仮想IPアドレスは、実際の物理ネットワークインターフェイスに対応していないIPアドレスです。複数のネットワークインターフェイス間でフロートし、フォールトトレランスとモビリティのために1つのアクティブなインターフェイスのみがIPアドレスを保持します。 ClusterControlはKeepalivedを使用して、データベースロードバランサーとの仮想IPアドレス統合を提供し、ロードバランサーレベルでの単一障害点(SPOF)を排除します。
このブログ投稿では、ClusterControlが仮想IPアドレスを構成する方法と、フェイルオーバーまたはフェイルバックが発生したときに期待できることを示します。この動作を理解することは、サービスの中断を最小限に抑え、時々実行する必要のあるメンテナンス操作をスムーズにするために不可欠です。
要件
ネットワークでKeepalivedを実行するには、いくつかの要件があります。
- IPプロトコル112(仮想ルーター冗長プロトコル-VRRP)がネットワークでサポートされている必要があります。一部のネットワーク、特にVLAN間通信では、VRRPのサポートが無効になっています。これをネットワーク管理者に確認してください。
- マルチキャストを使用する場合、ネットワークはマルチキャスト要求をサポートする必要があります(ip a | grep -iマルチキャストを使用)。それ以外の場合は、 unicast_src_ipを介してユニキャストを使用できます。 およびunicast_peer オプション。マルチキャストの使用は、クラウド環境のような動的な環境がある場合、またはIP割り当てがDHCPを介して実行される場合に役立ちます。
- VRRPインスタンスのセットは一意のvirtual_router_idを使用する必要があります 他のインスタンス間で共有できない値。そうしないと、偽のパケットが表示され、マスターバックアップスイッチが壊れてしまう可能性があります。
- AWSのようなクラウド環境で実行している場合は、外部スクリプトを使用して(ヒント:「通知」オプションを使用)、仮想IPアドレス(Elastic IP)を分離して関連付ける必要があります。これにより、仮想IPアドレスが認識されてルーティング可能になります。ルーター。
キープアライブの展開
ClusterControlを介してKeepalivedをインストールするには、ClusterControlによってインストールされた、またはClusterControlにインポートされた2つ以上のロードバランサーが必要です。本番環境で使用する場合は、ロードバランサソフトウェアをスタンドアロンホストで実行し、データベースノードと同じ場所に配置しないことを強くお勧めします。
ClusterControlで少なくとも2つのロードバランサーを管理した後、Keepalivedをインストールして仮想IPアドレスを有効にするには、ClusterControl->クラスターを選択->管理->ロードバランサー->キープアライブ:
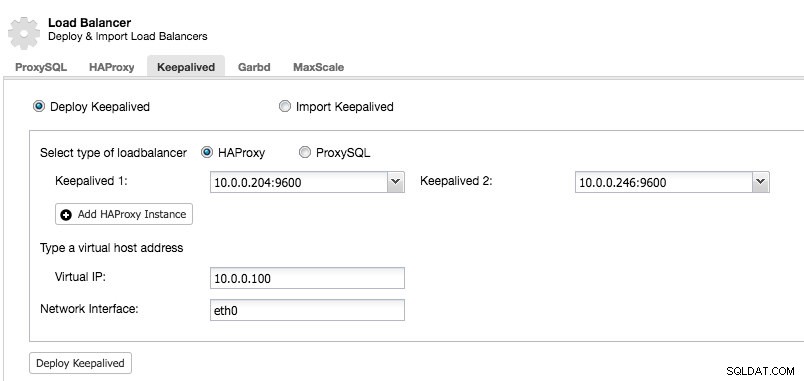
ほとんどのフィールドは自明です。キープアライブの新しいセットをデプロイするか、既存のキープアライブインスタンスをインポートできます。重要なフィールドには、実際の仮想IPアドレスと、仮想IPアドレスが存在するネットワークインターフェイスが含まれます。ホストが2つの異なるインターフェース名を使用している場合は、Keepalived 1ホストのインターフェース名を指定し、後で正しいインターフェース名を使用してKeepalived2の構成ファイルを手動で変更します。
VRRPインスタンス
現在の執筆時点では、ClusterControlv1.5.1はKeepalivedv1.3.5をインストールし(ホストオペレーティングシステムによって異なります)、VRRPインスタンス用に構成されているものは次のとおりです。
vrrp_instance VI_PROXYSQL {
interface eth0 # interface to monitor
state MASTER
virtual_router_id 51 # Assign one ID for this route
priority 100
unicast_src_ip 10.0.0.246
unicast_peer {
10.0.0.204
}
virtual_ipaddress {
10.0.0.100 # the virtual IP
}
track_script {
chk_proxysql
}
# notify /usr/local/bin/notify_keepalived.sh
}ClusterControlは、ユニキャストを介して通信するようにVRRPインスタンスを構成します。ユニキャストでは、他のキープアライブノードのすべてのユニキャストピアを定義する必要があります。それほど動的ではありませんが、ほとんどの場合機能します。マルチキャストを使用すると、これらの回線(unicast_ *)を削除し、ホストの検出とピアリングをマルチキャストIPアドレスに依存できます。シンプルですが、一般的にネットワーク管理者によってブロックされています。
次の部分は仮想IPアドレスです。 VRRPインスタンスごとに、改行で区切って複数の仮想IPアドレスを指定できます。 HAProxy / ProxySQLとKeepalivedで同時に負荷分散を行うには、ローカルではないIPアドレスにバインドする機能も必要です。つまり、ローカルシステム上のデバイスに割り当てられていません。これにより、実行中のロードバランサーインスタンスをフェイルオーバー用にローカルではないIPにバインドできます。したがって、ClusterControlは net.ipv4.ip_nonlocal_bind =1も構成します。 /etc/sysctl.conf内。
次のディレクティブはtrack_script 、次のセクションで説明するヘルスチェックプロセスへのスクリプトを指定できます。
ヘルスチェック
ClusterControlは、track_scriptによって返されるエラーコードを調べることによってヘルスチェックを実行するようにKeepalivedを構成します。デフォルトで/etc/keepalived/keepalived.confにあるKeepalived構成ファイルには、次のようなものが表示されます。
track_script {
chk_proxysql
}以下を含むchk_proxysqlを呼び出す場所:
vrrp_script chk_proxysql {
script "killall -0 proxysql" # verify the pid existence
interval 2 # check every 2 seconds
weight 2 # add 2 points of prio if OK
}ホストで「proxysql」というプロセスが実行されている場合、「killall-0」コマンドは終了コード0を返します。そうしないと、次のセクションで説明するように、インスタンスはそれ自体を降格し、フェイルオーバーの開始を開始する必要があります。 Keepalivedは、ヘルスチェックを実行するためのLinux Virtual Server(LVS)コンポーネントもサポートしていることに注意してください。この場合、HAProxyと同様にTCP / IP接続の負荷分散も可能ですが、このブログ投稿の範囲外です。
フェイルオーバーのシミュレーション
VRRPコンポーネントの場合、KeepalivedはVRRPプロトコル(IPプロトコル112)を使用してVRRPインスタンス間で通信します。 MASTERの優先度の値が高いということは、インスタンスを「nopreempt」で構成しない限り、マスターが仮想IPアドレスを保持するためのより高い特権を常に持つことを意味します。例を使用して、フェイルオーバーとフェイルバックのフローをよりよく説明しましょう。次の図を検討してください。
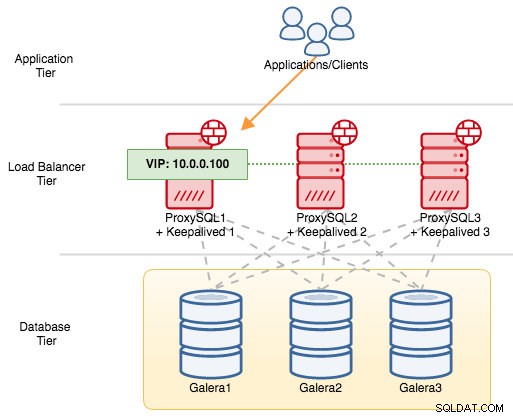
3つのMySQLGaleraノードの前に3つのProxySQLインスタンスがあります。すべてのProxySQLホストは、次の優先順位番号を持つMASTERとしてKeepalivedで構成されています。
- ProxySQL1-優先度101
- ProxySQL2-優先度100
- ProxySQL3-優先度99
KeepalivedがMASTERとして開始されると、最初に優先順位番号をメンバーにアドバタイズし、次にそれ自体を仮想IPアドレスに関連付けます。 BACKUPインスタンスとは対照的に、アドバタイズメントを監視し、マスターに昇格できることを確認した後にのみ仮想IPアドレスを割り当てます。
killコマンドを使用して「proxysql」または「haproxy」プロセスを手動で強制終了した場合、systemdプロセスマネージャーはデフォルトで、正常に停止されていないプロセスの回復を試みることに注意してください。また、ClusterControlの自動回復がオンになっている場合、systemd(systemctl stop proxysql)を介してクリーンシャットダウンを実行しても、ClusterControlは常にプロセスの開始を試みます。障害を最もよくシミュレートするには、ClusterControlの自動回復機能をオフにするか、ProxySQLサーバーをシャットダウンして通信を切断することをお勧めします。
ProxySQL1をシャットダウンすると、仮想IPアドレスは、その特定の時間に優先度の高い次のホスト(ProxySQL2)にフェイルオーバーされます:
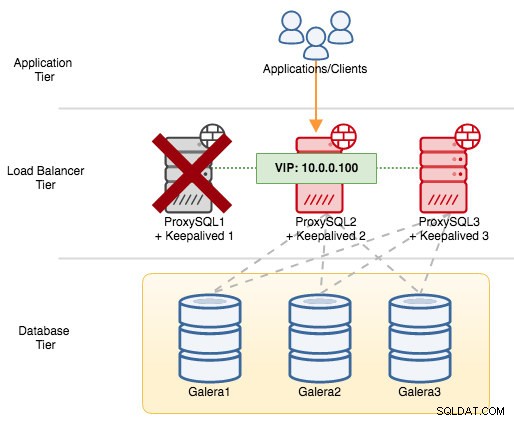
障害が発生したノードのsyslogに次のように表示されます。
Feb 27 05:21:59 proxysql1 systemd: Unit proxysql.service entered failed state.
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: /usr/bin/killall -0 proxysql exited with status 1
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) failed
Feb 27 05:21:59 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 103 to 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 102, ours 101
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:22:00 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.セカンダリノードで、次のことが発生しました:
Feb 27 05:22:00 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:22:01 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 Keepalived_vrrp[7794]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:22:02 proxysql2 avahi-daemon[346]: Registering new address record for 10.0.0.100 on eth0.IPv4.この場合、フェイルオーバーには約3秒かかり、最大フェイルオーバー時間は間隔になります。 + advert_int 。舞台裏では、データベースエンドポイントが変更され、データベーストラフィックはアプリケーションに気付かれることなくProxySQL2を介してルーティングされています。
ProxySQL1がオンラインに戻ると、優先度が高いため、新しいMASTERの選択が強制され、IPアドレスが引き継がれます。
Feb 27 05:38:34 proxysql1 Keepalived_vrrp[12589]: VRRP_Script(chk_proxysql) succeeded
Feb 27 05:38:35 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Changing effective priority from 101 to 103
Feb 27 05:38:36 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) forcing a new MASTER election
Feb 27 05:38:37 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Transition to MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Entering MASTER STATE
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) setting protocol VIPs.
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: Sending gratuitous ARP on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 Keepalived_vrrp[12589]: VRRP_Instance(VI_PROXYSQL) Sending/queueing gratuitous ARPs on eth0 for 10.0.0.100
Feb 27 05:38:38 proxysql1 avahi-daemon[343]: Registering new address record for 10.0.0.100 on eth0.IPv4.同時に、ProxySQL2はそれ自体をバックアップ状態に降格し、ネットワークインターフェイスから仮想IPアドレスを削除します。
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Received advert with higher priority 103, ours 102
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) Entering BACKUP STATE
Feb 27 05:38:36 proxysql2 Keepalived_vrrp[7794]: VRRP_Instance(VI_PROXYSQL) removing protocol VIPs.
Feb 27 05:38:36 proxysql2 avahi-daemon[346]: Withdrawing address record for 10.0.0.100 on eth0.この時点で、ProxySQL1はオンラインに戻り、アプリケーションとクライアントからの接続を提供するアクティブなロードバランサーになります。 VRRPは通常、優先度の高いサーバーがオンラインになると、優先度の低いサーバーをプリエンプトします。 ProxySQL1がオンラインに戻った後もIPアドレスをProxySQL2に残したい場合は、「nopreempt」オプションを使用してください。これにより、優先度の高いマシンがオンラインに戻った場合でも、優先度の低いマシンがマスターの役割を維持できます。ただし、これが機能するには、このエントリの初期状態がBACKUPである必要があります。それ以外の場合は、次の行に気付くでしょう:
Feb 27 05:50:33 proxysql2 Keepalived_vrrp[6298]: (VI_PROXYSQL): Warning - nopreempt will not work with initial state MASTERデフォルトでは、ClusterControlはすべてのノードをMASTERとして構成するため、それぞれのVRRPインスタンスに対して次の構成オプションを適宜構成する必要があります。
vrrp_instance VI_PROXYSQL {
...
state BACKUP
nopreempt
...
}キープアライブプロセスを再起動して、これらの変更をロードします。 ProxySQL2でヘルスチェックが失敗した場合、仮想IPアドレスはProxySQL1またはProxySQL3(優先度とその時点で使用可能なノードに応じて)にのみフェイルオーバーされます。多くの場合、2つのホストでKeepalivedを実行するだけで十分です。