MySQLレプリケーションのコンテキストで「フェイルオーバー」という用語について聞いたことがあるかもしれません。データベースを使って冒険を始めているときに、それが何であるか疑問に思ったかもしれません。たぶんあなたはそれが何であるかを知っていますが、それに関連する潜在的な問題とそれらをどのように解決できるかについて確信がありませんか?
このブログ投稿では、MySQLとMariaDBでのフェイルオーバー処理の概要を説明します。
フェイルオーバーとは何か、それが避けられない理由、フェイルオーバーとスイッチオーバーの違いについて説明します。最も一般的な形式でフェイルオーバープロセスについて説明します。また、フェイルオーバープロセスに関連して対処しなければならないさまざまな問題についても少し触れます。
「フェイルオーバー」とはどういう意味ですか?
MySQLレプリケーションはノードの集合であり、各ノードは一度に1つの役割を果たします。マスターまたはレプリカになることができます。一度にマスターノードは1つだけです。このノードは書き込みトラフィックを受信し、そのレプリカに書き込みを複製します。
ご想像のとおり、レプリケーションクラスターへのデータの単一のエントリポイントであるため、マスターノードは非常に重要です。失敗して利用できなくなったらどうなるでしょうか?
これは、レプリケーションクラスターにとって非常に深刻な状態です。特定の瞬間に書き込みを受け入れることはできません。ご想像のとおり、レプリカの1つがマスターのタスクを引き継ぎ、書き込みの受け入れを開始する必要があります。残りのレプリケーショントポロジも変更する必要がある場合があります。残りのレプリカは、マスターを古い障害のあるノードから新しく選択したノードに変更する必要があります。古いマスターが失敗した後にレプリカをマスターに「昇格」させるこのプロセスは、「フェイルオーバー」と呼ばれます。
一方、「スイッチオーバー」は、ユーザーがレプリカのプロモーションをトリガーしたときに発生します。新しいマスターは、ユーザーが指定したレプリカから昇格し、古いマスターは通常、新しいマスターのレプリカになります。
「フェイルオーバー」と「スイッチオーバー」の最も重要な違いは、古いマスターの状態です。フェイルオーバーが実行されると、何らかの方法で古いマスターに到達できなくなります。クラッシュした可能性があり、ネットワークのパーティション分割が発生した可能性があります。現時点では使用できず、通常、その状態は不明です。
一方、切り替えが行われると、古いマスターは元気に生きています。これは深刻な結果をもたらします。マスターに到達できない場合は、データの一部がまだスレーブに送信されていないことを意味している可能性があります(準同期レプリケーションが使用された場合を除く)。一部のデータが破損しているか、部分的に送信されている可能性があります。
このような破損がスレーブに伝播するのを回避するメカニズムはありますが、重要なのは、処理中に一部のデータが失われる可能性があるということです。一方、スイッチオーバーの実行中は、古いマスターが使用可能であり、データの一貫性が維持されます。
フェイルオーバープロセス
フェイルオーバープロセスがどのように見えるかについて、少し時間をかけて説明しましょう。
マスタークラッシュが検出されました
手始めに、フェイルオーバーが実行される前にマスターがクラッシュする必要があります。使用できなくなると、フェイルオーバーがトリガーされます。これまでのところ、それは単純に見えますが、真実は、私たちはすでに滑りやすい地面にいます。
まず、マスターヘルスはどのようにテストされますか? 1つの場所からテストされますか、それともテストが配布されますか?フェイルオーバー管理ソフトウェアは、マスターへの接続を試みるだけですか、それともマスターの障害が宣言される前に、より高度な検証を実装しますか?
次のトポロジを想像してみましょう:
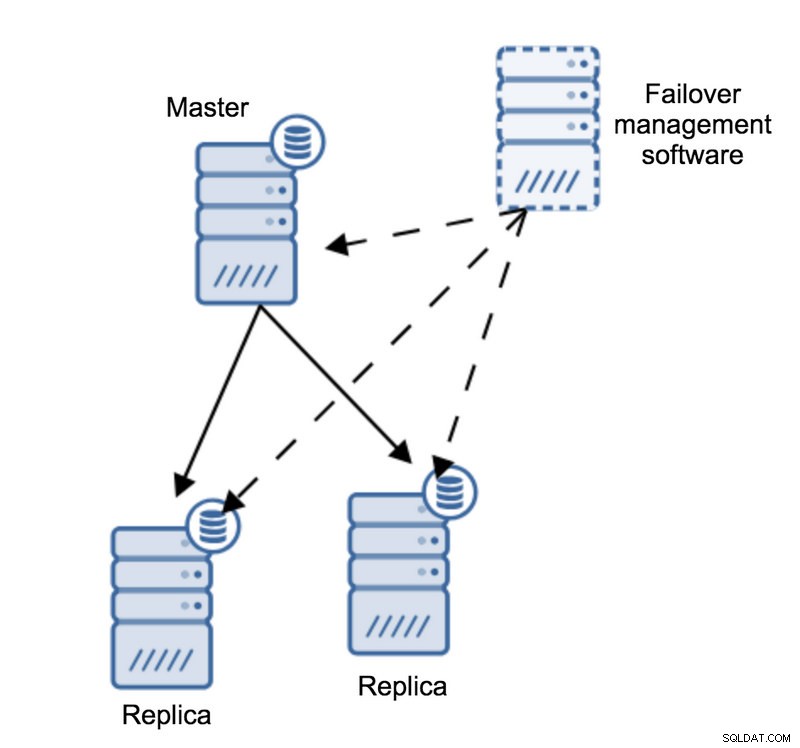
マスターと2つのレプリカがあります。また、外部ホストにフェイルオーバー管理ソフトウェアがあります。フェイルオーバーソフトウェアを備えたホストとマスターの間のネットワーク接続に障害が発生した場合はどうなりますか?
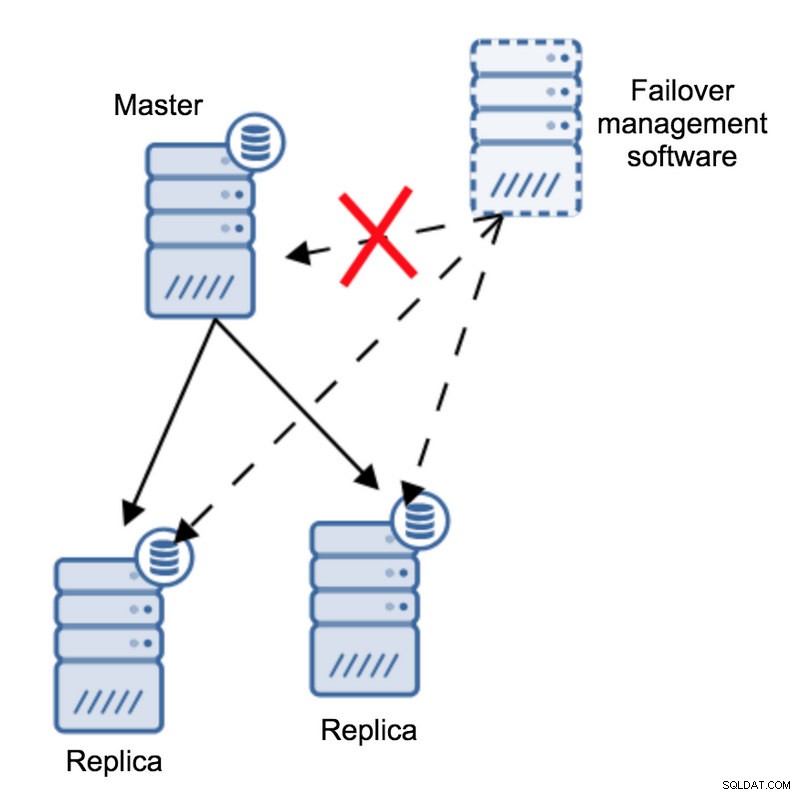
フェイルオーバー管理ソフトウェアによると、マスターがクラッシュしました。マスターへの接続がありません。それでも、レプリケーション自体は正常に機能しています。ここで何が起こるかというと、フェイルオーバー管理ソフトウェアはレプリカに接続して、レプリカの視点を確認しようとします。
彼らは壊れた複製について不平を言っていますか、それとも喜んで複製していますか?
物事はさらに複雑になる可能性があります。プロキシ(またはプロキシのセット)を追加するとどうなりますか?トラフィックのルーティングに使用されます-マスターへの書き込みとレプリカへの読み取り。プロキシがマスターにアクセスできない場合はどうなりますか?どのプロキシもマスターにアクセスできない場合はどうなりますか?
これは、これらの条件下ではアプリケーションが機能できないことを意味します。フェイルオーバー(実際には、マスターが技術的に有効であるため、スイッチオーバーになります)をトリガーする必要がありますか?
技術的には、マスターは有効ですが、アプリケーションで使用することはできません。ここでは、ビジネスロジックを取り入れて、決定を下す必要があります。
オールドマスターの実行の防止
方法と理由に関係なく、レプリカの1つを新しいマスターに昇格させる決定があった場合、古いマスターを停止する必要があり、理想的には、再開できないようにする必要があります。
これをどのように達成できるかは、特定の環境の詳細によって異なります。したがって、フェイルオーバープロセスのこの部分は、通常、さまざまなフックを介してフェイルオーバープロセスに統合された外部スクリプトによって強化されます。
これらのスクリプトは、特定の環境で使用可能なツールを使用して古いマスターを停止するように設計できます。 VMを停止するのはCLIまたはAPI呼び出しの場合があります。ある種の「ライトアウト管理」デバイスを介してコマンドを実行するシェルコードである可能性があります。これは、古いマスターが使用している電源コンセントを無効にするSNMPトラップを配電ユニットに送信するスクリプトである可能性があります(電力がないと、再起動しないことを確認できます)。
フェイルオーバー管理ソフトウェアがより複雑な製品の一部であり、ノードのリカバリも処理する場合(ClusterControlの場合のように)、古いマスターはリカバリルーチンから除外されたものとしてマークされる場合があります。
古いマスターが再び利用可能になるのを防ぐことがなぜそれほど重要なのか疑問に思うかもしれません。
主な問題は、レプリケーションのセットアップでは、書き込みに使用できるノードは1つだけであるということです。通常、すべてのレプリカでread_only(および該当する場合はsuper_read_only)変数を有効にし、マスターでのみ無効にしておくことで、確実になります。
新しいマスターがプロモートされると、read_onlyが無効になります。問題は、古いマスターが使用できない場合、read_only=1に戻すことができないことです。 MySQLまたはホストがクラッシュした場合、my.cnfをその設定で構成することをお勧めするため、これはそれほど問題にはなりません。MySQLが起動すると、常に読み取り専用モードで起動します。
この問題は、クラッシュではなくネットワークの問題である場合に発生します。古いマスターはまだread_onlyを無効にして実行されており、使用できません。ネットワークが収束すると、書き込み可能なノードが2つになります。これは問題である場合とそうでない場合があります。一部のプロキシは、ノードがマスターであるかレプリカであるかを示すインジケーターとしてread_only設定を使用します。特定の時点で2つのマスターが表示されると、データが両方のホストに書き込まれるため、大きな問題が発生する可能性がありますが、レプリカは書き込みトラフィックの半分(新しいマスターにヒットする部分)しか取得しません。
特定のホストにのみ接続するように構成されている一部のスクリプトのハードコードされた設定に関する場合もあります。通常、彼らは失敗し、誰かがマスターが変わったことに気付くでしょう。
古いマスターが利用可能になると、彼らは喜んでそれに接続し、データの不一致が発生します。ご覧のとおり、古いマスターが起動しないようにすることは、非常に優先度の高い項目です。
マスター候補を決定する
古いマスターがダウンしていて、墓から戻ることはありません。今度は、新しいマスターとして使用するホストを決定します。通常、選択するレプリカは複数あるため、決定を下す必要があります。あるレプリカが別のレプリカよりも優先される理由はたくさんあるため、チェックを実行する必要があります。
ホワイトリストとブラックリスト
手始めに、データベースを管理するチームには、マスター候補を決定するときに、あるレプリカを別のレプリカから選択する理由がある場合があります。おそらく、より弱いハードウェアを使用しているか、特定のジョブが割り当てられています(レプリカはバックアップ、分析クエリを実行し、開発者はそれにアクセスしてカスタムの手作りクエリを実行します)。おそらくそれは、アップグレードを進める前に新しいバージョンが受け入れテストを受けているテストレプリカです。ほとんどのフェイルオーバー管理ソフトウェアは、ホワイトリストとブラックリストをサポートしています。これらを利用して、マスター候補として使用する必要があるレプリカと使用できないレプリカを正確に定義できます。
準同期レプリケーション
レプリケーションのセットアップは、非同期レプリカと準同期レプリカを組み合わせたものにすることができます。それらの間には大きな違いがあります。準同期レプリカには、マスターからのすべてのイベントが含まれることが保証されています。非同期レプリカはすべてのデータを受信していない可能性があるため、非同期レプリカにフェイルオーバーするとデータが失われる可能性があります。むしろ、準同期レプリカが昇格されることを望んでいます。
レプリケーションラグ
準同期レプリカにはすべてのイベントが含まれますが、それらのイベントはリレーログにのみ存在する可能性があります。トラフィックが多い場合、半同期か非同期かに関係なく、すべてのレプリカが遅れる可能性があります。
レプリカラグの問題は、レプリカをプロモートするときに、レプリカが古いマスターに接続しようとしないように、レプリカ設定をリセットする必要があることです。これにより、まだ適用されていない場合でも、すべてのリレーログが削除され、データが失われます。
レプリケーション設定をリセットしない場合でも、リレーログのすべてのイベントを適用していない場合は、接続に対して新しいマスターを開くことはできません。そうしないと、新しいクエリがリレーログからのトランザクションに影響を与え、あらゆる種類の問題を引き起こすリスクがあります(たとえば、アプリケーションがリレーログからトランザクションによってアクセスされる一部の行を削除する場合があります)。
これらすべてを考慮に入れると、唯一の安全なオプションは、リレーログが適用されるのを待つことです。それでも、レプリカが大幅に遅れている場合は、しばらく時間がかかることがあります。どのレプリカがより優れたマスターになるかを決定する必要があります。非同期ですが、ラグが小さいか準同期ですが、ラグを適用するにはかなりの時間がかかります。
誤ったトランザクション
レプリカに書き込むべきではありませんが、誰か(または何か)がそれに書き込んだ可能性があります。
これまでは単一のトランザクション方法であった可能性がありますが、それでもフェイルオーバーを実行する機能に深刻な影響を与える可能性があります。この問題は、グローバルトランザクションID(GTID)に厳密に関連しています。これは、特定のMySQLノードで実行されるすべてのトランザクションに個別のIDを割り当てる機能です。
現在、これは非常に人気のあるセットアップです。これは、優れたレベルの柔軟性をもたらし、(マルチスレッドレプリカを使用して)パフォーマンスを向上させることができるためです。
問題は、新しいマスターに再スレーブする際に、GTIDレプリケーションでは、そのマスターからのすべてのイベント(レプリカで実行されていない)をレプリカにレプリケートする必要があることです。
次のシナリオを考えてみましょう。過去のある時点で、レプリカで書き込みが発生しました。かなり前のことであり、このイベントはレプリカのバイナリログから削除されました。ある時点でマスターに障害が発生し、レプリカが新しいマスターとして指定されました。残りのすべてのレプリカは、新しいマスターからスレーブ化されます。彼らは、新しいマスターで実行されたトランザクションについて質問します。古いマスターからのGTIDのリストと、その古い書き込みに関連する単一のGTIDで応答します。古いマスターのGTIDは問題ではありません。残りのすべてのレプリカには、少なくともそれらの大部分(すべてではないにしても)が含まれており、欠落しているすべてのイベントは、新しいマスターのバイナリログで利用できるように十分に新しいものである必要があります。
最悪のシナリオでは、欠落しているイベントの一部がバイナリログから読み取られ、レプリカに転送されます。問題はその古い書き込みにあります-それはまだレプリカであったが、新しいマスターでのみ発生したため、残りのホストには存在しません。これは古いイベントであるため、バイナリログから取得する方法はありません。その結果、どのレプリカも新しいマスターからスレーブ化できなくなります。ここでの唯一の解決策は、手動でアクションを実行し、問題のあるGTIDを含む空のイベントをすべてのレプリカに挿入することです。また、何が起こったかによっては、レプリカが新しいマスターと同期していない可能性があることも意味します。
ご覧のとおり、誤ったトランザクションを追跡し、特定のレプリカを新しいマスターに昇格させることが安全かどうかを判断することは非常に重要です。誤った取引が含まれている場合は、最善の選択肢ではない可能性があります。
アプリケーションのフェイルオーバー処理
マスタースイッチは、強制されているかどうかに関係なく、トポロジ全体に影響を与えることを覚えておくことが重要です。書き込みは新しいノードにリダイレクトする必要があります。これは複数の方法で行うことができ、この変更がアプリケーションに対して可能な限り透過的であることを確認することが重要です。このセクションでは、フェイルオーバーをアプリケーションに対して透過的にする方法の例をいくつか見ていきます。
DNS
アプリケーションをマスターにポイントする方法の1つは、DNSエントリを利用することです。 TTLが低い場合、「master.dc1.example.com」などのDNSエントリが指すIPアドレスを変更できます。このような変更は、フェイルオーバープロセス中に実行される外部スクリプトを介して実行できます。
サービスディスカバリ
領事などのツールを使用して、トラフィックを正しい場所に誘導することもできます。このようなツールには、現在のマスターのIPが何らかの値に設定されているという情報が含まれている場合があります。それらのいくつかは、ホスト名ルックアップを使用して正しいIPを指す機能も提供します。繰り返しになりますが、サービス検出ツールのエントリを維持する必要があります。そのための方法の1つは、フェイルオーバーのさまざまな段階で実行されるフックを使用して、フェイルオーバープロセス中にこれらの変更を行うことです。
プロキシ
プロキシは、トポロジに関する信頼できる情報源としても使用できます。一般的に、トポロジをどのように検出しても(自動プロセスであるか、トポロジが変更されたときにプロキシを再構成する必要があります)、レプリケーションチェーンの現在の状態を含める必要があります。そうしないと、トポロジを検出できません。クエリを正しくルーティングします。
信頼できる情報源としてプロキシを使用するアプローチは、アプリケーションホストにプロキシを併置するアプローチと組み合わせて非常に一般的です。プロキシサーバーとWebサーバーを連携させることには、多くの利点があります。Unixソケットを使用した高速で安全な通信、キャッシングレイヤー(ProxySQLなどの一部のプロキシもキャッシングを実行できるため)をアプリケーションの近くに維持します。このような場合、アプリケーションがプロキシに接続するだけで、クエリが正しくルーティングされると想定するのは理にかなっています。
ClusterControlのフェイルオーバー
ClusterControlは、フェイルオーバープロセスが正しく実行されるように、業界のベストプラクティスを適用します。また、プロセスが安全であることも保証されます。デフォルト設定は、考えられる問題が検出された場合にフェイルオーバーを中止することを目的としています。ユーザーがデータの安全性よりもフェイルオーバーを優先したい場合は、これらの設定を上書きできます。
ClusterControlによってマスター障害が検出されると、フェイルオーバープロセスが開始され、最初のフェイルオーバーフックがすぐに実行されます。

次に、マスターの可用性がテストされます。

ClusterControlは、マスターが実際に使用できないことを確認するために広範なテストを実行します。この動作はデフォルトで有効になっており、次の変数によって管理されます。
replication_check_external_bf_failover
Before attempting a failover, perform extended checks by checking the slave status to detect if the master is truly down, and also check if ProxySQL (if installed) can still see the master. If the master is detected to be functioning, then no failover will be performed. Default is 1 meaning the checks are enabled.次の手順として、ClusterControlは古いマスターがダウンしていることを確認し、そうでない場合は、ClusterControlがマスターを回復しようとしないようにします。

次のステップは、マスター候補として使用できるホストを決定することです。 ClusterControlは、ホワイトリストまたはブラックリストが定義されているかどうかを確認します。
これを行うには、cmon構成ファイルで次の変数を使用します。
replication_failover_blacklist
Comma separated list of hostname:port pairs. Blacklisted servers will not be considered as a candidate during failover. replication_failover_blacklist is ignored if replication_failover_whitelist is set.replication_failover_whitelist
Comma separated list of hostname:port pairs. Only whitelisted servers will be considered as a candidate during failover. If no server on the whitelist is available (up/connected) the failover will fail. replication_failover_blacklist is ignored if replication_failover_whitelist is set.すべてのレプリカでバイナリログフィルターの違いを探すようにClusterControlを構成することもできます。これは、replication_check_binlog_vinyl_bf_failover変数を使用して実行できます。デフォルトでは、これらのチェックは無効になっています。 ClusterControlは、問題を引き起こす可能性のある誤ったトランザクションがないことも確認します。

cmon構成ファイルの次の設定を使用して、新しいマスターから複製できないレプリカを自動再構築するようにClusterControlに依頼することもできます。
* replication_auto_rebuild_slave:
If the SQL THREAD is stopped and error code is non-zero then the slave will be automatically rebuilt. 1 means enable, 0 means disable (default).
その後、2番目のスクリプトが実行されます。これはreplication_pre_failover_script設定で定義されます。次に、候補者は準備プロセスを経ます。


ClusterControlは、REDOログが適用されるのを待ちます(データ損失が最小限になるようにします)。また、マスター候補に適用されていない残りのレプリカで使用可能な他のトランザクションがあるかどうかもチェックします。両方の動作は、cmon構成ファイルの次の設定を使用してユーザーが制御できます。
replication_skip_apply_missing_txs
Force failover/switchover by skipping applying transactions from other slaves. Default disabled. 1 means enabled.replication_failover_wait_to_apply_timeout
Candidate waits up to this many seconds to apply outstanding relay log (retrieved_gtids) before failing over. Default -1 seconds (wait forever). 0 means failover immediately.ご覧のとおり、すべてのREDOログイベントが適用されていなくても、強制的にフェイルオーバーを実行できます。これにより、ユーザーは、データの整合性またはフェイルオーバーの速度など、優先度の高いものを決定できます。


最後に、マスターが選出され、最後のスクリプトが実行されます(replication_post_failover_scriptとして定義できるスクリプト。
ClusterControlをまだ試していない場合は、ダウンロードして(無料で)試してみることをお勧めします。
ClusterControlでのマスター検出
ClusterControlを使用すると、データベース層とプロキシ層を含む完全な高可用性スタックを展開できます。マスターディスカバリーは常に対処すべき問題の1つです。
ClusterControlではどのように機能しますか?
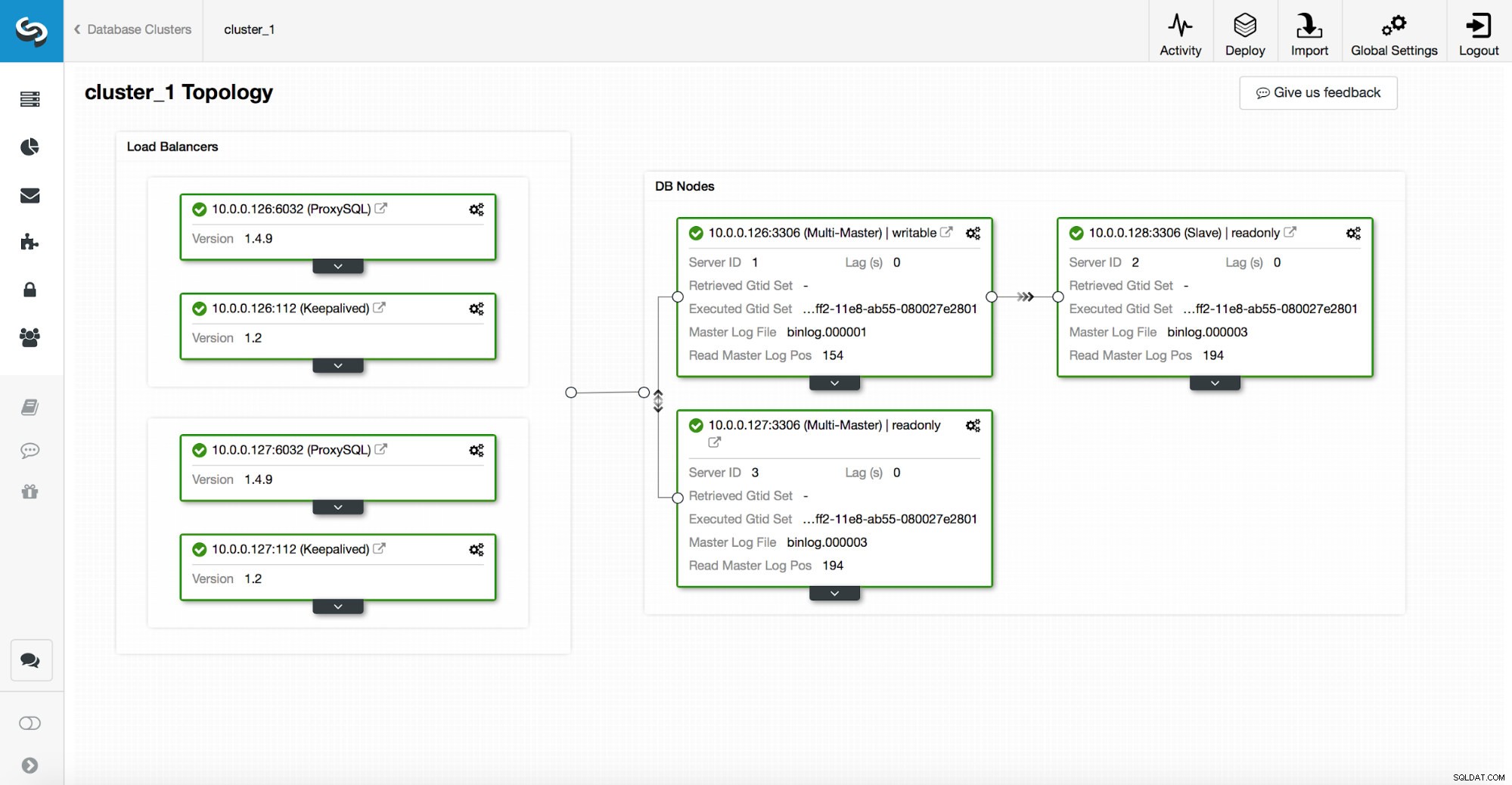
ClusterControlを介してデプロイされる高可用性スタックは、次の3つの部分で構成されます。
- データベースレイヤー
- HAProxyまたはProxySQLのプロキシレイヤー
- keepalivedレイヤー。仮想IPを使用して、プロキシレイヤーの高可用性を保証します
プロキシはノードのread_only変数に依存しています。
上のスクリーンショットでわかるように、トポロジ内の1つのノードのみが「書き込み可能」としてマークされています。これはマスターであり、書き込みを受信する唯一のノードです。
プロキシ(この例ではProxySQL)はこの変数を監視し、自動的に再構成します。
その方程式の反対側では、ClusterControlがトポロジーの変更(フェイルオーバーとスイッチオーバー)を処理します。変更後のトポロジの状態を反映するために、read_only値に必要な変更を加えます。新しいマスターがプロモートされると、それが唯一の書き込み可能なノードになります。フェイルオーバー後にマスターが選出されると、read_onlyが無効になります。
プロキシ層の上に、keepalivedがデプロイされます。 VIPを展開し、基盤となるプロキシノードの状態を監視します。 VIPは、一度に1つのプロキシノードを指します。このノードがダウンすると、仮想IPは別のノードにリダイレクトされ、VIPに向けられたトラフィックが正常なプロキシノードに確実に到達するようになります。
要約すると、アプリケーションは仮想IPアドレスを使用してデータベースに接続します。このIPは、プロキシの1つを指します。プロキシは、トポロジ構造に応じてトラフィックをリダイレクトします。トポロジーに関する情報は、read_only状態から取得されます。この変数はClusterControlによって管理され、ユーザーが要求したトポロジの変更またはClusterControlが自動的に実行したことに基づいて設定されます。