に簡単で、そこから可能性は無限大です!
# Returns a list of lists and then creates a pandas DataFrame
from_db = []
for result in results:
result = list(result)
from_db.append(result)
columns = ["course_id", "course_name", "language", "client_name", "address"]
df = pd.DataFrame(from_db, columns=columns)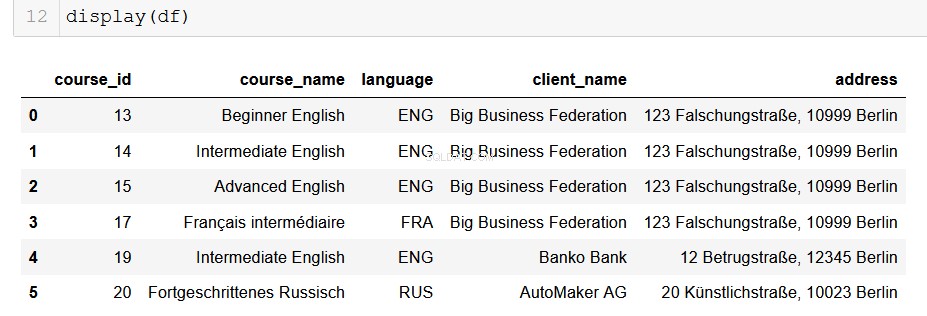
うまくいけば、ここであなたの目の前で展開する可能性を見ることができます。ほんの数行のコードで、処理できるすべてのデータを、それが存在するリレーショナルデータベースから簡単に抽出し、最先端のデータ分析パイプラインに取り込むことができます。これは本当に役立つものです。
データベースを維持しているとき、既存のレコードに変更を加える必要がある場合があります。このセクションでは、その方法を見ていきます。
ILSに、既存のクライアントの1つであるBig BusinessFederationがオフィスを23Fingiertweg、14534Berlinに移転することが通知されたとします。この場合、データベース管理者(私たちです!)はいくつかの変更を加える必要があります。
ありがたいことに、SQLUPDATEステートメントと一緒にexecute_query関数を使用してこれを行うことができます。
update = """
UPDATE client
SET address = '23 Fingiertweg, 14534 Berlin'
WHERE client_id = 101;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, update)ここでは、WHERE句が非常に重要であることに注意してください。 WHERE句を指定せずにこのクエリを実行すると、Clientテーブルのすべてのレコードのすべてのアドレスが23Fingiertwegに更新されます。それは私たちがやろうとしていることではありません。
また、UPDATEクエリで「WHEREclient_id=101」を使用したことにも注意してください。 「WHEREclient_name='BigBusinessFederation'」または「WHEREaddress='123Falschungstraße、10999Berlin'」または「WHEREaddressLIKE'%Falschung%'」を使用することも可能でした。
重要なことは、WHERE句を使用すると、更新する1つまたは複数のレコードを一意に識別できることです。
また、execute_query関数を使用して、DELETEを使用してレコードを削除することもできます。
リレーショナルデータベースでSQLを使用する場合は、DELETE演算子の使用に注意する必要があります。これはWindowsではなく、「これを削除してもよろしいですか?」というものはありません。警告ポップアップが表示され、ごみ箱はありません。何かを削除すると、それは本当になくなります。
そうは言っても、私たちは本当に時々物事を削除する必要があります。それでは、コーステーブルからコースを削除して見てみましょう。
まず、どのコースがあるかを思い出してみましょう。
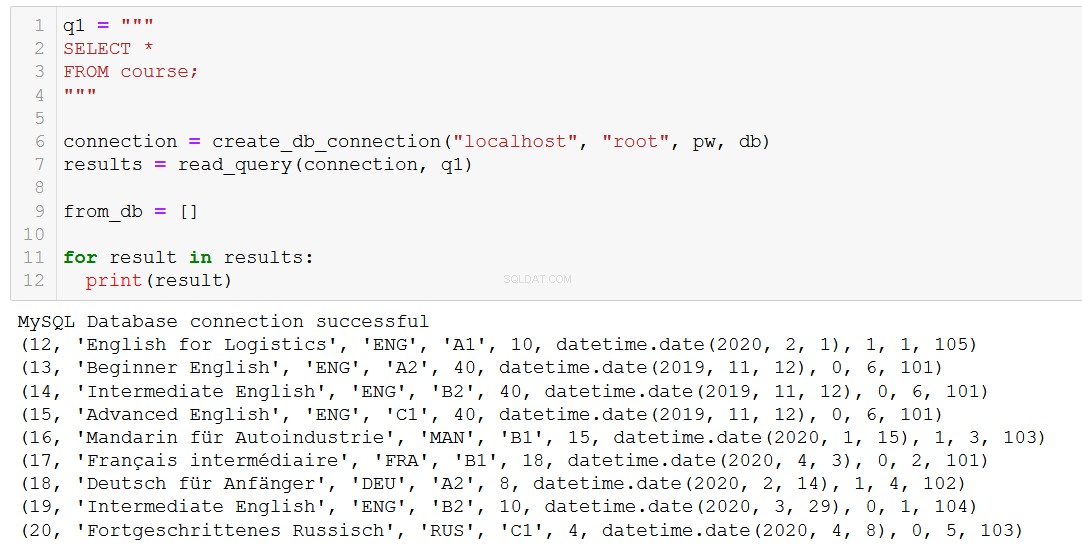
コース20「FortgeschrittenesRussisch」(あなたと私にとっては「上級ロシア語」)が終わりに近づいているとしましょう。データベースから削除する必要があります。
この段階までに、これを行う方法にまったく驚かないでしょう。SQLコマンドを文字列として保存し、それを主力のexecute_query関数にフィードします。
delete_course = """
DELETE FROM course
WHERE course_id = 20;
"""
connection = create_db_connection("localhost", "root", pw, db)
execute_query(connection, delete_course)意図した効果があったことを確認しましょう:
予想通り、「上級ロシア語」はなくなりました。
これは、DROP COLUMNを使用して列全体を削除し、DROP TABLEコマンドを使用してテーブル全体を削除する場合にも機能しますが、このチュートリアルではそれらについては説明しません。
ただし、これらを試してみてください。架空の学校のデータベースから列やテーブルを削除してもかまいません。本番環境に移行する前に、これらのコマンドに慣れておくことをお勧めします。
>この時点で、永続データストレージの4つの主要な操作を完了することができます。
次の方法を学びました:
- 作成-まったく新しいデータベース、テーブル、レコード
- 読み取り-データベースからデータを抽出し、そのデータを複数の形式で保存します
- 更新-データベース内の既存のレコードに変更を加えます
- 削除-不要になったレコードを削除します
これらは、実行できる非常に便利なことです。
ここで作業を終える前に、もう1つ非常に便利なスキルを習得する必要があります。
テーブルにデータを入力すると、execute_query関数でSQL INSERTコマンドを使用して、データベースにレコードを挿入できることがわかりました。
Pythonを使用してSQLデータベースを操作している場合、Pythonデータ構造(リストなど)を取得してデータベースに直接挿入できると便利です。
これは、Pythonで作成したソーシャルメディアアプリにユーザーアクティビティのログを保存したり、ユーザーから作成したWikiにユーザーから入力したりする場合に役立ちます。あなたが考えることができる限りこれの可能な多くの使用法があります。
この方法は、データベース全体が損傷したり破壊されたりする可能性のあるSQLインジェクション攻撃を防ぐのに役立つため、データベースがいつでもユーザーに公開されている場合にも、より安全になります。
これを行うには、これまで使用していた単純なexecute()メソッドの代わりに、executemany()メソッドを使用して関数を記述します。
def execute_list_query(connection, sql, val):
cursor = connection.cursor()
try:
cursor.executemany(sql, val)
connection.commit()
print("Query successful")
except Error as err:
print(f"Error: '{err}'")これで関数ができました。SQLコマンド('sql')と、データベースに入力する値('val')を含むリストを定義する必要があります。値はタプルのリストとして保存する必要があります。これは、Pythonでデータを保存するためのかなり一般的な方法です。
データベースに2人の新しい教師を追加するには、次のようなコードを記述します。
sql = '''
INSERT INTO teacher (teacher_id, first_name, last_name, language_1, language_2, dob, tax_id, phone_no)
VALUES (%s, %s, %s, %s, %s, %s, %s, %s)
'''
val = [
(7, 'Hank', 'Dodson', 'ENG', None, '1991-12-23', 11111, '+491772345678'),
(8, 'Sue', 'Perkins', 'MAN', 'ENG', '1976-02-02', 22222, '+491443456432')
]ここで、「sql」コードでは、値のプレースホルダーとして「%s」を使用していることに注意してください。 Pythonの文字列の'%s'プレースホルダーとの類似性は偶然です(そして率直に言って、非常に紛らわしいです)。MySQLPythonではすべてのデータ型(文字列、int、日付など)に'%s'を使用します。コネクタ。
Stackoverflowで、Pythonでこれを行うのに慣れているために、誰かが混乱して整数に'%d'プレースホルダーを使用しようとした多くの質問を見ることができます。これはここでは機能しません。値を追加する列ごとに「%s」を使用する必要があります。
次に、executemany関数は、「val」リスト内の各タプルを取得し、プレースホルダーの代わりにその列に関連する値を挿入し、リストに含まれる各タプルに対してSQLコマンドを実行します。
これは、正しくフォーマットされている限り、複数行のデータに対して実行できます。この例では、説明のために2人の新しい教師を追加しますが、原則として、必要な数だけ追加できます。
先に進んでこのクエリを実行し、教師をデータベースに追加しましょう。
connection = create_db_connection("localhost", "root", pw, db)
execute_list_query(connection, sql, val)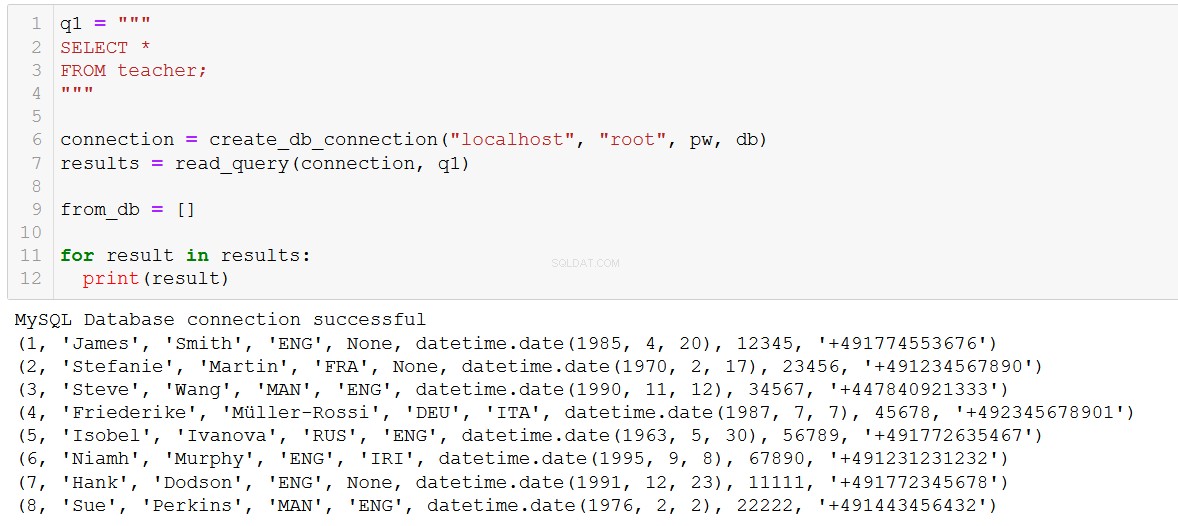
ILS、ハンクとスーへようこそ!
This is yet another deeply useful function, allowing us to take data generated in our Python scripts and applications, and enter them directly into our database.
We have covered a lot of ground in this tutorial.
We have learned how to use Python and MySQL Connector to create an entirely new database in MySQL Server, create tables within that database, define the relationships between those tables, and populate them with data.
We have covered how to Create, Read, Update and Delete data in our database.
We have looked at how to extract data from existing databases and load them into pandas DataFrames, ready for analysis and further work taking advantage of all the possibilities offered by the PyData stack.
Going in the other direction, we have also learned how to take data generated by our Python scripts and applications, and write those into a database where they can be safely stored for later retrieval and manipulation.
I hope this tutorial has helped you to see how we can use Python and SQL together to be able to manipulate data even more effectively!
If you'd like to see more of my projects and work, please visit my website at craigdoesdata.de. If you have any feedback on this tutorial, please contact me directly - all feedback is warmly received!
