Galeraクラスターを使用することは、MySQLまたはMariaDBの高可用性環境を構築するための優れた方法です。これは、12〜15ノードを超えて拡張できるシェアードナッシングクラスター環境です。ただし、Galeraにはいくつかの制限があります。低遅延環境で優れており、WAN全体で使用できますが、パフォーマンスはネットワーク遅延によって制限されます。ノードの1つが正しく動作し始めた場合も、Galeraのパフォーマンスに影響を与える可能性があります。たとえば、ノードの1つに過度の負荷がかかると、速度が低下し、書き込みの処理が遅くなり、クラスター内の他のすべてのノードに影響を与える可能性があります。一方、データを分析せずに事業を営むことは不可能です。このような分析では、通常、OLTPワークロードとはまったく異なる重いクエリを実行する必要があります。このブログ投稿では、Galera Cluster for MySQLまたはMariaDBに保存されているデータに対して、コアクラスターのパフォーマンスに影響を与えない方法で分析クエリを実行する簡単な方法について説明します。
Galera Clusterで分析クエリを実行するにはどうすればよいですか?
すでに述べたように、Galeraクラスターで長時間実行されるクエリを直接実行することは可能ですが、おそらくあまり良い考えではありません。ハードウェアに依存しますが、これは許容できるソリューションです(強力なハードウェアを使用し、マルチスレッドの分析ワークロードを実行しない場合)が、CPU使用率が問題にならない場合でも、ノードの1つに混合ワークロードがあるという事実( OLTPおよびOLAP)だけでも、いくつかのパフォーマンス上の課題が発生します。 OLAPクエリは、OLTPワークロードに必要なデータをバッファプールから削除します。これにより、OLTPクエリの速度が低下します。幸いなことに、分析ワークロードを通常のクエリから分離するシンプルで効率的な方法、つまり非同期レプリケーションスレーブがあります。
レプリケーションスレーブは非常にシンプルなソリューションです。必要なのはプロビジョニング可能な別のホストだけであり、GaleraClusterからそのノードへの非同期レプリケーションを構成する必要があります。非同期レプリケーションでは、スレーブがクラスターの残りの部分に影響を与えることはありません。負荷が高く、異なる(それほど強力ではない)ハードウェアを使用している場合でも、コアクラスターからの複製を続行します。最悪のシナリオは、レプリケーションスレーブが遅れ始めますが、マルチスレッドレプリケーションを実装するか、最終的にレプリケーションスレーブをスケールアップするかはユーザー次第です。
レプリケーションスレーブが起動して実行されたら、より重いクエリを実行し、Galeraクラスターをオフロードする必要があります。これは、セットアップと環境に応じて、複数の方法で実行できます。 ProxySQLを使用すると、ソースホスト、ユーザー、スキーマ、またはクエリ自体に基づいて、クエリを分析スレーブに簡単に送信できます。それ以外の場合は、分析クエリを正しいホストに送信するのはアプリケーション次第です。
レプリケーションスレーブの設定はそれほど複雑ではありませんが、MySQLやxtrabackupなどのツールに習熟していない場合でも注意が必要です。プロセス全体は、新しいサーバーにリポジトリを設定し、MySQLデータベースをインストールすることで構成されます。次に、Galeraクラスターからのデータを使用してそのホストをプロビジョニングする必要があります。そのためにxtrabackupを使用できますが、mydumper / myloaderやmysqldumpなどの他のツールも同様に機能します(正しく実行する限り)。データがそこにあると、マスターガレラノードとレプリケーションスレーブ間のレプリケーションを設定する必要があります。最後に、プロキシレイヤーを再構成して新しいスレーブを含め、トラフィックをそのスレーブにルーティングするか、負荷の一部をレプリケーションスレーブにリダイレクトするために、アプリケーションがデータベースに接続する方法を微調整する必要があります。
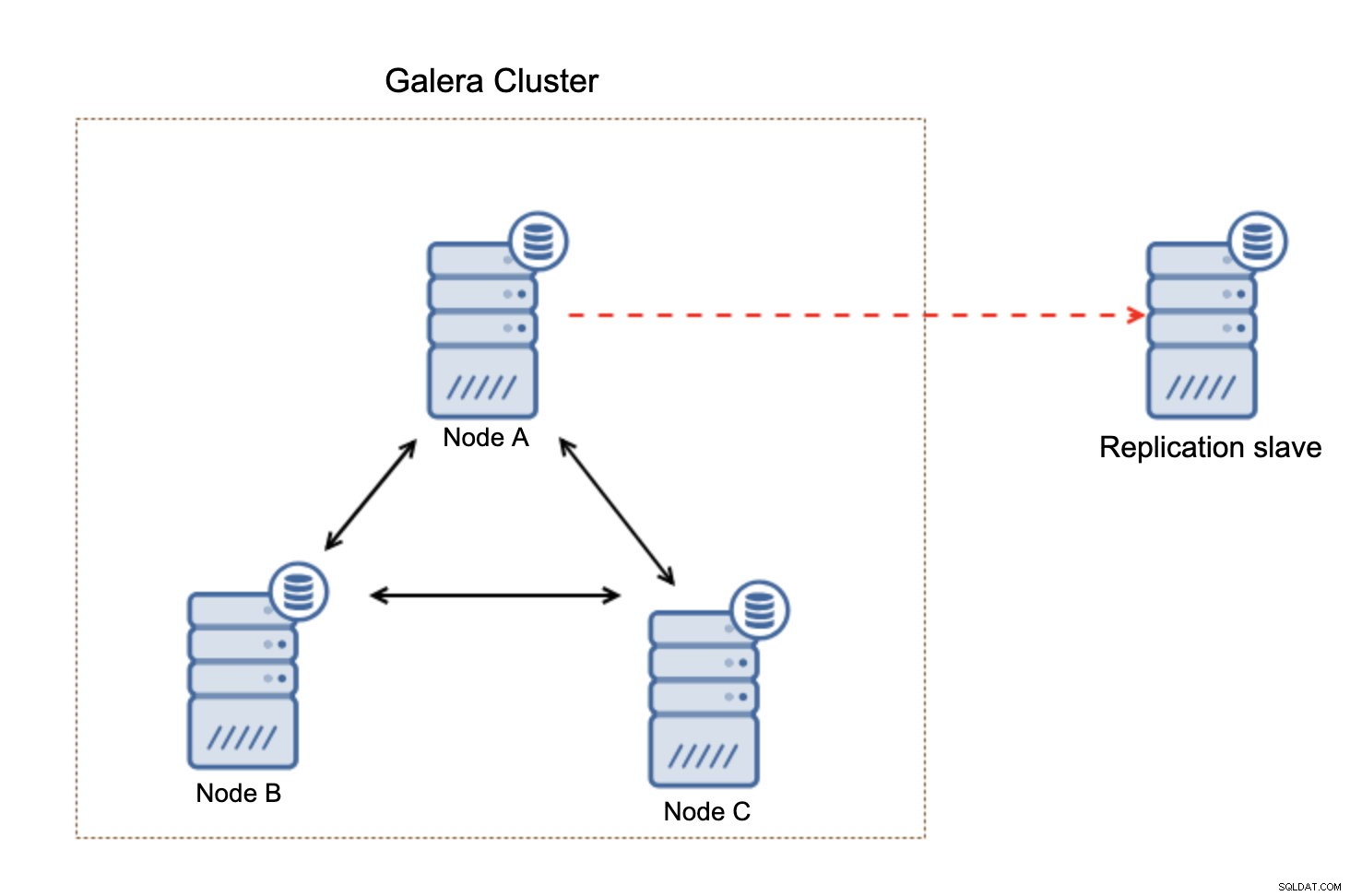
覚えておくべき重要なことは、この設定は回復力がないということです。 「マスター」Galeraノードがダウンすると、レプリケーションリンクが切断され、Galeraクラスター内の別のマスターノードからレプリカをスレーブ化するための手動アクションが実行されます。
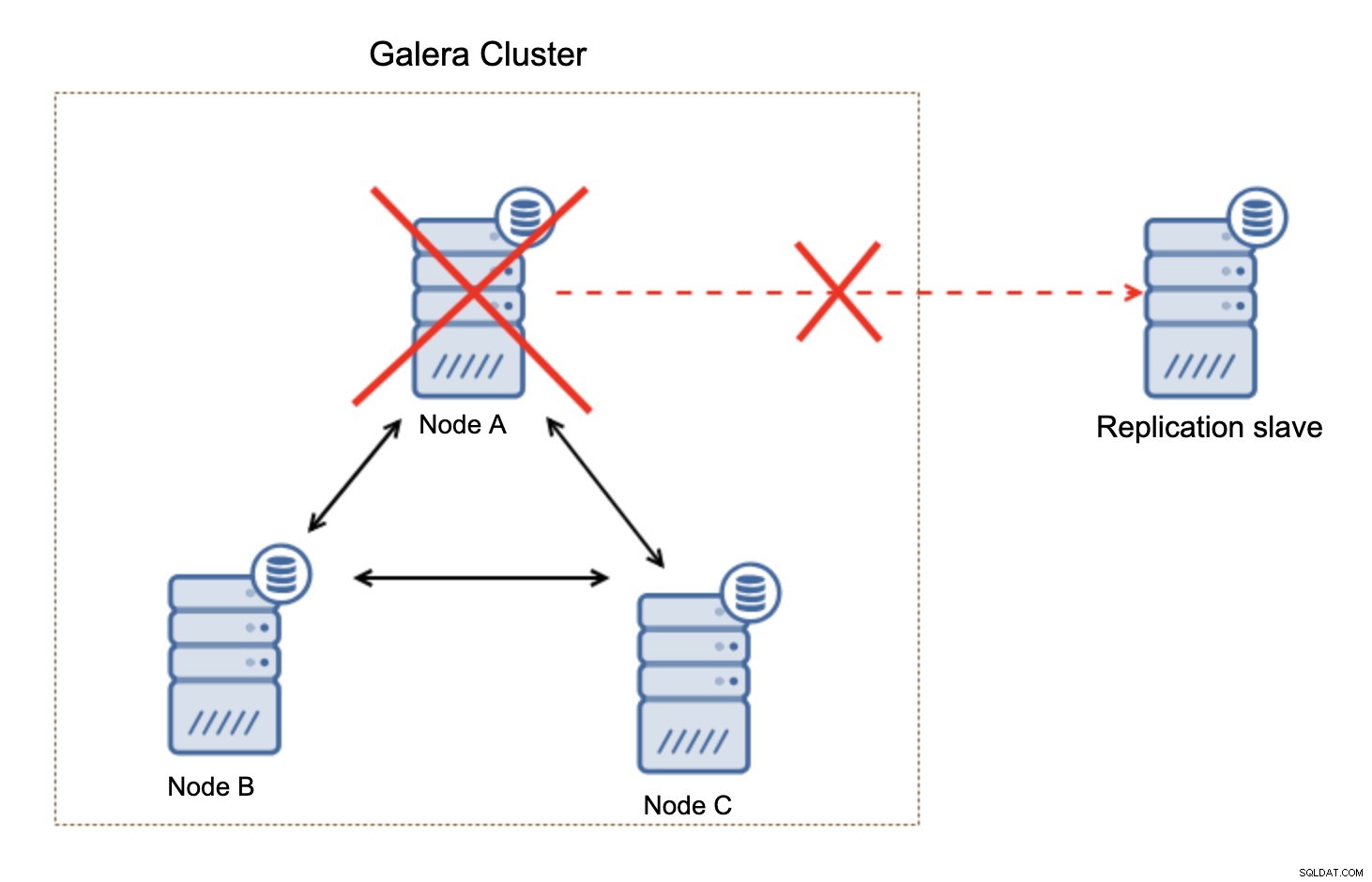
これは大したことではありません。特にGTID(グローバルトランザクションID)でレプリケーションを使用する場合は、レプリケーションが壊れていることを確認してから手動でアクションを実行する必要があります。
ClusterControlを使用してGaleraClusterへの非同期スレーブを設定するにはどうすればよいですか?
幸い、ClusterControlを使用すると、プロセス全体を自動化でき、数回クリックするだけで済みます。初期状態は、ClusterControlを使用してすでに設定されています。データベースとプロキシレイヤーの両方の高可用性を実現するために、2つのProxySQLノードと2つのKeepalivedノードを備えた3ノードのGaleraクラスターです。
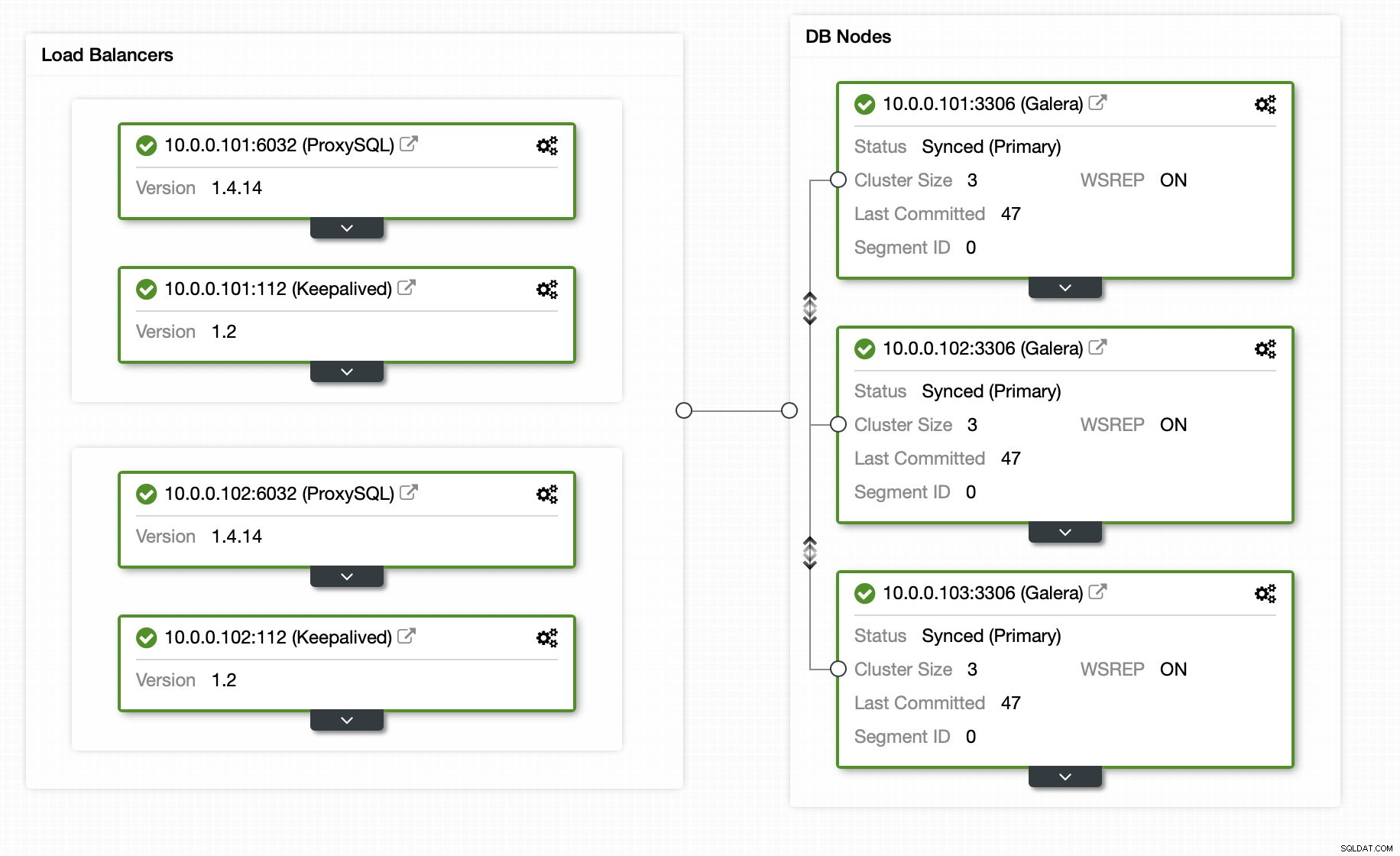
レプリケーションスレーブの追加はクリックするだけです:
明らかに、レプリケーションではバイナリログを有効にする必要があります。 Galeraノードでbinlogを有効にしていない場合は、ClusterControlからも有効にできます。バイナリログを有効にすると、構成の変更を適用するためにノードを再起動する必要があることに注意してください。
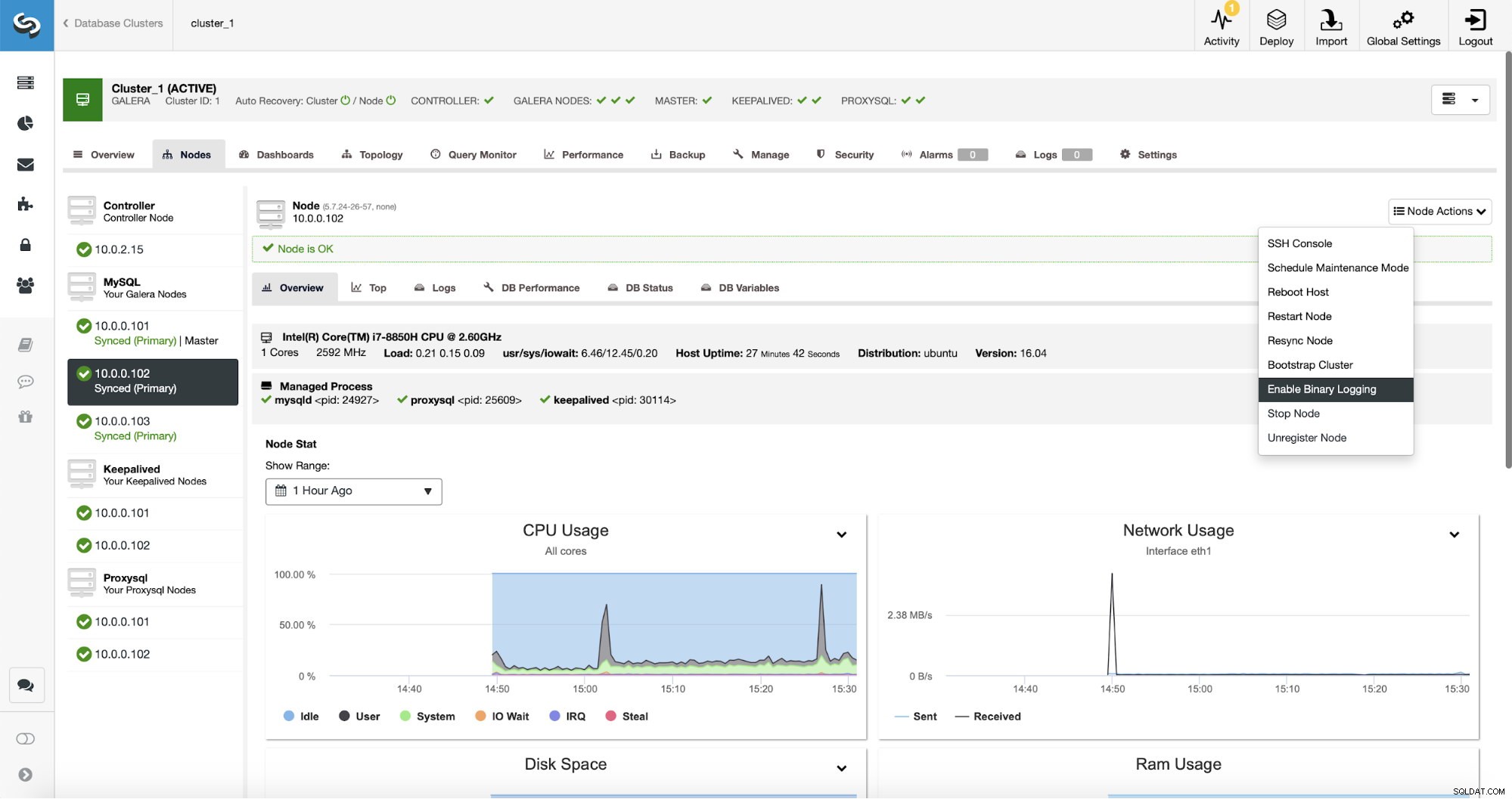
クラスタ内の1つのノードでバイナリログが有効になっている場合でも(上のスクリーンショットで「マスター」とマークされている)、少なくとももう1つのノードでバイナリログを有効にすることをお勧めします。 ClusterControlは、マスターGaleraノードがクラッシュしたことを検出した後、レプリケーションスレーブを自動的にフェイルオーバーできますが、そのためには、バイナリログが有効になっている別のマスターノードが必要です。そうでない場合、フェイルオーバーするものはありません。
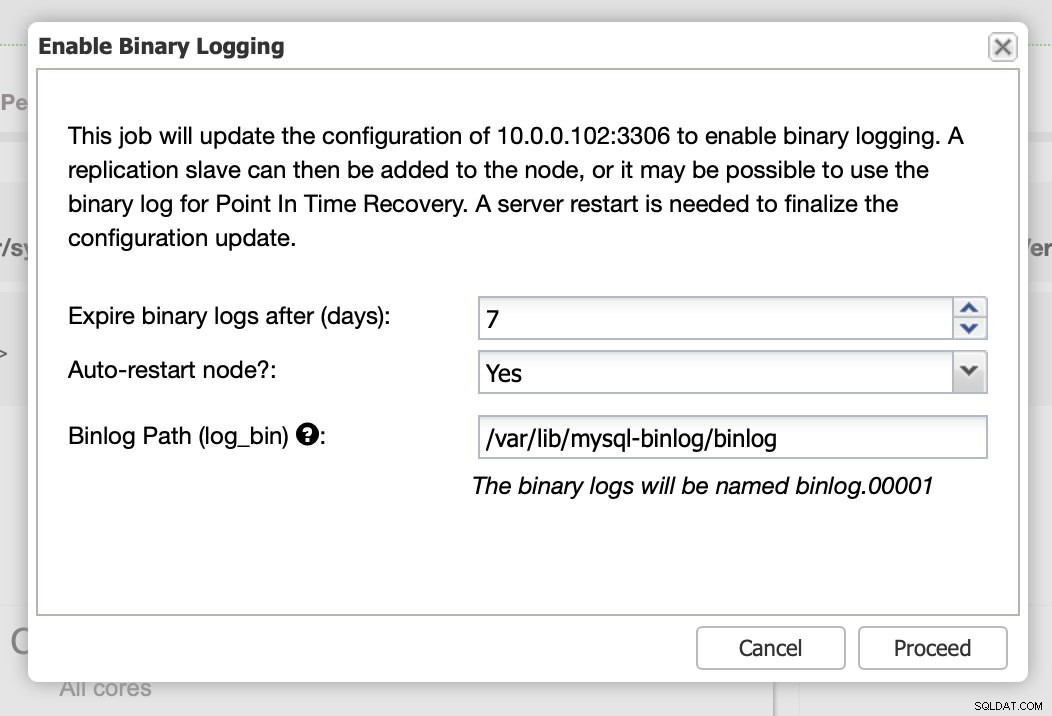
すでに述べたように、バイナリログを有効にするには再起動が必要です。すぐに実行することも、構成を変更して別のときに再起動することもできます。
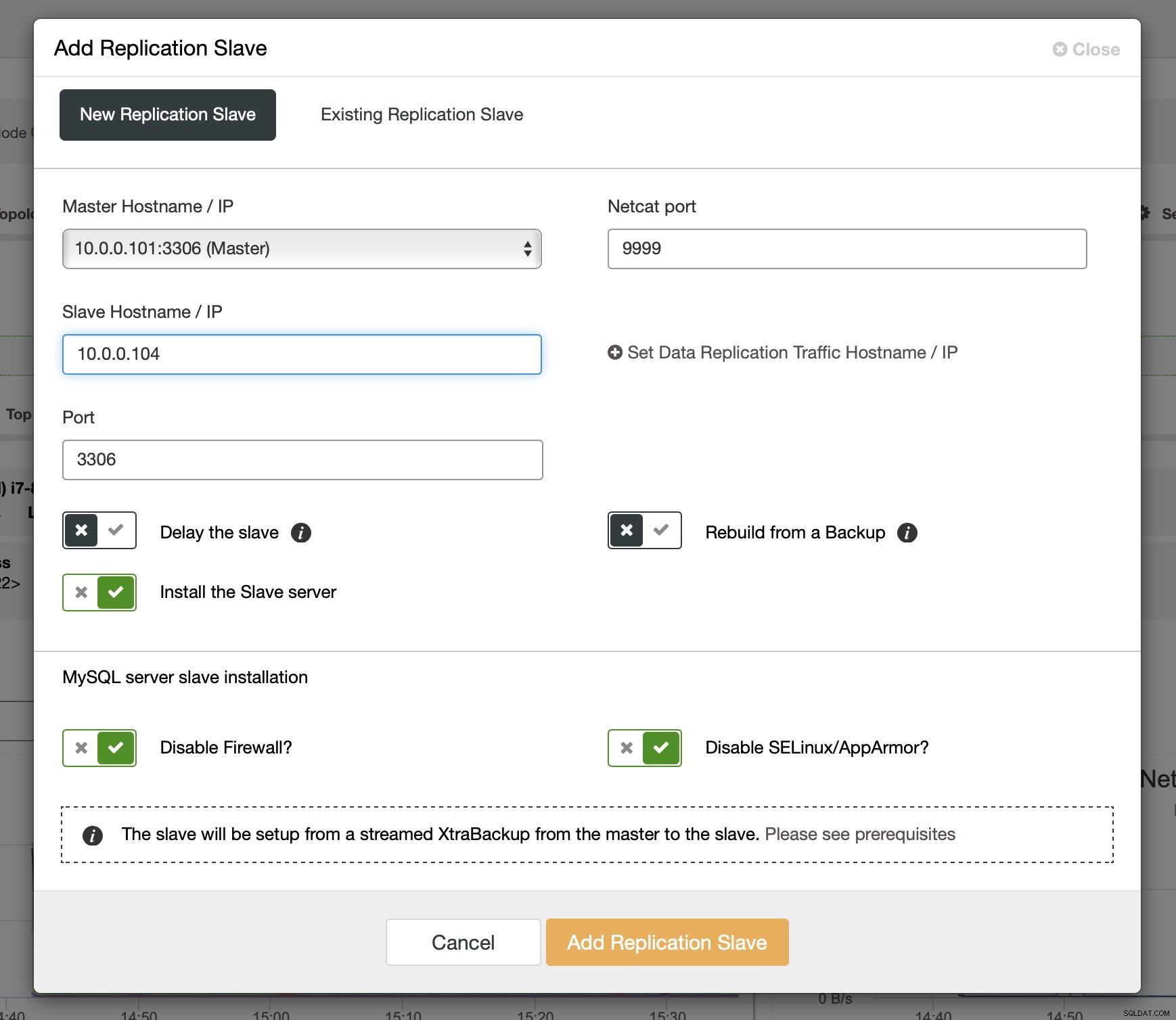
一部のGaleraノードでbinlogを有効にした後、レプリケーションスレーブの追加に進むことができます。ダイアログで、マスターホストを選択し、スレーブのホスト名またはIPアドレスを渡す必要があります。最近のバックアップが手元にある場合(これを実行する必要があります)、それを使用してスレーブをプロビジョニングできます。それ以外の場合、ClusterControlはxtrabackupを使用してプロビジョニングします。最近のすべてのマスターデータがスレーブにストリーミングされてから、レプリケーションが構成されます。
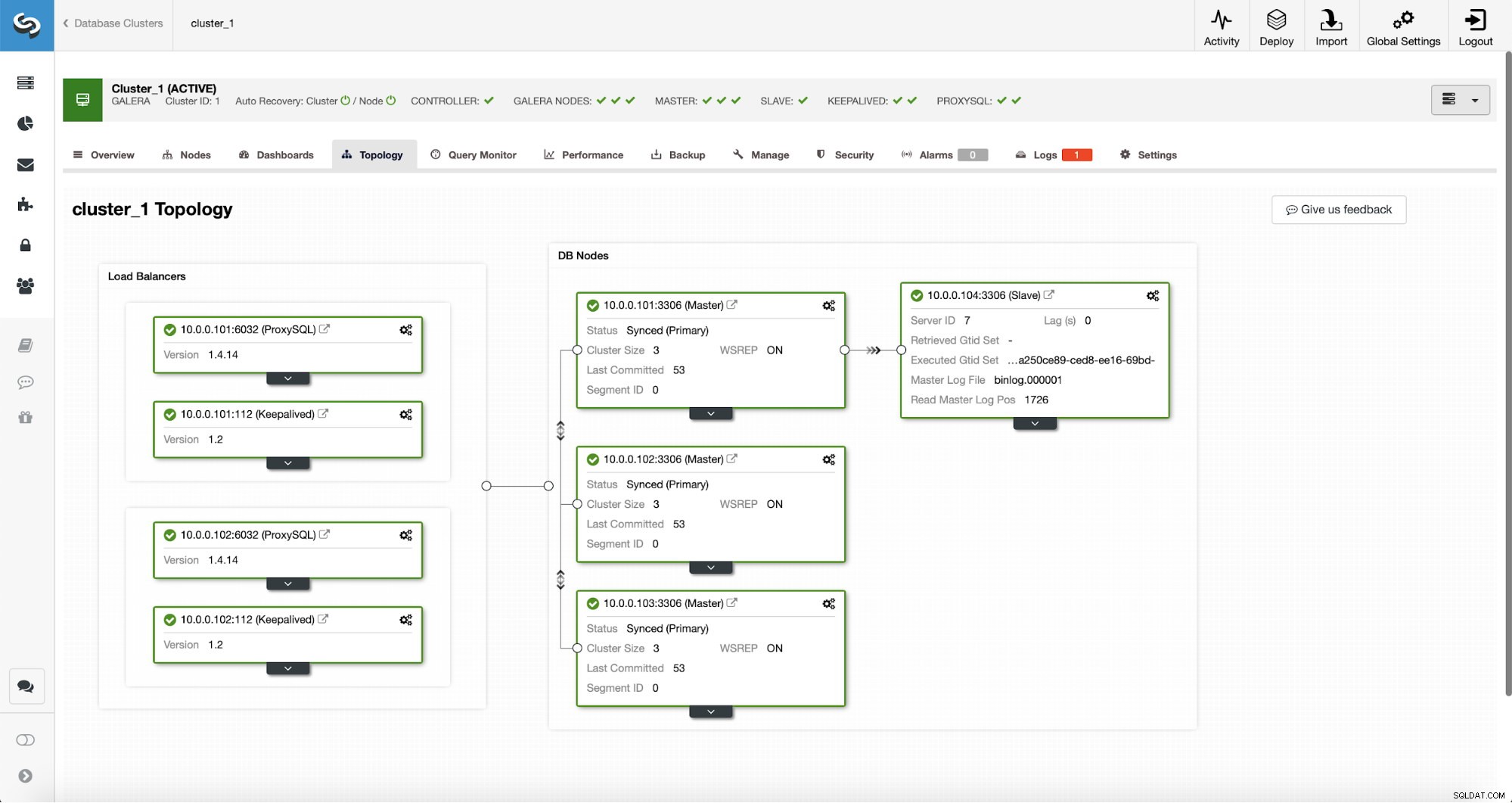
ジョブが完了すると、レプリケーションスレーブがクラスターに追加されます。前述のように、10.0.0.101が停止すると、Galeraクラスター内の別のホストがマスターとして選択され、ClusterControlは自動的に別のノードから10.0.0.104をスレーブします。
ProxySQLを使用するため、構成する必要があります。 ProxySQLに新しいサーバーを追加します。
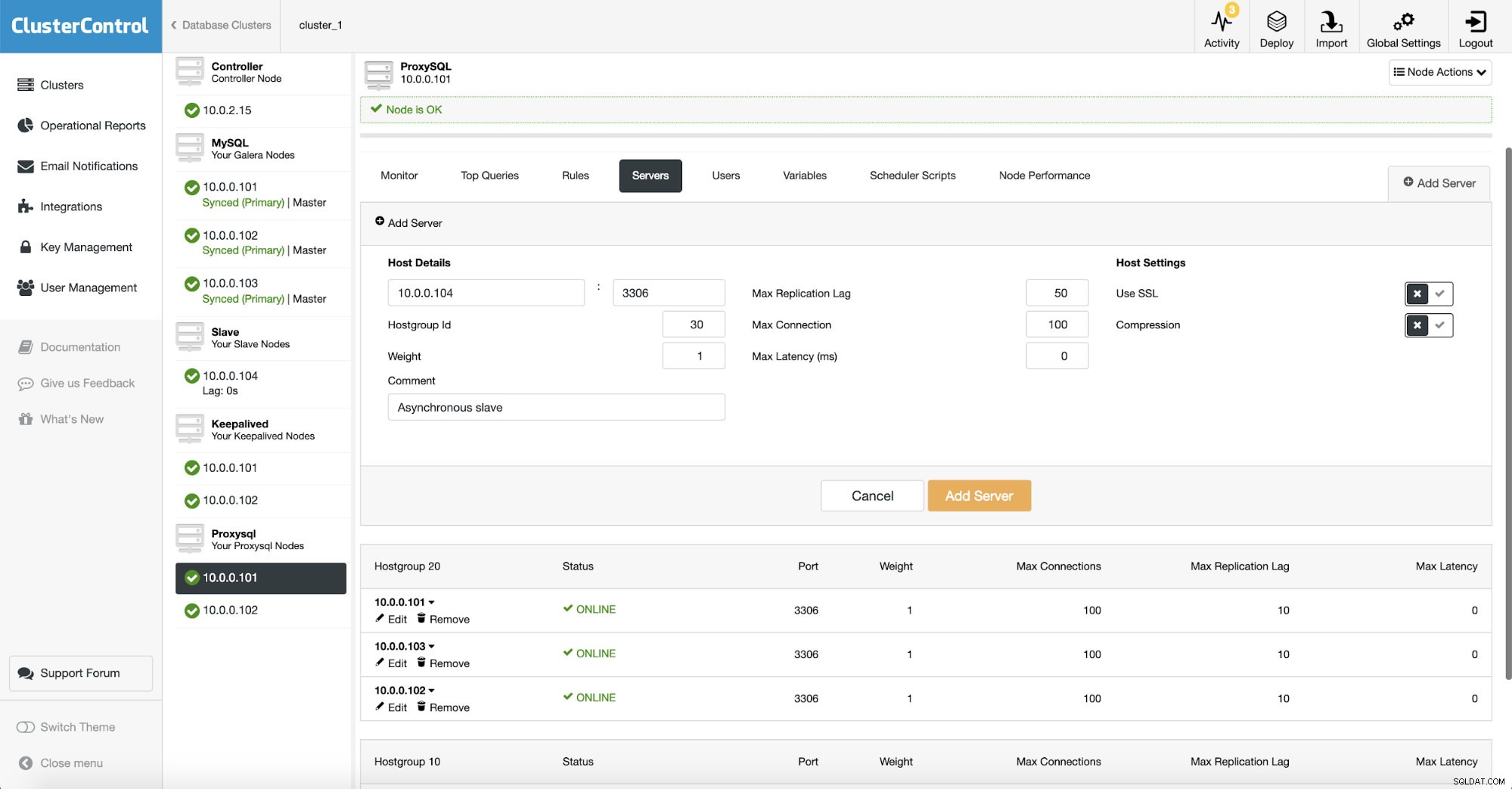
非同期スレーブを配置する別のホストグループ(30)を作成しました。また、「最大レプリケーションラグ」をデフォルトの10秒から50秒に増やしました。問題が発生する前に分析スレーブがどれだけ遅れることができるかは、ビジネス要件次第です。
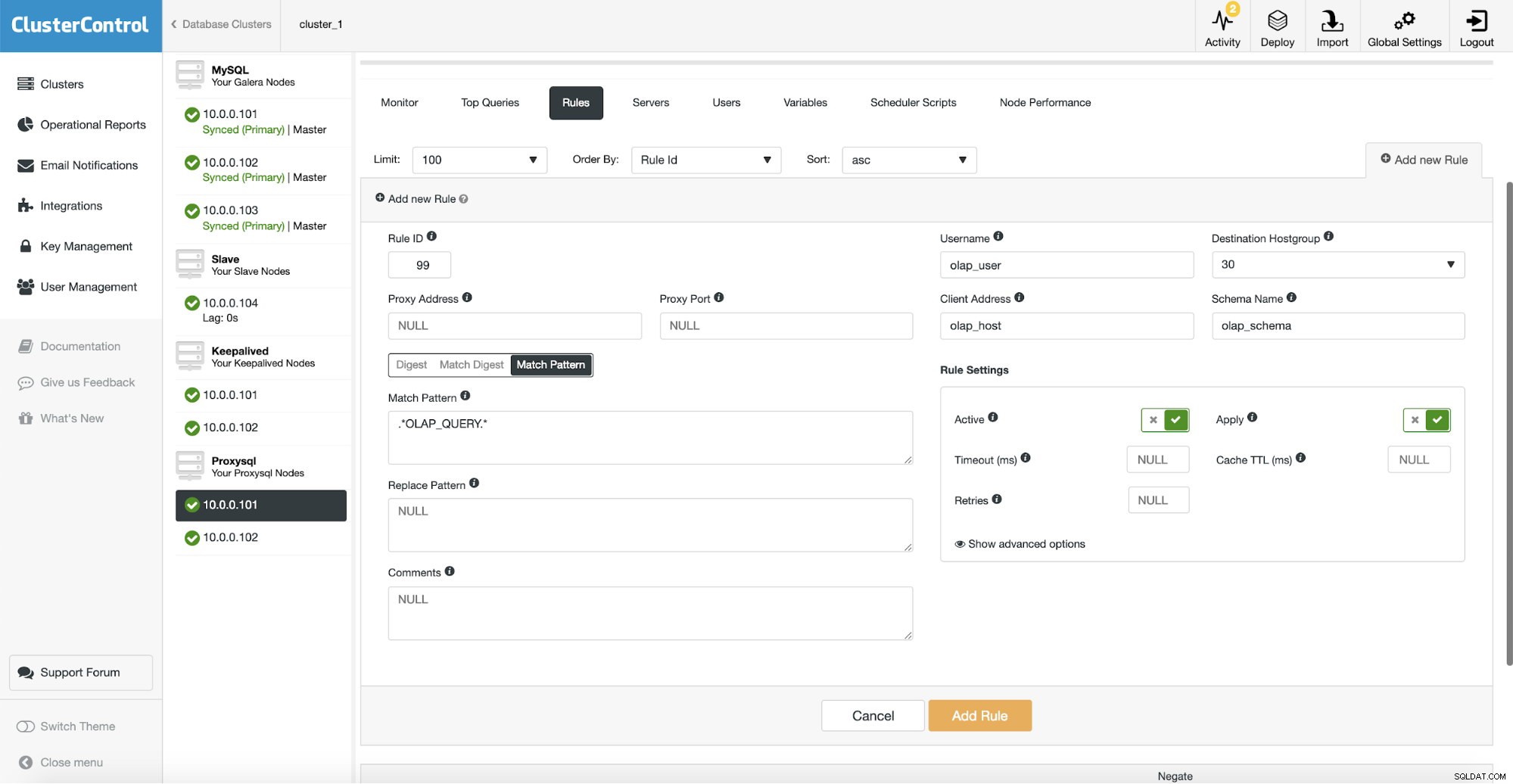
その後、OLAPトラフィックに一致するクエリルールを構成し、それをOLAPホストグループにルーティングする必要があります(30)。上のスクリーンショットでは、いくつかのフィールドに入力しました。これは必須ではありません。通常、最大で1つまたは2つを使用する必要があります。上記のスクリーンショットは例として機能するため、スキーマ(分析データを含む別のスキーマがある場合)、ホスト名/ IP(OLAPクエリが特定のホストから実行される場合)、ユーザー(アプリケーションが使用する場合)を使用してクエリを照合できることが簡単にわかります。分析クエリの特定のユーザー。完全なクエリを渡すか、SQLコメントでマークして、ProxySQLに「OLAP_QUERY」文字列を含むすべてのクエリを分析ホストグループにルーティングさせることで、クエリを直接照合することもできます。
ご覧のとおり、ClusterControlのおかげで、数回クリックするだけでレプリケーションスレーブをGaleraClusterにデプロイできました。 MySQLは分析ワークロードに最適なデータベースではないと主張する人もいるかもしれませんが、私たちは同意する傾向があります。 ClickHouseを使用し、非同期スレーブからClickHouseカラム型データストアへのレプリケーションを設定することで、この設定を簡単に拡張して、分析クエリのパフォーマンスを大幅に向上させることができます。この設定については、以前のブログ投稿の1つで説明しました。