SCUMM(Severalnines ClusterControl Unified Management and Monitoring)をリリースしてから約2か月です。 SCUMMは、データベースインスタンスとロードバランサーで実行されているエクスポーターから時系列データを収集するための基盤となる方法としてPrometheusを利用します。このブログでは、Prometheusエクスポーターが実行されていない場合、グラフにデータが表示されていない場合、または「データポイントがありません」と表示されている場合の問題を修正する方法を紹介します。
プロメテウスとは何ですか?
Prometheusは、次元データモデル、柔軟なクエリ言語、効率的な時系列データベース、および最新のアラートアプローチを備えたオープンソースの監視システムです。これは、監視対象のターゲットでメトリックHTTPエンドポイントをスクレイピングすることにより、監視対象のターゲットからメトリックを収集する監視プラットフォームです。ディメンションデータ、強力なクエリ、優れた視覚化、効率的なストレージ、シンプルな操作、正確なアラート、多くのクライアントライブラリ、および多くの統合を提供します。
SCUMMダッシュボードで動作中のPrometheus
Prometheusは、各エクスポーターがデータベースまたはロードバランサーホストで実行されている状態で、エクスポーターからメトリックデータを収集します。次の図は、これらのエクスポーターがPrometheusプロセスをホストしているサーバーとどのようにリンクされているかを示しています。 ClusterControlノードでPrometheusが実行されており、process_exporterとnode_exporterも実行されていることを示しています。
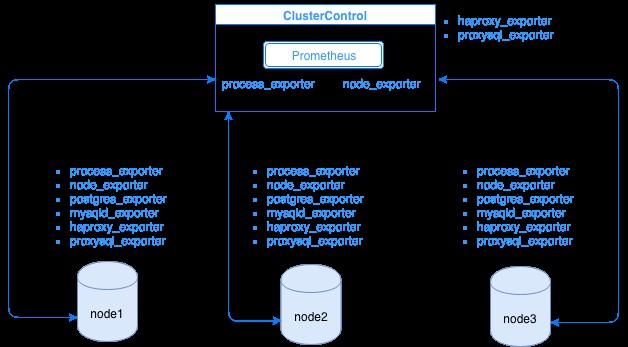
この図は、PrometheusがClusterControlホストとエクスポーター process_exporterで実行されていることを示しています。 およびnode_exporter 独自のノードからメトリックを収集するためにも実行されています。オプションで、ClusterControlホストをターゲットとして作成し、HAProxyまたはProxySQLをセットアップすることもできます。
上記のクラスターノード(node1、node2、およびnode3)の場合、mysqld_exporterまたはpostgres_exporterを実行できます。これらのエージェントは、そのノードの内部でデータを取得し、Prometheusサーバーに渡して独自のデータストレージに保存します。その物理データは、Prometheusがセットアップされているホスト内の/ var / lib / prometheus/dataを介して見つけることができます。
たとえば、ClusterControlホストでPrometheusをセットアップする場合、次のポートが開いている必要があります。以下を参照してください:
[example@sqldat.com share]# netstat -tnvlp46|egrep 'ex[p]|prometheu[s]'
tcp6 0 0 :::9100 :::* LISTEN 16189/node_exporter
tcp6 0 0 :::9011 :::* LISTEN 19318/process_expor
tcp6 0 0 :::42004 :::* LISTEN 16080/proxysql_expo
tcp6 0 0 :::9090 :::* LISTEN 31856/prometheus出力に基づいて、ClusterControlがホストされているホストtestccnodeでもProxySQLを実行しています。
Prometheusを使用したSCUMMダッシュボードに関する一般的な問題
ダッシュボードが有効になっている場合、ClusterControlは、node_exporter、process_exporter、mysqld_exporter、postgres_exporter、daemonなどのバイナリとエクスポーターをインストールしてデプロイします。これらは、データベースノードに共通のパッケージセットです。これらをセットアップしてインストールすると、次のデーモンコマンドが起動され、次のように実行されます。
[example@sqldat.com bin]# ps axufww|egrep 'exporte[r]'
prometh+ 3604 0.0 0.0 10828 364 ? S Nov28 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 3605 0.2 0.3 256300 14924 ? Sl Nov28 4:06 \_ process_exporter
prometh+ 3838 0.0 0.0 10828 564 ? S Nov28 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 3839 0.0 0.4 44636 15568 ? Sl Nov28 1:08 \_ node_exporter
prometh+ 4038 0.0 0.0 10828 568 ? S Nov28 0:00 daemon --name=mysqld_exporter --output=/var/log/prometheus/mysqld_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/mysqld_exporter.pid --user=prometheus -- mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_status
prometh+ 4039 0.1 0.2 17368 11544 ? Sl Nov28 1:47 \_ mysqld_exporter --collect.perf_schema.eventswaits --collect.perf_schema.file_events --collect.perf_schema.file_instances --collect.perf_schema.indexiowaits --collect.perf_schema.tableiowaits --collect.perf_schema.tablelocks --collect.info_schema.tablestats --collect.info_schema.processlist --collect.binlog_size --collect.global_status --collect.global_variables --collect.info_schema.innodb_metrics --collect.slave_statusPostgreSQLノードの場合
[example@sqldat.com vagrant]# ps axufww|egrep 'ex[p]'
postgres 1901 0.0 0.4 1169024 8904 ? Ss 18:00 0:04 \_ postgres: postgres_exporter postgres ::1(51118) idle
prometh+ 1516 0.0 0.0 10828 360 ? S 18:00 0:00 daemon --name=process_exporter --output=/var/log/prometheus/process_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/process_exporter.pid --user=prometheus -- process_exporter
prometh+ 1517 0.2 0.7 117032 14636 ? Sl 18:00 0:35 \_ process_exporter
prometh+ 1700 0.0 0.0 10828 572 ? S 18:00 0:00 daemon --name=node_exporter --output=/var/log/prometheus/node_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/node_exporter.pid --user=prometheus -- node_exporter
prometh+ 1701 0.0 0.7 44380 14932 ? Sl 18:00 0:10 \_ node_exporter
prometh+ 1897 0.0 0.0 10828 568 ? S 18:00 0:00 daemon --name=postgres_exporter --output=/var/log/prometheus/postgres_exporter.log --env=HOME=/var/lib/prometheus --env=PATH=/usr/local/bin:/usr/bin:/sbin:/bin:/usr/sbin:/usr/bin --env=DATA_SOURCE_NAME=postgresql://postgres_exporter:example@sqldat.com:5432/postgres?sslmode=disable --chdir=/var/lib/prometheus --pidfile=/var/run/prometheus/postgres_exporter.pid --user=prometheus -- postgres_exporter
prometh+ 1898 0.0 0.5 16548 11204 ? Sl 18:00 0:06 \_ postgres_exporterMySQLノードと同じエクスポーターがありますが、これはPostgreSQLデータベースノードであるため、postgres_exporterのみが異なります。
ただし、ノードで停電、システムクラッシュ、またはシステムの再起動が発生すると、これらのエクスポーターは実行を停止します。 Prometheusは、エクスポーターがダウンしていることを報告します。 ClusterControlはPrometheus自体をサンプリングし、エクスポーターのステータスを要求します。したがって、この情報に基づいて動作し、ダウンしている場合はエクスポーターを再起動します。
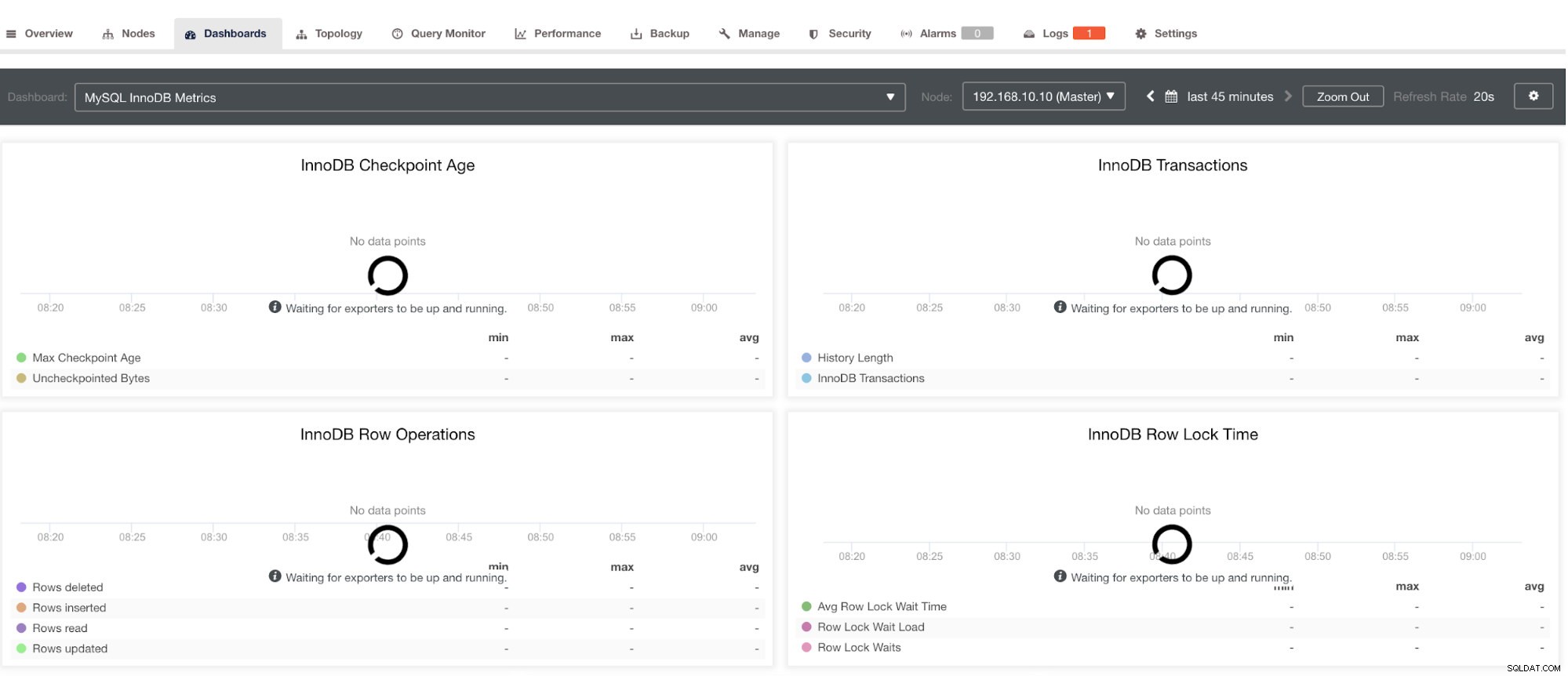
ただし、ClusterControlを介してインストールされていないエクスポーターの場合、クラッシュ後に再起動されることはないことに注意してください。その理由は、クラッシュまたは異常なシャットダウン時にプロセスを再起動する安全スクリプトとして機能するsystemdまたはデーモンによって監視されていないためです。したがって、以下のスクリーンショットは、エクスポーターが実行されていないときの様子を示しています。以下を参照してください:
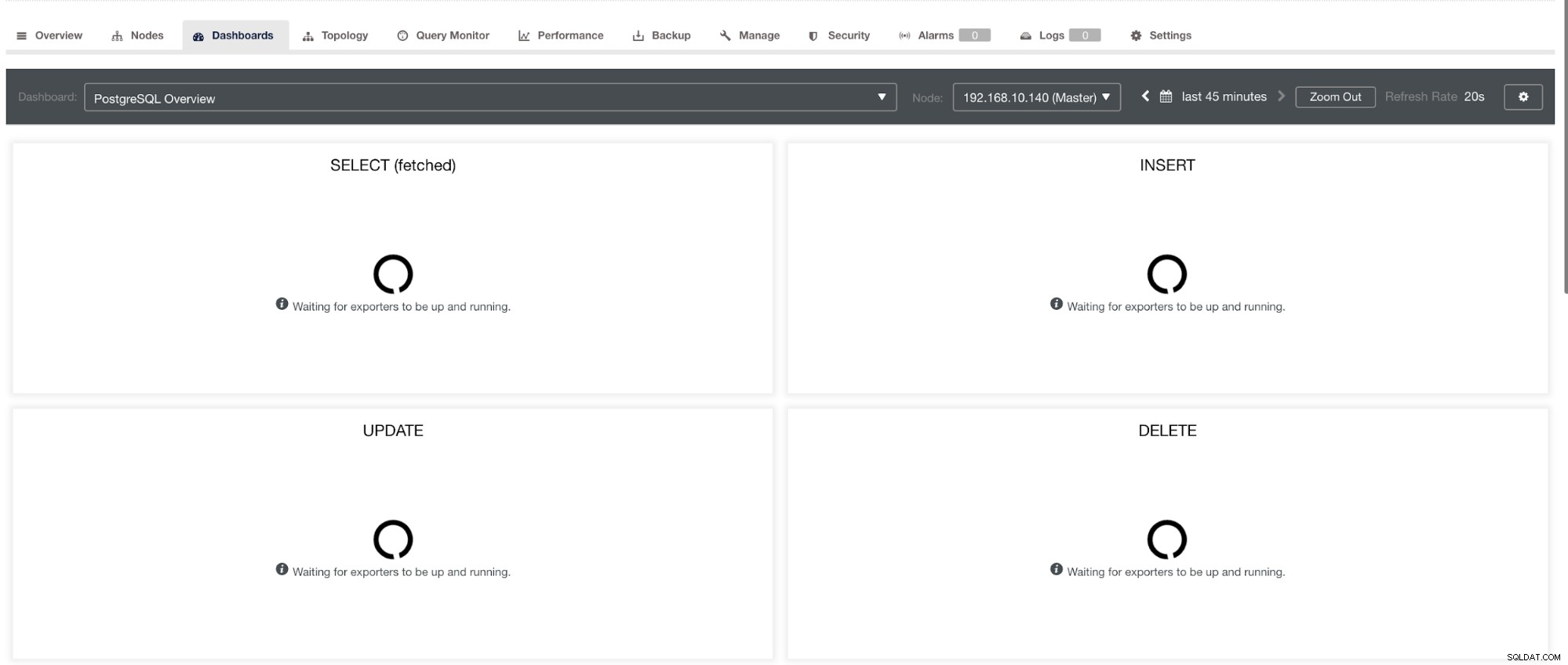
PostgreSQLダッシュボードでは、グラフに「データポイントなし」というラベルが付いた同じ読み込みアイコンが表示されます。以下を参照してください:
したがって、これらは、次のセクションで説明するさまざまな手法でトラブルシューティングできます。
Prometheusの問題のトラブルシューティング
エクスポーターと呼ばれるプロメテウスエージェントは、次のポートを使用しています:9100(node_exporter)、9011(process_exporter)、9187(postgres_exporter)、9104(mysqld_exporter)、42004(proxysql_exporter)、およびプロメテウスが所有する独自の9090処理する。これらは、ClusterControlによって使用されるこれらのエージェントのポートです。
SCUMMダッシュボードの問題のトラブルシューティングを開始するには、データベースノードから開いているポートを確認することから始めます。以下のリストに従うことができます:
-
ポートが開いているかどうかを確認します
例:
## Use netstat and check the ports [example@sqldat.com vagrant]# netstat -tnvlp46|egrep 'ex[p]' tcp6 0 0 :::9100 :::* LISTEN 5036/node_exporter tcp6 0 0 :::9011 :::* LISTEN 4852/process_export tcp6 0 0 :::9187 :::* LISTEN 5230/postgres_exporファイアウォール(iptablesやfirewalldなど)がポートを開くのをブロックしているか、プロセスデーモン自体が実行されていないために、ポートが開いていない可能性があります。
-
ホストモニターからcurlを使用して、ポートが到達可能で開いているかどうかを確認します。
例:
## Using curl and grep mysql list of available metric names used in PromQL. [example@sqldat.com prometheus]# curl -sv mariadb_g01:9104/metrics|grep 'mysql'|head -25 * About to connect() to mariadb_g01 port 9104 (#0) * Trying 192.168.10.10... * Connected to mariadb_g01 (192.168.10.10) port 9104 (#0) > GET /metrics HTTP/1.1 > User-Agent: curl/7.29.0 > Host: mariadb_g01:9104 > Accept: */* > < HTTP/1.1 200 OK < Content-Length: 213633 < Content-Type: text/plain; version=0.0.4; charset=utf-8 < Date: Sat, 01 Dec 2018 04:23:21 GMT < { [data not shown] # HELP mysql_binlog_file_number The last binlog file number. # TYPE mysql_binlog_file_number gauge mysql_binlog_file_number 114 # HELP mysql_binlog_files Number of registered binlog files. # TYPE mysql_binlog_files gauge mysql_binlog_files 26 # HELP mysql_binlog_size_bytes Combined size of all registered binlog files. # TYPE mysql_binlog_size_bytes gauge mysql_binlog_size_bytes 8.233181e+06 # HELP mysql_exporter_collector_duration_seconds Collector time duration. # TYPE mysql_exporter_collector_duration_seconds gauge mysql_exporter_collector_duration_seconds{collector="collect.binlog_size"} 0.008825006 mysql_exporter_collector_duration_seconds{collector="collect.global_status"} 0.006489491 mysql_exporter_collector_duration_seconds{collector="collect.global_variables"} 0.00324821 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.innodb_metrics"} 0.008209824 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.processlist"} 0.007524068 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tables"} 0.010236411 mysql_exporter_collector_duration_seconds{collector="collect.info_schema.tablestats"} 0.000610684 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.eventswaits"} 0.009132491 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_events"} 0.009235416 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.file_instances"} 0.009451361 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.indexiowaits"} 0.009568397 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tableiowaits"} 0.008418406 mysql_exporter_collector_duration_seconds{collector="collect.perf_schema.tablelocks"} 0.008656682 mysql_exporter_collector_duration_seconds{collector="collect.slave_status"} 0.009924652 * Failed writing body (96 != 14480) * Closing connection 0理想的には、ターミナルから簡単にgrepとデバッグができるため、このアプローチが実際に実行可能であることがわかりました。
-
Web UIを使用してみませんか?
-
Prometheusは、SCUMMダッシュボードのClusterControlで使用されるポート9090を公開します。これとは別に、エクスポーターが公開しているポートを使用して、PromQLを使用して使用可能なメトリック名のトラブルシューティングと決定を行うこともできます。 Prometheusが実行されているサーバーで、 http://
:9090 /targets にアクセスできます。 。以下のスクリーンショットは、実際の動作を示しています。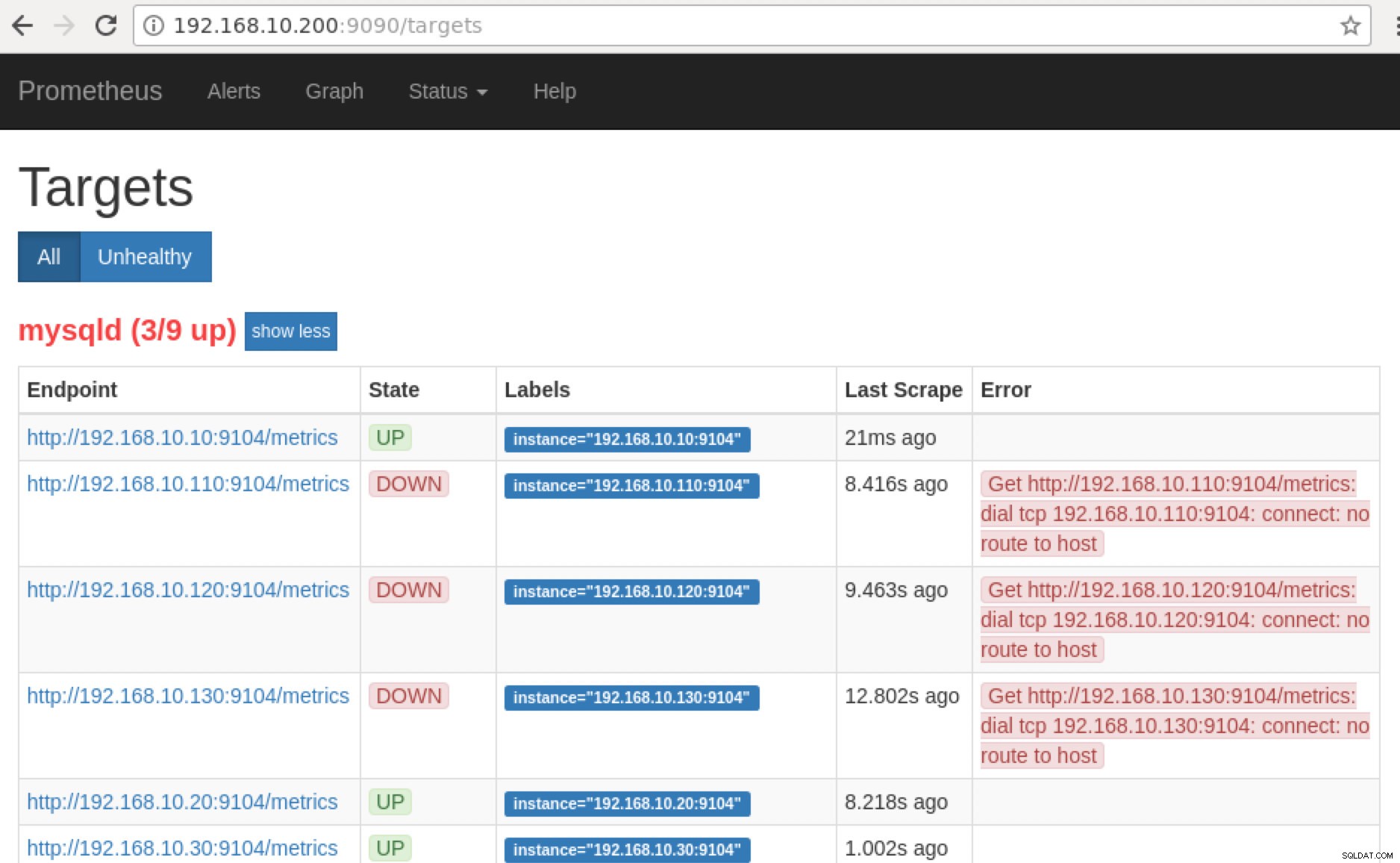
[エンドポイント]をクリックすると、下のスクリーンショットと同様にメトリックを確認できます。
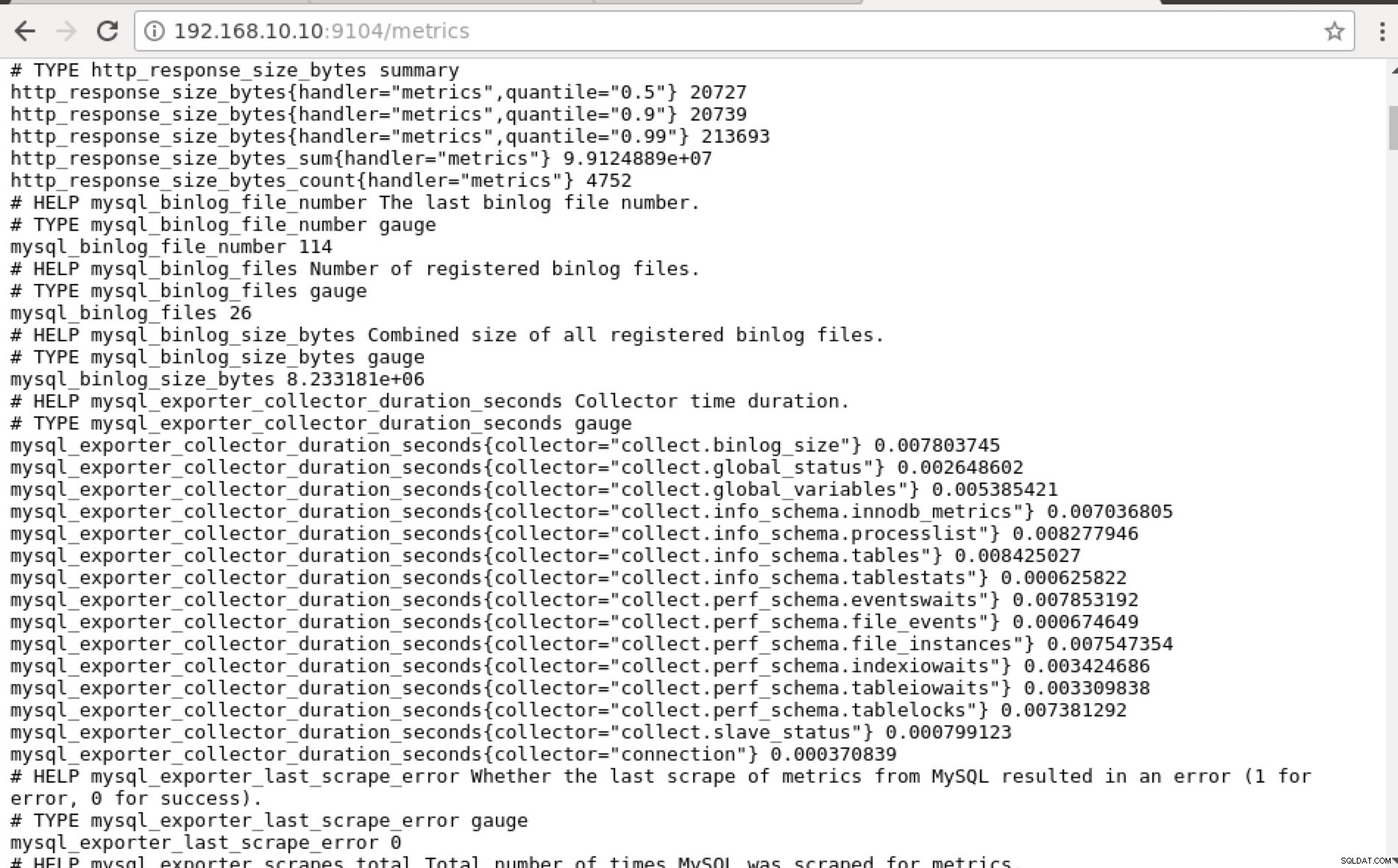
IPアドレスを使用する代わりに、Web UIインターフェイスまたはcURLを使用してhttp:// localhost:9104 /metricsにアクセスするなど、特定のノードのlocalhostを介してローカルでこれを確認することもできます。
ここで、「ターゲット」に戻ると 」ページでは、ポートに問題がある可能性のあるノードのリストを確認できます。これを引き起こす可能性のある理由を以下に示します:
- サーバーがダウンしています
- ファイアウォールが実行されているため、ネットワークに到達できないか、ポートが開かれていません
-
_exporter の場所でデーモンが実行されていません 実行されていません。たとえば、mysqld_exporterは実行されていません。
-
これらのエクスポーターが実行されている場合、デーモンを使用してプロセスを起動して実行できます。 指図。上記の例で使用した、またはこのブログの前のセクションで言及した、使用可能な実行中のプロセスを参照できます。
ダッシュボードにある「データポイントなし」のグラフはどうですか?
SCUMMダッシュボードは、MySQLで一般的に使用される一般的なユースケースシナリオを考え出します。ただし、そのようなメトリックを呼び出すと、特定のMySQLバージョンまたはMariaDBやPerconaServerなどのMySQLベンダーで使用できない場合がある変数がいくつかあります。
以下に例を示します:
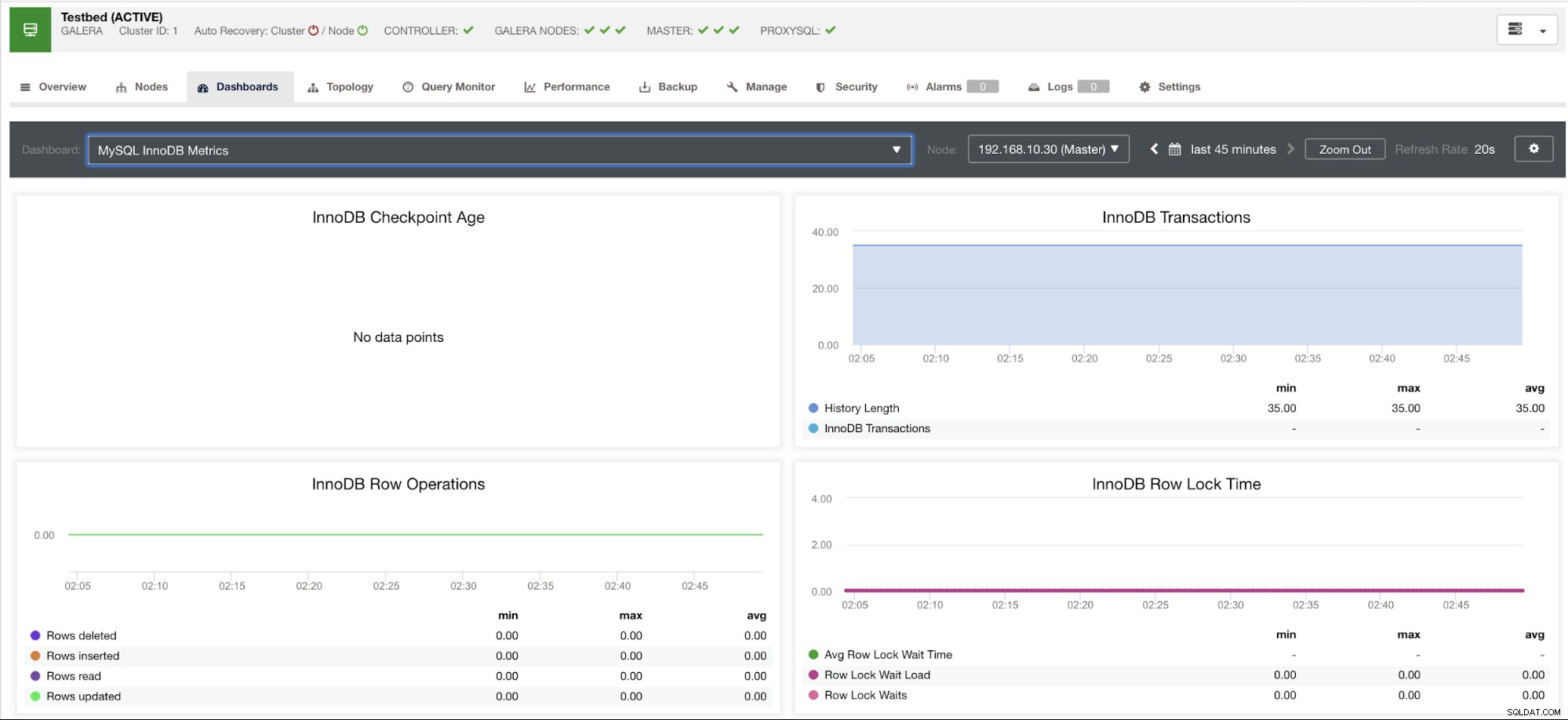
このグラフは、バージョン10.3.9-MariaDBで実行されているデータベースサーバーで取得されました-wsrep_25.23インスタンスのwsrep_patch_versionを持つMariaDBサーバーをログに記録します。問題は、なぜデータポイントが読み込まれないのかということです。ノードにチェックポイントの経過時間ステータスを問い合わせると、ノードが空であるか、変数が見つからないことがわかります。以下を参照してください:
MariaDB [(none)]> show global status like 'Innodb_checkpoint_max_age';
Empty set (0.000 sec)MariaDBにこの変数がない理由がわかりません(答えがあれば、このブログのコメントセクションでお知らせください)。これは、変数Innodb_checkpoint_max_ageが存在するPerconaXtraDBクラスターサーバーとは対照的です。以下を参照してください:
mysql> show global status like 'Innodb_checkpoint_max_age';
+---------------------------+-----------+
| Variable_name | Value |
+---------------------------+-----------+
| Innodb_checkpoint_max_age | 865244898 |
+---------------------------+-----------+
1 row in set (0.00 sec)ただし、これが意味するのは、Prometheusクエリが実行されたときに特定のメトリックで収集されたデータがないため、データポイントが収集されていないグラフが存在する可能性があるということです。
ただし、データポイントがないグラフは、MySQLの現在のバージョンまたはそのバリアントがデータポイントをサポートしていないことを意味するものではありません。たとえば、適切に設定または有効にする必要がある特定の変数を必要とする特定のグラフがあります。
次のセクションでは、これらのグラフが何であるかを示します。
インデックス条件プッシュダウン(ICP)グラフ

このグラフは私の以前のブログで言及されています。これは、innodb_monitor_enableという名前のMySQLグローバル変数に依存しています。この変数は動的であるため、MySQLデータベースをハードリスタートせずにこれを設定できます。また、innodb_monitor_enable =module_icpが必要です。または、このグローバル変数をinnodb_monitor_enable=allに設定できます。通常、このような場合や、このようなグラフにデータポイントが表示されない理由に関する混乱を避けるために、注意して使用する必要がある場合があります。この変数をオンにしてすべてに設定すると、一定のオーバーヘッドが発生する可能性があります。
MySQLパフォーマンススキーマグラフ
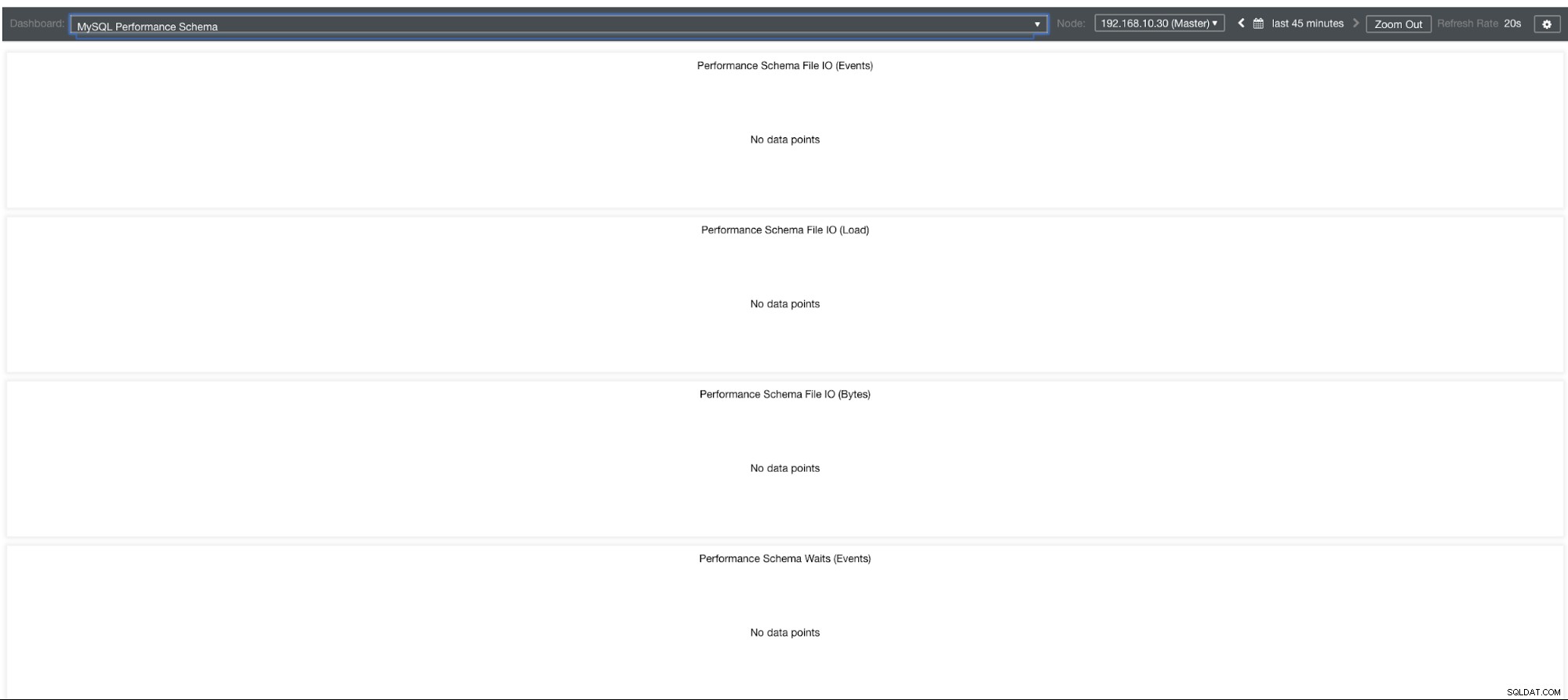
では、なぜこれらのグラフは「データポイントなし」を示しているのでしょうか。テンプレートを使用してClusterControlを使用してクラスターを作成すると、デフォルトでperformance_schema変数が定義されます。たとえば、以下の変数が設定されています:
performance_schema = ON
performance-schema-max-mutex-classes = 0
performance-schema-max-mutex-instances = 0ただし、performance_schema =OFFの場合、関連するグラフに「データポイントなし」と表示されるのはそのためです。
しかし、performance_schemaを有効にしているのに、なぜ他のグラフがまだ問題なのですか?
さて、複数の変数を設定する必要があるグラフがまだあります。これは以前のブログですでに取り上げられています。したがって、innodb_monitor_enable=allおよびuserstat=1を設定する必要があります。結果は次のようになります:
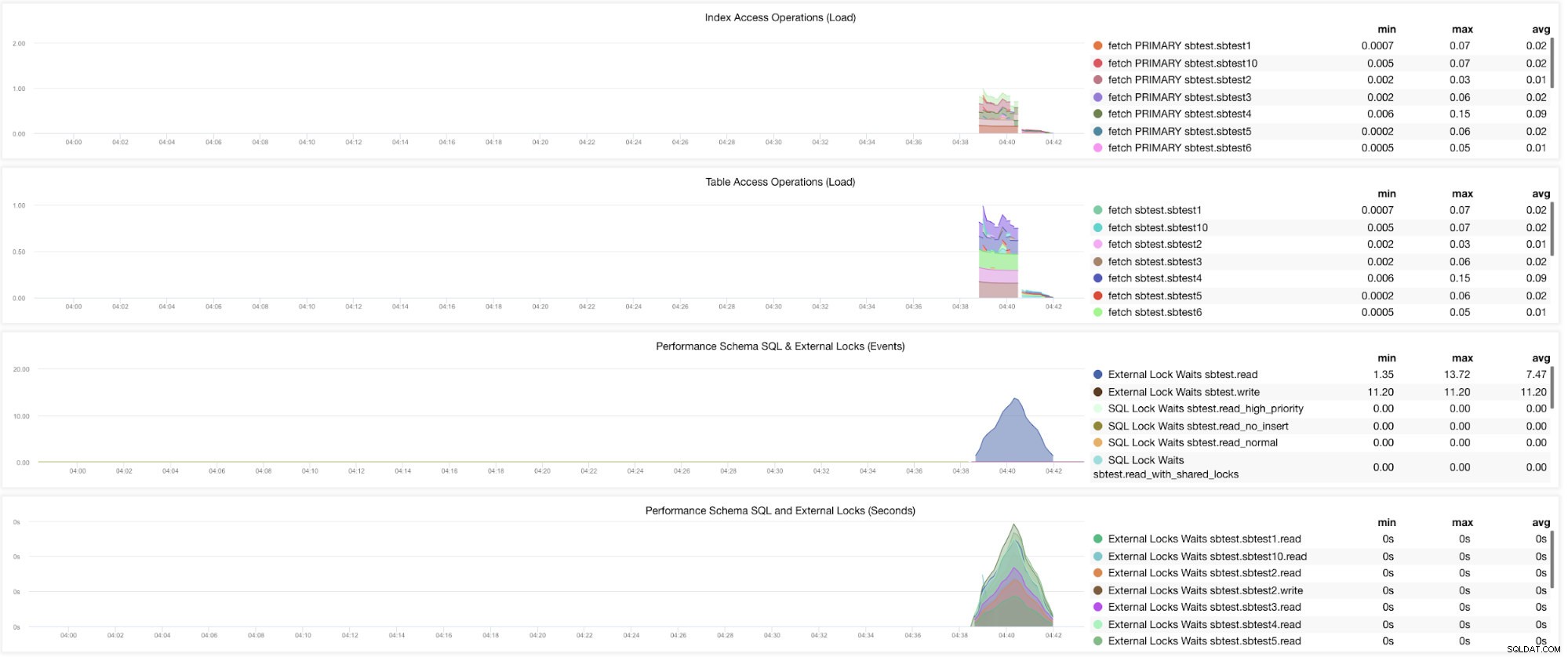
ただし、MariaDB 10.3のバージョン(特に10.3.11)では、performance_schema =ONを設定すると、MySQLパフォーマンススキーマダッシュボードに必要なメトリックが設定されます。これは、データベースサーバーに余分なオーバーヘッドを追加するinnodb_monitor_enable =ONを設定する必要がないため、大きな利点です。
高度なトラブルシューティング
おすすめできる事前のトラブルシューティングはありますか?はいあります!ただし、少なくともJavaScriptのスキルは必要です。 Prometheusを使用するSCUMMダッシュボードはハイチャートに依存しているため、PromQLリクエストに使用されているメトリックは、以下に示すapp.jsスクリプトを介して決定できます。
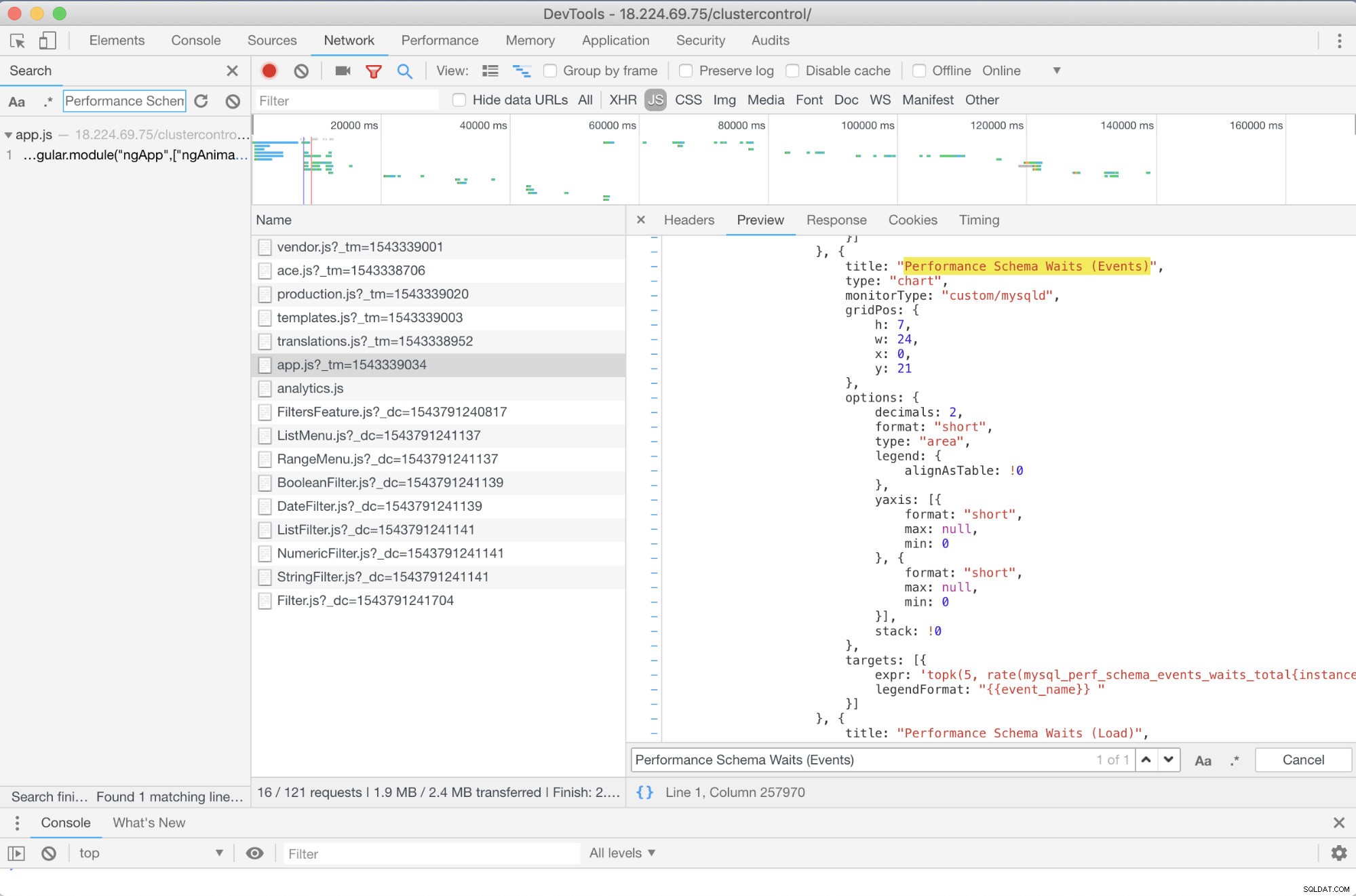
したがって、この場合、私はGoogle ChromeのDevToolsを使用して、パフォーマンススキーマ待機(イベント)を探しようとしました。 。これはどのように役立ちますか?ターゲットを見ると、次のように表示されます。
targets: [{
expr: 'topk(5, rate(mysql_perf_schema_events_waits_total{instance="$instance"}[$interval])>0) or topk(5, irate(mysql_perf_schema_events_waits_total{instance="$instance"}[5m])>0)',
legendFormat: "{{event_name}} "
}]
これで、mysql_perf_schema_events_waits_totalである要求されたメトリックを使用できます。たとえば、http://
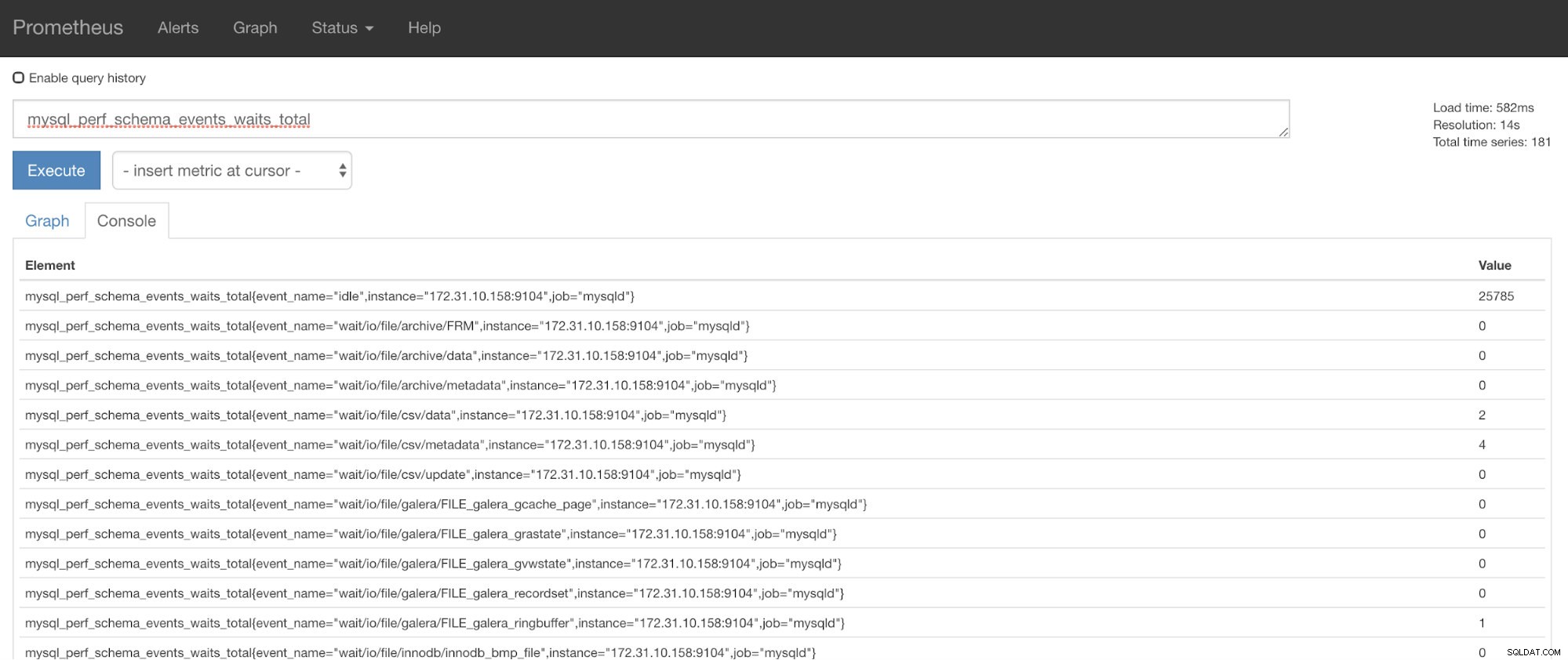
ClusterControl Auto-Recovery to therescue!
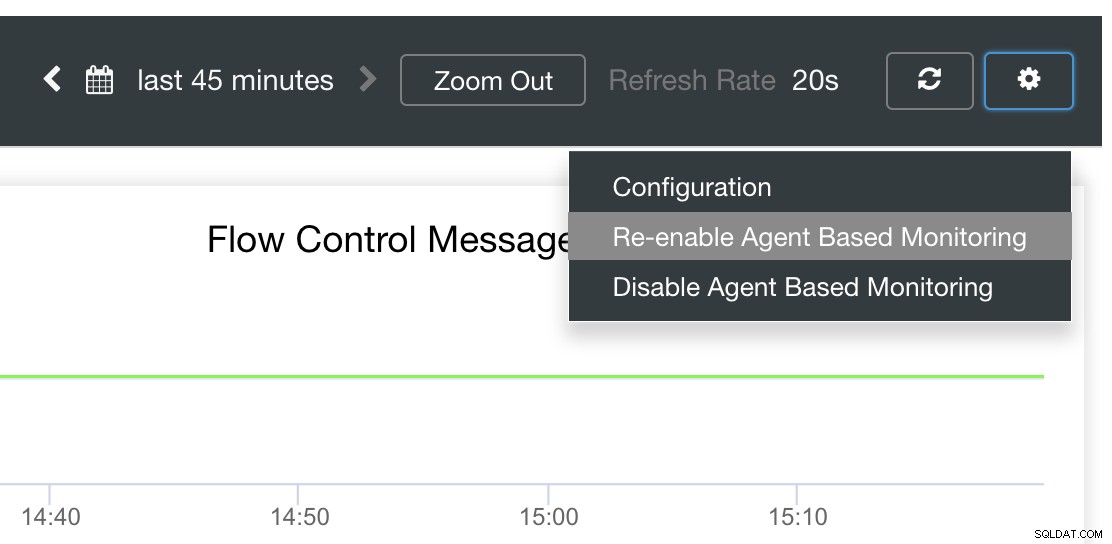
最後に、主な質問は、失敗したエクスポーターを再起動する簡単な方法はありますか?はい! ClusterControlはエクスポートの状態を監視し、必要に応じてそれらを再起動することを前述しました。 SCUMMダッシュボードがグラフを正常にロードしないことに気付いた場合は、自動回復が有効になっていることを確認してください。下の画像を参照してください:

これを有効にすると、
エクスポータを再インストールまたは再構成することもできます。
結論
このブログでは、ClusterControlがPrometheusを使用してSCUMMダッシュボードを提供する方法を説明しました。高解像度の監視データや豊富なグラフから、強力な機能セットを提供します。 PromQLを使用すると、時系列データをリアルタイムで集計できるSCUMMダッシュボードを特定してトラブルシューティングできることを学びました。収集されたすべてのメトリックについて、グラフを生成したり、コンソールから表示したりすることもできます。
また、特にデータポイントが収集されていない場合に、SCUMMダッシュボードをデバッグする方法も学びました。
ご不明な点がございましたら、コメントを追加するか、コミュニティフォーラムからお知らせください。