最近発表したように、ClusterControl1.7.4にはクラスター間レプリケーションと呼ばれる新機能があります。これにより、2つの自律クラスター間でレプリケーションを実行できます。詳細については、上記の発表を参照してください。
マスタークラスターを機能させるには、いくつかの要件があります。
- PostgreSQL9.6以降。
- ClusterControlロール「マスター」を持つPostgreSQLサーバーが必要です。
- スレーブクラスターを設定する場合、管理者の資格情報はマスタークラスターと同一である必要があります。
最初の要件については、マスタークラスターで正しいPostgreSQLバージョンを使用していることを確認し、スレーブクラスターにも同じバージョンを選択してください。
$ psql
postgres=# select version();
PostgreSQL 11.5 on x86_64-pc-linux-gnu, compiled by gcc (GCC) 4.8.5 20150623 (Red Hat 4.8.5-36), 64-bitマスターの役割を特定のノードに割り当てる必要がある場合は、ClusterControlUIから行うことができます。 ClusterControl->マスタークラスターの選択->ノード->ノードの選択->ノードアクション->スレーブのプロモートに移動します。
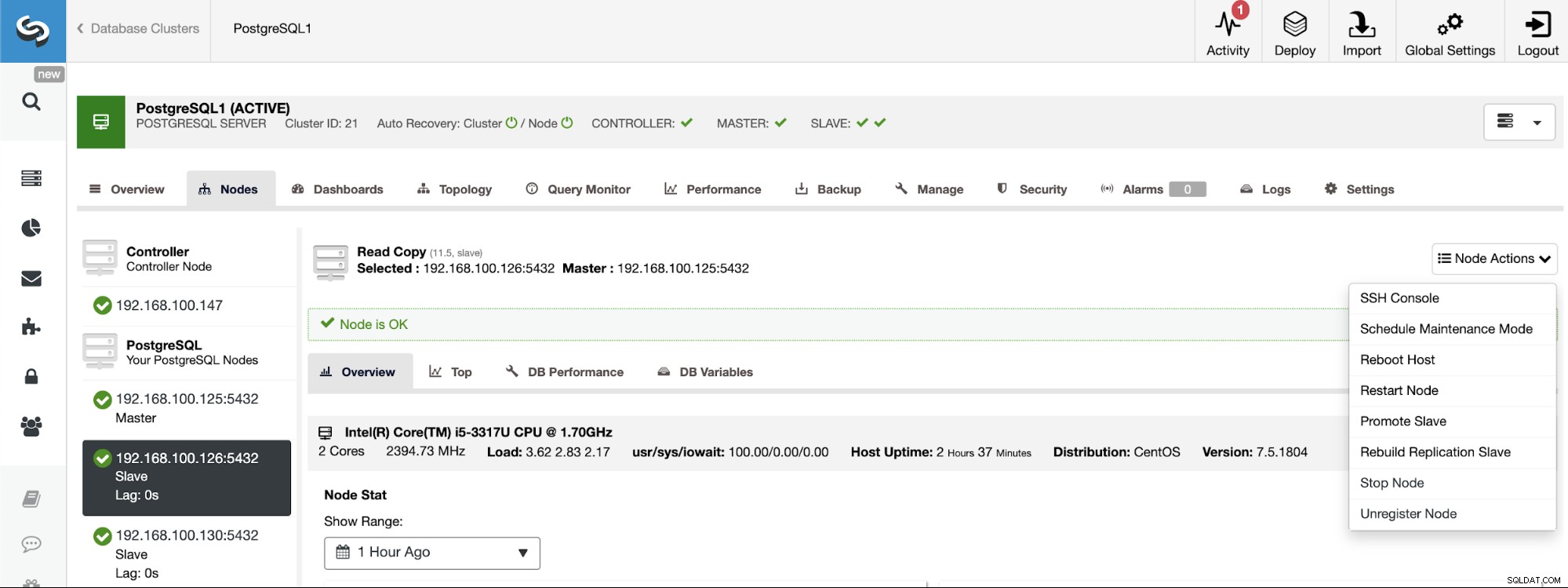
最後に、スレーブクラスターの作成中に同じ管理者を使用する必要がありますマスタークラスターで現在使用している資格情報。次のセクションで追加する場所がわかります。
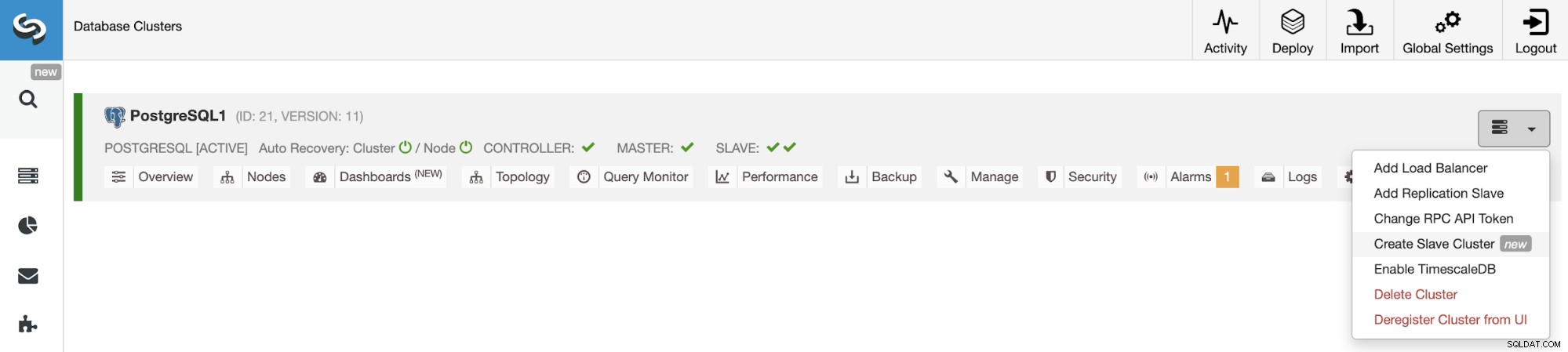
ClusterControlUIからのスレーブクラスターの作成
新しいスレーブクラスターを作成するには、ClusterControl->[クラスター]->[クラスターアクション]->[スレーブクラスターの作成]に移動します。
スレーブクラスターは、現在のマスタークラスターからデータをストリーミングすることによって作成されます。
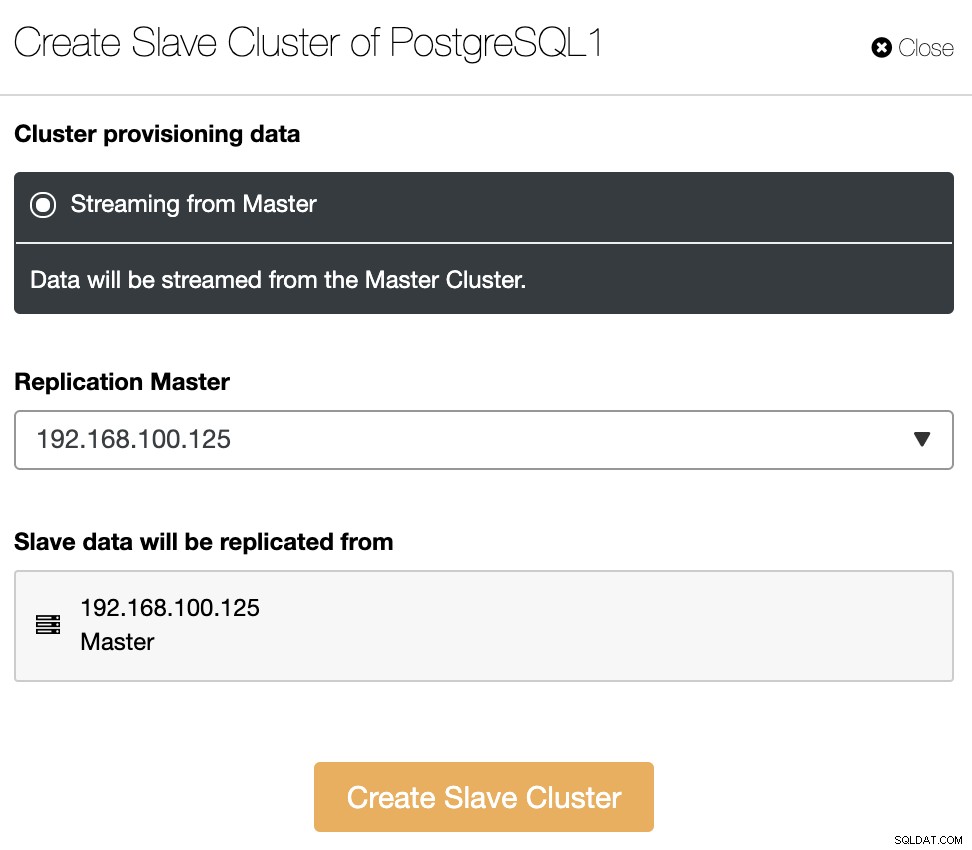
このセクションでは、現在のクラスターのマスターノードも選択する必要がありますそこからデータが複製されます。
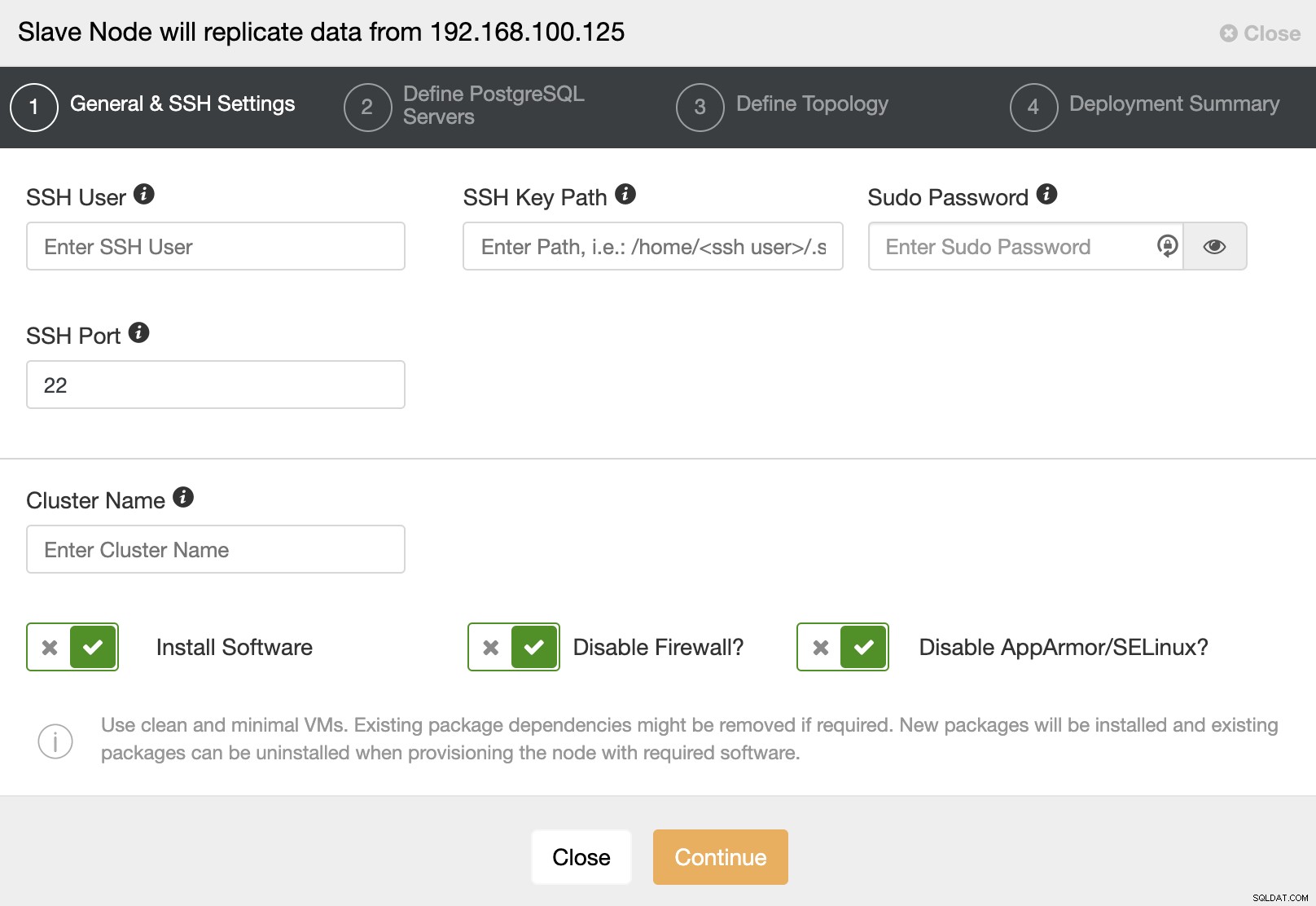
次の手順に進むときは、ユーザー、キー、またはを指定する必要がありますSSHでサーバーに接続するためのパスワードとポート。また、スレーブクラスターの名前と、ClusterControlに対応するソフトウェアと構成をインストールさせる場合も必要です。
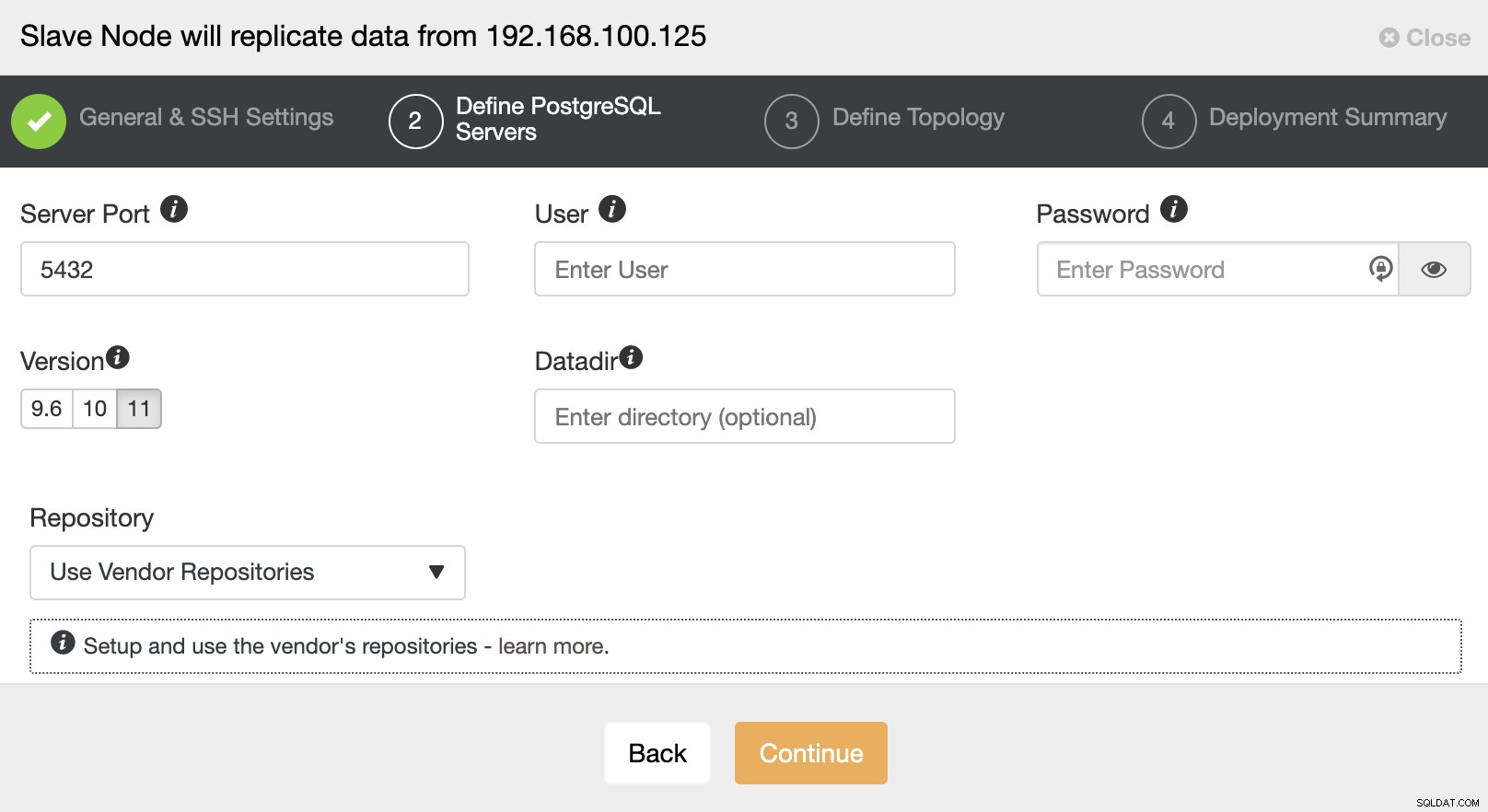
SSHアクセス情報を設定した後、データベースのバージョンを定義する必要があります。 datadir、port、およびadminの資格情報。ストリーミングレプリケーションを使用するため、同じデータベースバージョンを使用していることを確認してください。前述したように、資格情報はマスタークラスターで使用されているものと同じである必要があります。使用するリポジトリを指定することもできます。
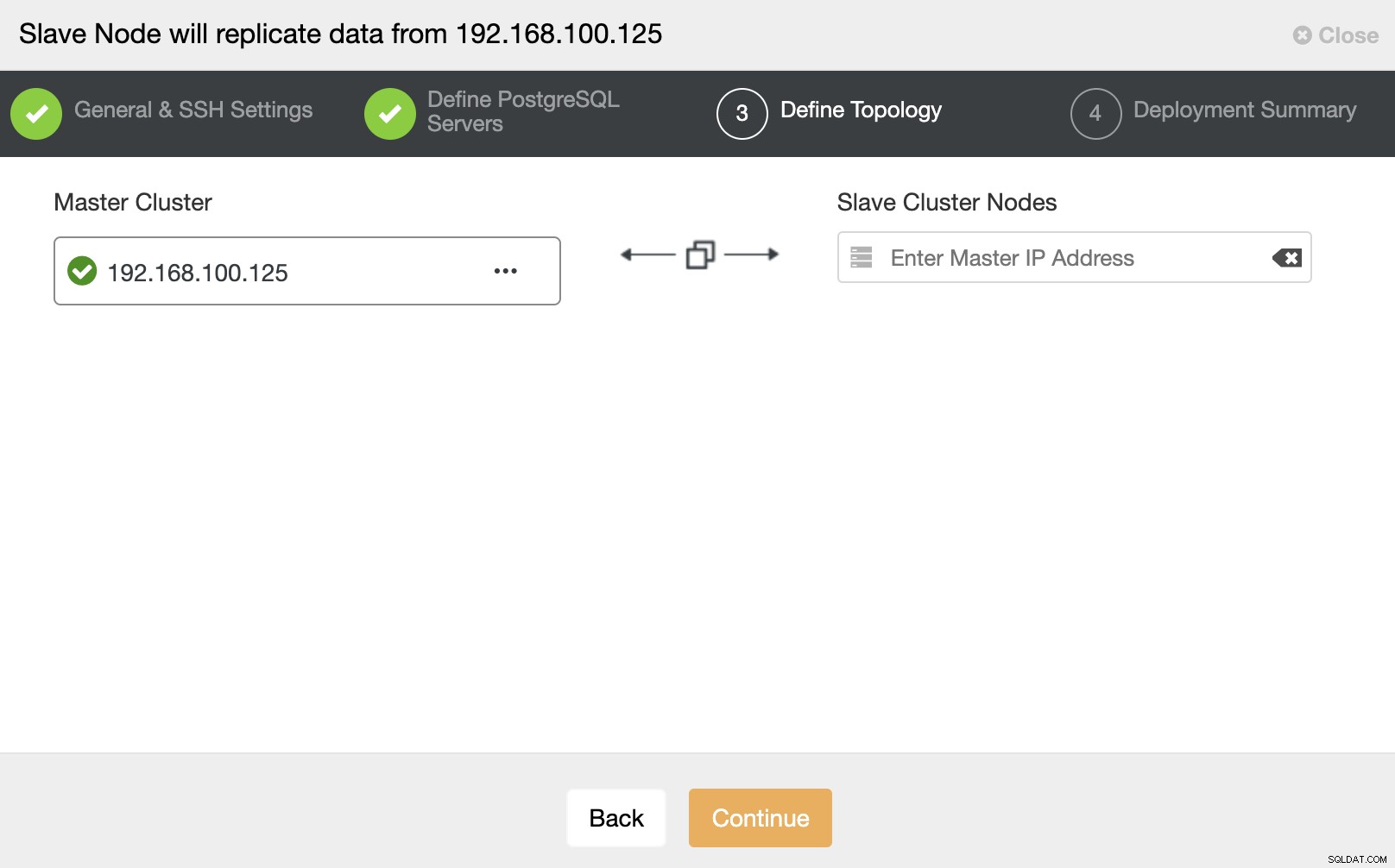
このステップでは、サーバーを新しいスレーブクラスターに追加する必要があります。このタスクでは、データベースノードのIPアドレスまたはホスト名の両方を入力できます。
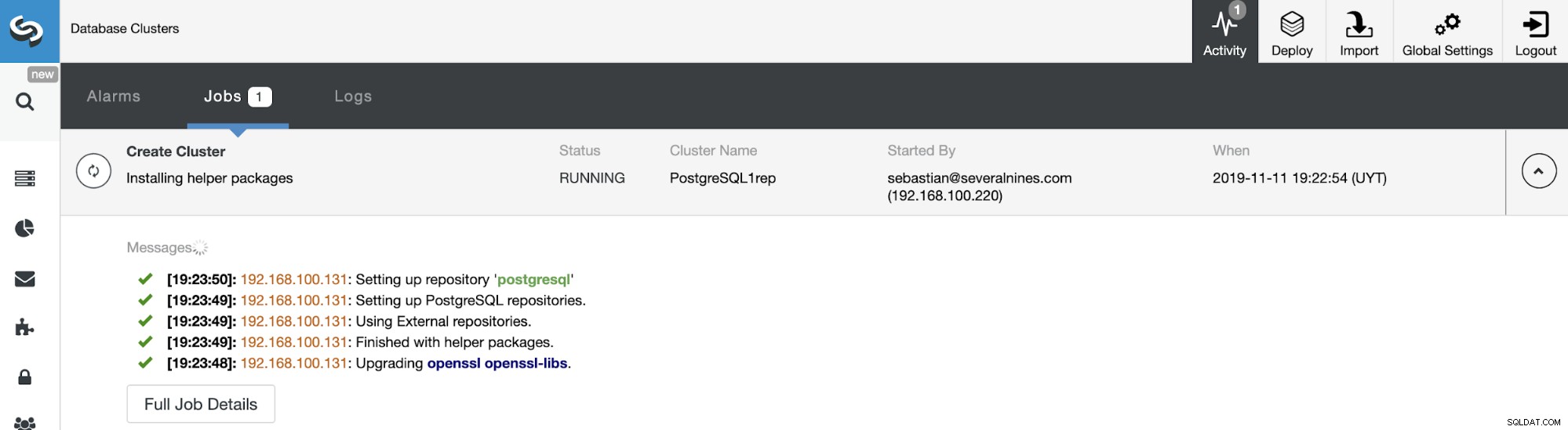
から、新しいスレーブクラスターの作成ステータスを監視できます。 ClusterControlアクティビティモニター。タスクが完了すると、ClusterControlのメイン画面にクラスターが表示されます。
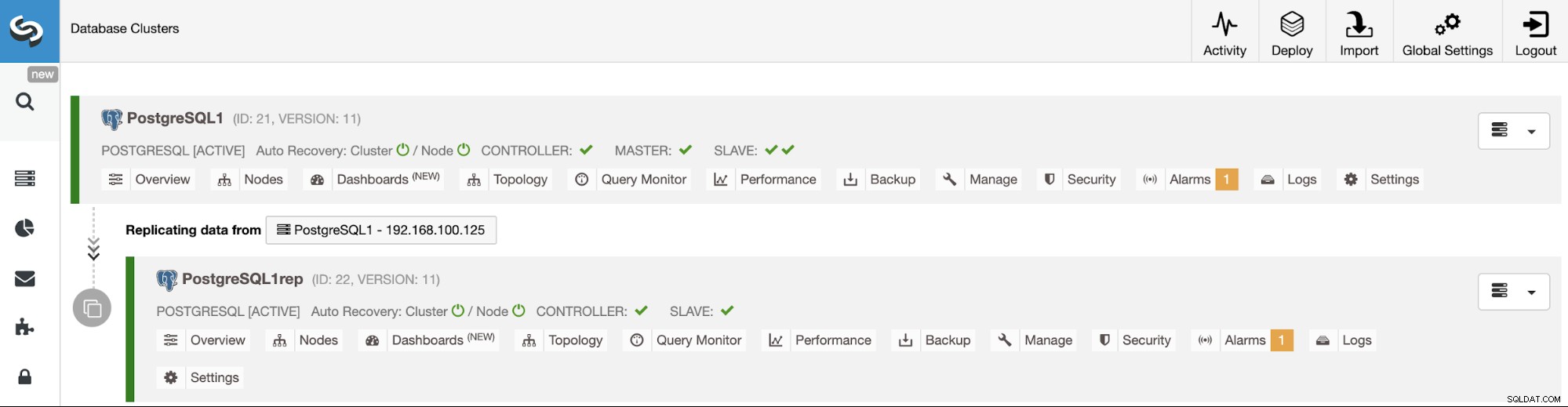
ClusterControlUIを使用したクラスター間レプリケーションの管理
これで、クラスター間レプリケーションが稼働しました。ClusterControlを使用してこのトポロジで実行するさまざまなアクションがあります。
スレーブクラスターを再構築するには、ClusterControl->[スレーブクラスター]の選択->[ノード]->[マスタークラスターに接続されているノードの選択]->[ノードアクション]->[レプリケーションスレーブの再構築]に移動します。
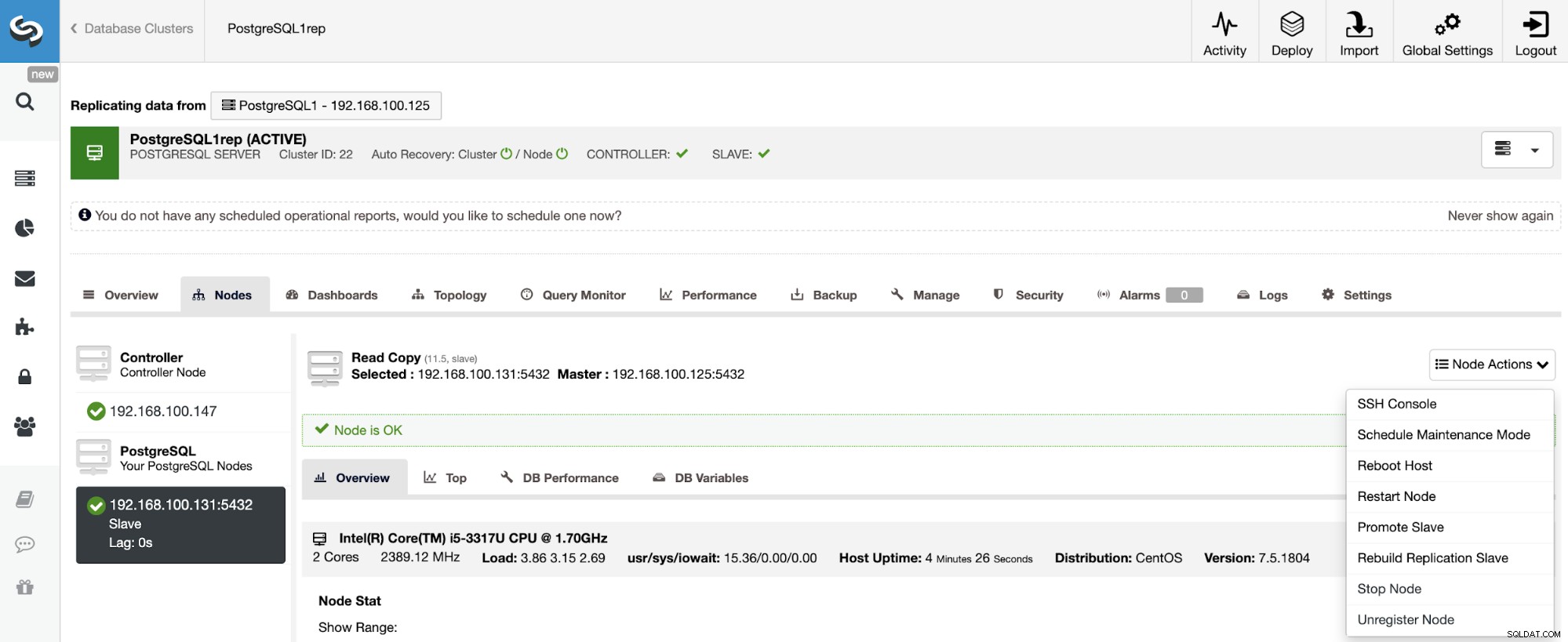
ClusterControlは次の手順を実行します。
- PostgreSQLサーバーを停止する
- pg_basebackupを使用してマスターからスレーブにバックアップをストリーミングします
PostgreSQLでのレプリケーションの停止と開始は、一時停止と再開を意味しますが、これらの用語は、サポートしている他のデータベーステクノロジーとの一貫性を保つために使用しています。
この関数は、まもなくClusterControlUIから使用できるようになります。このアクションでは、pg_wal_replay_pauseおよびpg_wal_replay_resumePostgreSQL関数を使用してこのタスクを実行します。
一方、回避策を使用して、ClusterControlを使用した簡単な方法で、レプリケーションスレーブの停止と開始を行い、データベースノードを停止および開始できます。
ClusterControlに移動->スレーブクラスターを選択->ノード->を選択ノード->ノードアクション->ノードの停止/ノードの開始。このアクションにより、データベースサービスが直接停止/開始されます。
ClusterControlCLIを使用したクラスター間レプリケーションの管理
前のセクションでは、ClusterControlUIを使用してクラスター間レプリケーションを管理する方法を確認できました。それでは、コマンドラインを使用してそれを行う方法を見てみましょう。
注:このブログの冒頭で述べたように、ClusterControlがインストールされており、マスタークラスターがそれを使用してデプロイされていることを前提としています。
まず、ClusterControlCLIを使用してスレーブクラスターを作成するコマンドの例を見てみましょう。
$ s9s cluster --create --cluster-name=PostgreSQL1rep --cluster-type=postgresql --provider-version=11 --nodes="192.168.100.133" --os-user=root --os-key-file=/root/.ssh/id_rsa --db-admin=admin --db-admin-passwd=********* --vendor=postgres --remote-cluster-id=21 --logこれで、作成スレーブプロセスが実行されました。使用されている各パラメータを見てみましょう:
- クラスター:クラスターを一覧表示して操作します。
- 作成:新しいクラスターを作成してインストールします。
- Cluster-name:新しいスレーブクラスターの名前。
- Cluster-type:インストールするクラスターのタイプ。
- プロバイダーバージョン:ソフトウェアバージョン。
- ノード:スレーブクラスター内の新しいノードのリスト。
- Os-user:SSHコマンドのユーザー名。
- Os-key-file:SSH接続に使用するキーファイル。
- Db-admin:データベース管理者のユーザー名。
- Db-admin-passwd:データベース管理者のパスワード。
- Remote-cluster-id:クラスター間レプリケーションのマスタークラスターID。
- ログ:ジョブメッセージを待って監視します。
--logフラグを使用すると、ログをリアルタイムで確認できます。
Verifying job parameters.
192.168.100.133: Checking ssh/sudo.
192.168.100.133: Checking if host already exists in another cluster.
Checking job arguments.
Found top level master node: 192.168.100.133
Verifying nodes.
Checking nodes that those aren't in another cluster.
Checking SSH connectivity and sudo.
192.168.100.133: Checking ssh/sudo.
Checking OS system tools.
Installing software.
Detected centos (core 7.5.1804).
Data directory was not specified. Using directory '/var/lib/pgsql/11/data'.
192.168.100.133:5432: Configuring host and installing packages if neccessary.
...
Cluster 26 is running.
Generated & set RPC authentication token.次のコマンドを使用して、スレーブクラスターを再構築できます。
$ s9s replication --stage --master="192.168.100.125" --slave="192.168.100.133" --cluster-id=26 --remote-cluster-id=21 --log- レプリケーション:データレプリケーションを監視および制御します。
- ステージ:レプリケーションスレーブをステージング/再構築します。
- マスター:マスタークラスター内のレプリケーションマスター。
- スレーブ:スレーブクラスター内のレプリケーションスレーブ。
- Cluster-id:スレーブクラスターID。
- Remote-cluster-id:マスタークラスターID。
- ログ:ジョブメッセージを待って監視します。
Rebuild replication slave 192.168.100.133:5432 from master 192.168.100.125:5432.
Remote cluster id = 21
192.168.100.125: Checking size of '/var/lib/pgsql/11/data'.
192.168.100.125: /var/lib/pgsql/11/data size is 201.13 MiB.
192.168.100.133: Checking free space in '/var/lib/pgsql/11/data'.
192.168.100.133: /var/lib/pgsql/11/data has 28.78 GiB free space.
192.168.100.125:5432(master): Verifying PostgreSQL version.
192.168.100.125: Verifying the timescaledb-postgresql-11 installation.
192.168.100.125: Package timescaledb-postgresql-11 is not installed.
Setting up replication 192.168.100.125:5432->192.168.100.133:5432
Collecting server variables.
192.168.100.125:5432: Using the pg_hba.conf contents for the slave.
192.168.100.125:5432: Will copy the postmaster.opts to the slave.
192.168.100.133:5432: Updating slave configuration.
Writing file '192.168.100.133:/var/lib/pgsql/11/data/postgresql.conf'.
192.168.100.133:5432: GRANT new node on members to do pg_basebackup.
192.168.100.125:5432: granting 192.168.100.133:5432.
192.168.100.133:5432: Stopping slave.
192.168.100.133:5432: Stopping PostgreSQL node.
192.168.100.133: waiting for server to shut down.... done
server stopped
…
192.168.100.133: waiting for server to start....2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv4 address "0.0.0.0", port 5432
2019-11-12 15:51:11.767 UTC [8005] LOG: listening on IPv6 address "::", port 5432
2019-11-12 15:51:11.769 UTC [8005] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
2019-11-12 15:51:11.774 UTC [8005] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
2019-11-12 15:51:11.798 UTC [8005] LOG: redirecting log output to logging collector process
2019-11-12 15:51:11.798 UTC [8005] HINT: Future log output will appear in directory "log".
done
server started
192.168.100.133:5432: Grant cluster members on the new node (for failover).
Grant connect access for new host in cluster.
Adding grant on 192.168.100.125:5432.
192.168.100.133:5432: Waiting until the service is started.
Replication slave job finished.UIセクションで説明したように、PostgreSQLでのレプリケーションの停止と開始は、一時停止と再開を意味しますが、これらの用語を使用して、他のテクノロジーとの並列処理を維持します。
次の方法で、マスタークラスターからのデータの複製を停止できます。
$ s9s replication --stop --slave="192.168.100.133" --cluster-id=26 --logこれが表示されます:
192.168.100.133:5432: Pausing recovery of the slave.
192.168.100.133:5432: Successfully paused recovery on the slave using select pg_wal_replay_pause().これで、もう一度開始できます:
$ s9s replication --start --slave="192.168.100.133" --cluster-id=26 --logつまり、次のように表示されます:
192.168.100.133:5432: Resuming recovery on the slave.
192.168.100.133:5432: Collecting replication statistics.
192.168.100.133:5432: Slave resumed recovery successfully using select pg_wal_replay_resume().では、使用されているパラメータを確認しましょう。
- レプリケーション:データレプリケーションを監視および制御します。
- 停止/開始:スレーブを停止/複製を開始します。
- スレーブ:レプリケーションスレーブノード。
- Cluster-id:スレーブノードが存在するクラスターのID。
- ログ:ジョブメッセージを待って監視します。
この新しいClusterControl機能を使用すると、異なるPostgreSQLクラスター間のレプリケーションをすばやくセットアップし、セットアップを簡単で使いやすい方法で管理できます。 Somenines開発チームはこの機能の強化に取り組んでいるため、アイデアや提案は大歓迎です。