クエリパフォーマンスの低下は、DBAが対処しなければならない最も一般的な問題です。クエリのパフォーマンスに関連するデータを収集、処理、分析する方法は多数あります。これまでのブログ投稿のいくつかで、最も人気のあるツールの1つであるpt-query-digestについて説明しました。
MySQLDBAブログシリーズになる
- pt-query-digestを使用したSQLワークロードの分析
- pt-query-digestを使用した詳細なSQLワークロード分析
ただし、ClusterControlを使用する場合、これは必ずしも必要ではありません。 ClusterControlで利用可能なデータを使用して、問題を解決できます。このブログ投稿では、ClusterControlがクエリのパフォーマンスに関連する問題の解決にどのように役立つかを調べます。
クエリがタイムリーに完了できない場合があります。いくつかのロックの問題が原因でクエリがスタックしている可能性があります。最適でないか、適切にインデックスが作成されていないか、重すぎて妥当な時間内に完了できない可能性があります。大規模な本番データベースがある場合、インデックス付けされていない結合のいくつかは、数十億行を簡単にスキャンできることに注意してください。何が起こったとしても、クエリはおそらくいくつかのリソースを使用しています-最適化されていないクエリのCPUまたはI / O、あるいは単に行ロックですら。これらのリソースは他のクエリにも必要であり、処理速度が大幅に低下する可能性があります。非常に単純でありながら重要なタスクの1つは、問題のあるクエリを特定して停止することです。
これは、ClusterControlインターフェイスから非常に簡単に実行できます。 [クエリモニター]タブ->[クエリの実行]セクションに移動します-以下のスクリーンショットのような出力が表示されます。
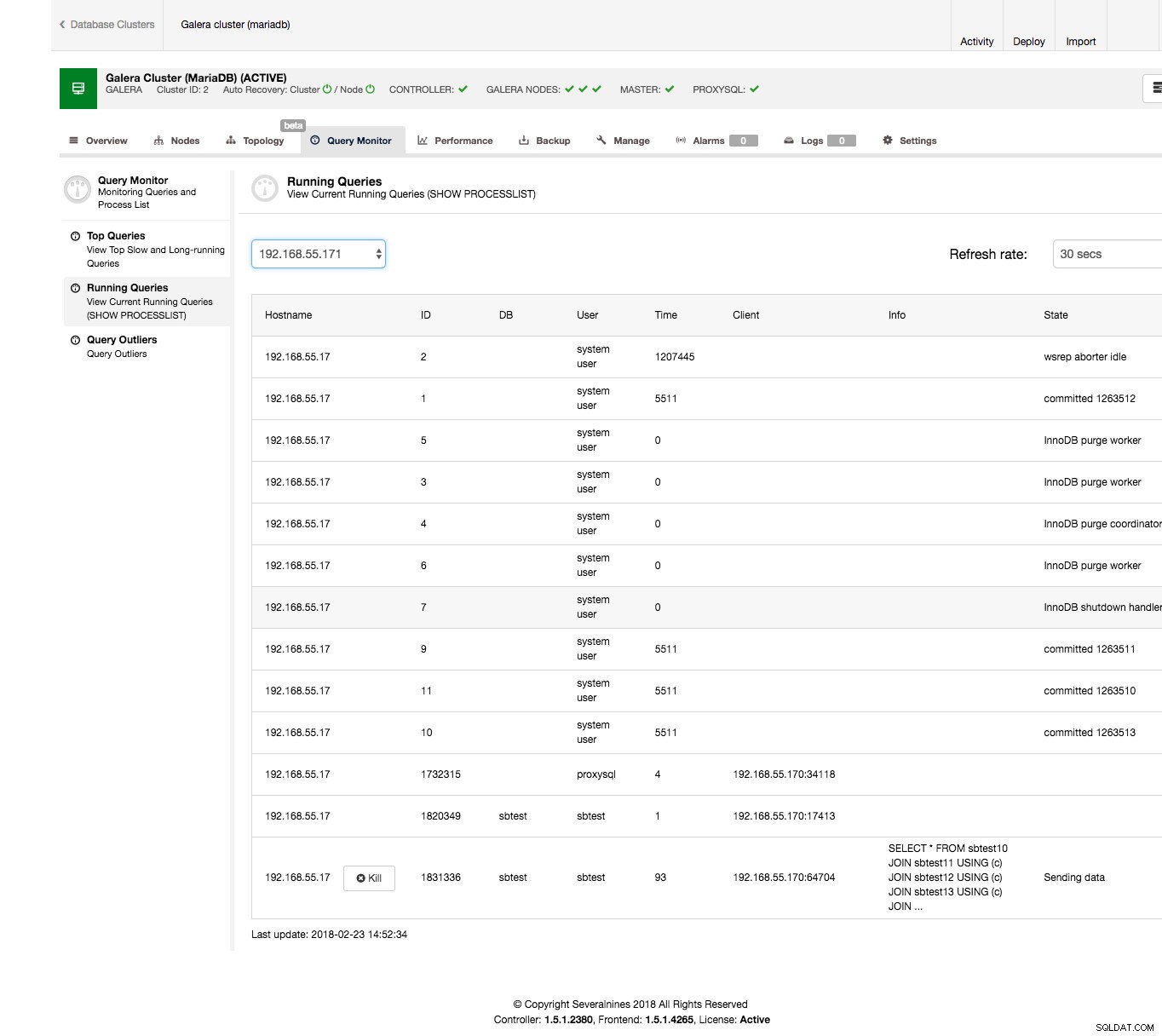
ご覧のとおり、クエリの山が詰まっています。通常、問題のあるクエリは時間がかかるクエリであるため、強制終了することをお勧めします。また、それをさらに調査して、正しいものを選択していることを確認することもできます。この例では、2つのテーブルを結合し、過去90秒間、データを処理していることを意味する「データの送信」状態にあるSELECT…FORUPDATEが明確に表示されます。
DBAが回答する必要がある可能性のある別のタイプの質問は、実行に最も時間がかかるクエリはどれですか。これはよくある質問です。そのようなクエリは簡単な成果である可能性があり、最適化できる可能性があります。また、クエリミックス全体で特定のクエリの実行時間が長くなるほど、最適化によるメリットは大きくなります。これは単純な方程式です。クエリが合計実行時間の50%を占める場合、10倍速くすると、合計実行時間のわずか1%を占めるクエリを最適化するよりもはるかに良い結果が得られます。
ClusterControlはそのような質問に答えるのに役立ちますが、最初にクエリモニターが有効になっていることを確認する必要があります。 [クエリモニター]ページで、[クエリモニター]を[オン]に切り替えることができます。さらに、ワークロードに合わせて、[設定]の下の[長いクエリ時間]および[インデックスを使用しないクエリのログ]オプションを構成できます。
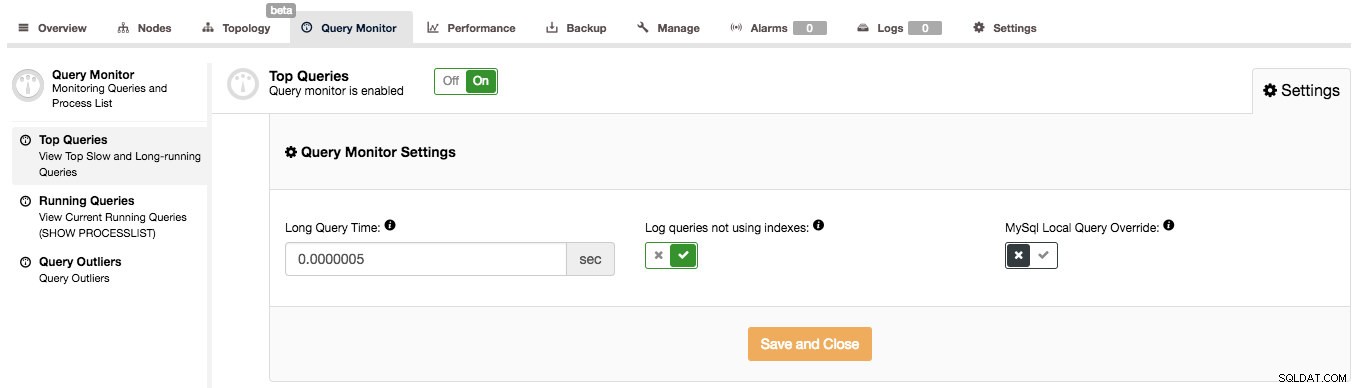
ClusterControlのクエリモニターは、実行中のクエリで必要なデータを使用できるパフォーマンススキーマがあるかどうかに応じて、2つのモードで動作します。利用可能な場合(MySQL 5.6以降ではデフォルトでこれが当てはまります)、パフォーマンススキーマを使用してクエリデータを収集し、システムへの影響を最小限に抑えます。それ以外の場合は、低速のクエリログが使用され、上のスクリーンショットに表示されているすべての設定が使用されます。これらはUIで非常によく説明されているため、ここで行う必要はありません。クエリモニターがパフォーマンススキーマを使用する場合、これらの設定は使用されません(データ収集を有効/無効にするためにクエリモニターのオン/オフを切り替える場合を除く)。
ClusterControlでクエリモニターが有効になっていることを確認したら、[クエリモニター]-> [上位のクエリ]に移動すると、次のような画面が表示されます。
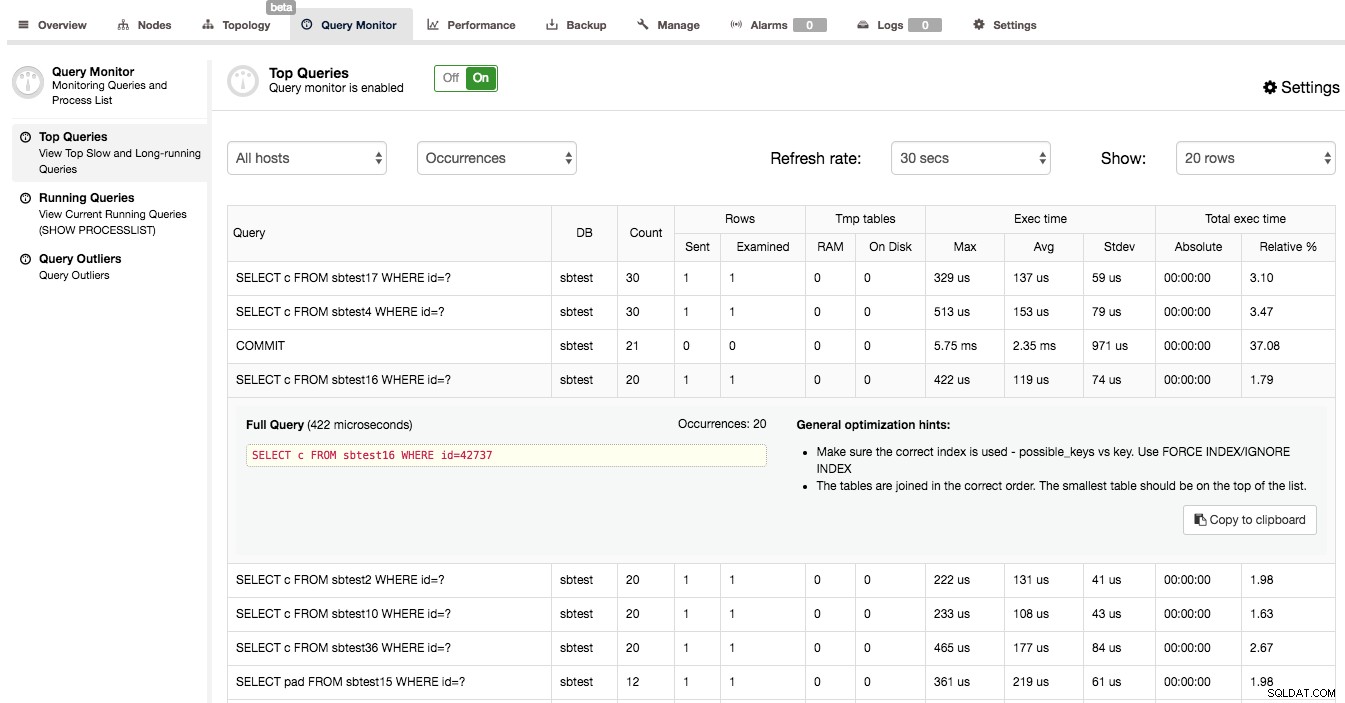
ここに表示されるのは、クラスターにヒットした最もコストのかかるクエリ(実行時間の観点から)のリストです。それぞれに、実行回数、検査またはクライアントに送信された行数、実行時間の変化、クラスターが特定のタイプのクエリの実行に費やした時間など、さらに詳細な情報があります。クエリは、クエリの種類とスキーマごとにグループ化されています。
実行時間が費やされる主な場所が「COMMIT」クエリであることに驚かれるかもしれません。実際、これは、Galeraクラスターで実行される迅速なOLTPクエリではかなり一般的です。認証が行われる必要があるため、トランザクションのコミットはコストのかかるプロセスです。これにより、COMMITはクエリミックスの中で最も時間のかかるクエリの1つになります。
クエリをクリックすると、クエリ全体、最大実行時間、発生回数、一般的な最適化のヒント、およびクエリのEXPLAIN出力が表示されます。これは、クエリに問題があるかどうかを特定するのに非常に役立ちます。この例では、多数の行を調べてSELECT…FORUPDATEをチェックしました。予想どおり、このクエリはひどいSQLの例です。インデックスを使用しないJOINです。 EXPLAINの出力を見ると、インデックスが使用されておらず、使用できると考えられているインデックスは1つもありません。このクエリがクラスターのパフォーマンスに深刻な影響を与えたのも不思議ではありません。
クエリのパフォーマンスに関する洞察を得るもう1つの方法は、[クエリモニター]->[クエリの外れ値]を確認することです。これは基本的に、パフォーマンスが平均と大幅に異なるクエリのリストです。
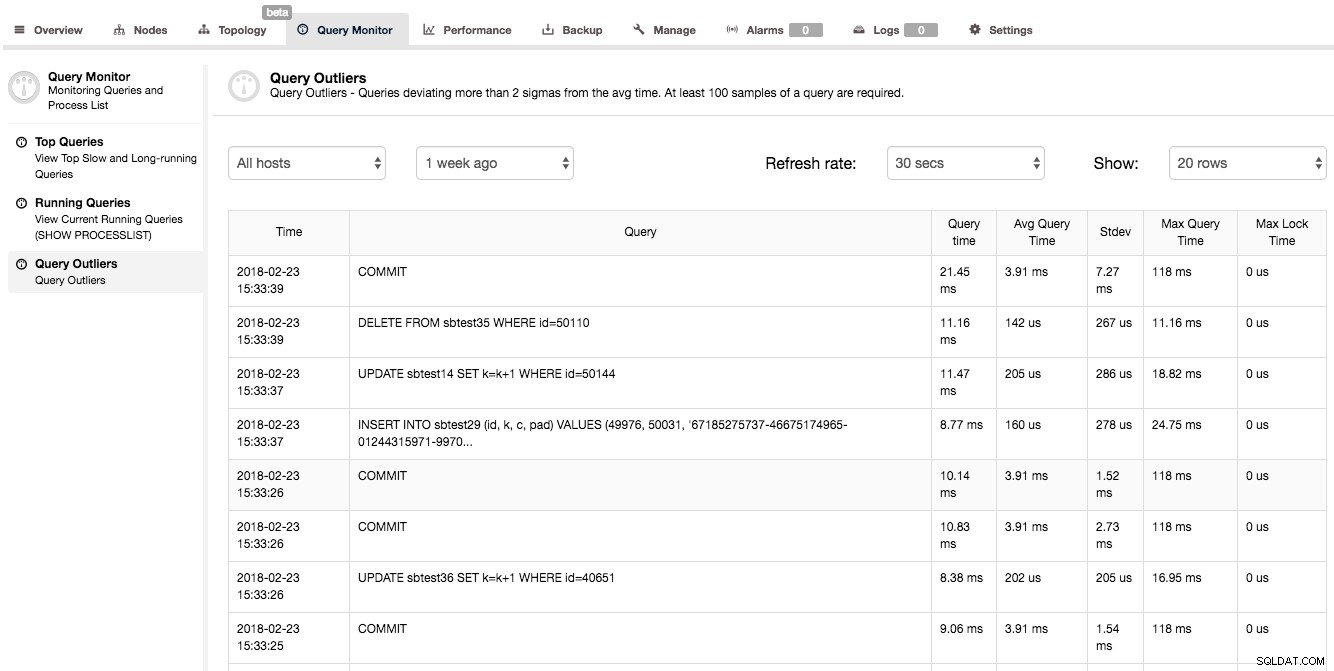
上のスクリーンショットでわかるように、2番目のクエリは0.01116秒(時間はミリ秒単位で表示されます)かかりましたが、そのクエリの平均実行時間ははるかに短い(0.000142秒)。標準偏差と最大クエリ実行時間に関する追加の統計情報もあります。このようなクエリのリストはあまり役に立たないように思われるかもしれませんが、実際にはそうではありません。このリストにクエリが表示されている場合は、通常とは何かが異なっていることを意味します。クエリは通常の時間に完了しませんでした。これは、システムのパフォーマンスの問題を示している可能性があり、他のメトリックを調査して、その時点で他に何かが発生していないかどうかを確認する必要があることを示している可能性があります。
人々は最大のパフォーマンスを達成することに集中する傾向があり、高いスループットを得るのに十分ではないことを忘れています-それはまた一貫している必要があります。ユーザーはパフォーマンスが安定していることを望んでいます。システムから1秒あたりのトランザクション数を増やすことができる場合がありますが、一部のトランザクションが数秒間停止し始めることを意味する場合は、それだけの価値はありません。 ClusterControlでクエリヒストグラムを確認すると、クエリミックスでこのような一貫性の問題を特定するのに役立ちます。
ハッピークエリモニタリング!
PS:ClusterControlの使用を開始するには、ここをクリックしてください!