このブログ投稿では、MySQL用のPerconaサーバーを監視する際のいくつかの主要なメトリックとステータスを調べて、MySQLサーバーの構成を長期的に微調整できるようにします。念のため、Percona Serverには、このビルドでのみ使用できる監視メトリックがいくつかあります。バージョン8.0.20と比較すると、次の51のステータスはMySQL用のPercona Serverでのみ使用可能であり、アップストリームのOracleのMySQLCommunityServerでは使用できません。
- Binlog_snapshot_file
- Binlog_snapshot_position
- Binlog_snapshot_gtid_executed
- Com_create_compression_dictionary
- Com_drop_compression_dictionary
- Com_lock_tables_for_backup
- Com_show_client_statistics
- Com_show_index_statistics
- Com_show_table_statistics
- Com_show_thread_statistics
- Com_show_user_statistics
- Innodb_background_log_sync
- Innodb_buffer_pool_pages_LRU_flushed
- Innodb_buffer_pool_pages_made_not_young
- Innodb_buffer_pool_pages_made_young
- Innodb_buffer_pool_pages_old
- Innodb_checkpoint_age
- Innodb_ibuf_free_list
- Innodb_ibuf_segment_size
- Innodb_lsn_current
- Innodb_lsn_flushed
- Innodb_lsn_last_checkpoint
- Innodb_master_thread_active_loops
- Innodb_master_thread_idle_loops
- Innodb_max_trx_id
- Innodb_oldest_view_low_limit_trx_id
- Innodb_pages0_read
- Innodb_purge_trx_id
- Innodb_purge_undo_no
- Innodb_secondary_index_triggered_cluster_reads
- Innodb_secondary_index_triggered_cluster_reads_avoided
- Innodb_buffered_aio_submitted
- Innodb_scan_pages_contiguous
- Innodb_scan_pages_disjointed
- Innodb_scan_pages_total_seek_distance
- Innodb_scan_data_size
- Innodb_scan_deleted_recs_size
- Innodb_scrub_log
- Innodb_scrub_background_page_reorganizations
- Innodb_scrub_background_page_splits
- Innodb_scrub_background_page_split_failures_underflow
- Innodb_scrub_background_page_split_failures_out_of_filespace
- Innodb_scrub_background_page_split_failures_missing_index
- Innodb_scrub_background_page_split_failures_unknown
- Innodb_encryption_n_merge_blocks_encrypted
- Innodb_encryption_n_merge_blocks_decrypted
- Innodb_encryption_n_rowlog_blocks_encrypted
- Innodb_encryption_n_rowlog_blocks_decrypted
- Innodb_encryption_redo_key_version
- Threadpool_idle_threads
- Threadpool_threads
上記の各監視メトリックの詳細については、拡張InnoDBステータスページを確認してください。スレッドプールなどの追加のステータスは、OracleのMySQLEnterpriseでのみ使用できることに注意してください。 Percona Server for MySQL 8.0のドキュメントをチェックして、OracleのMySQL CommunityServer8.0に対するこのビルドのすべての改善点を確認してください。
MySQLのグローバルステータスを取得するには、次のいずれかのステートメントを使用します。
mysql> SHOW GLOBAL STATUS;
mysql> SHOW GLOBAL STATUS LIKE '%connect%'; -- list all status that contain string "connect"
mysql> SELECT * FROM performance_schema.global_status;
mysql> SELECT * FROM performance_schema.global_status WHERE VARIABLE_NAME LIKE '%connect%'; -- list all status that contain string "connect"サーバーが稼働していた秒数である稼働時間ステータスから始めます。
すべてのcom_*ステータスは、各ステートメントが実行された回数を示すステートメントカウンター変数です。ステートメントのタイプごとに1つのステータス変数があります。たとえば、com_deleteとcom_updateは、それぞれDELETEステートメントとUPDATEステートメントをカウントします。 com_delete_multiとcom_update_multiは似ていますが、複数テーブル構文を使用するDELETEステートメントとUPDATEステートメントに適用されます。
MySQLで実行中のすべてのプロセスを一覧表示するには、次のいずれかのステートメントを実行します。
mysql> SHOW PROCESSLIST;
mysql> SHOW FULL PROCESSLIST;
mysql> SELECT * FROM information_schema.processlist;
mysql> SELECT * FROM information_schema.processlist WHERE command <> 'sleep'; -- list all active processes except 'sleep' command.現在開いている接続(接続スレッド)の比率。この比率が高い場合は、MySQLサーバーへの同時接続が多数あり、「接続が多すぎます」エラーが発生する可能性があることを示しています。接続率を取得するには:
Current connections(%) = (threads_connected / max_connections) x 100適切な値は80%以下である必要があります。 max_connections変数を増やすか、SHOWFULLPROCESSLISTを使用して接続を調べてみてください。 「接続が多すぎます」エラーが発生すると、一部の接続が解放されるまで、MySQLデータベースサーバーは非スーパーユーザーが使用できなくなります。 max_connections変数を増やすと、MySQLのメモリフットプリントも増える可能性があることに注意してください。
これまでに見られたMySQLサーバーへの最大接続の比率。簡単な計算は次のようになります:
Max connections ever seen(%) = (max_used_connections / max_connections) x 100適切な値は80%未満である必要があります。比率が高い場合は、MySQLが一度接続数が多くなり、「接続数が多すぎます」というエラーが発生したことを示しています。現在の接続率を調べて、実際に一貫して低いままであるかどうかを確認します。それ以外の場合は、max_connections変数を増やします。 max_used_connections_timeステータスをチェックして、max_used_connectionsステータスが現在の値に達したときを示します。
thread_createdのステータスは、接続を処理するために作成されたスレッドの数です。 thread_createdが大きい場合は、thread_cache_sizeの値を増やすことをお勧めします。キャッシュのヒット/ミス率は次のように計算できます:
Threads cache hit rate (%) = (threads_created / connections) x 100これは、スレッドキャッシュのヒット率を示す割合です。 50%未満に近いほど良いです。サーバーが1秒間に数百の接続を検出する場合は、通常、ほとんどの新しい接続がキャッシュされたスレッドを使用するように、thread_cache_sizeを十分に高く設定する必要があります。
全表スキャンの比率。インデックスを使用して選択した部分だけでなく、テーブルの内容全体を読み取る必要がある操作です。結果の並べ替えやテーブルスキャンを必要とするクエリを多数実行している場合、この値は高くなります。一般に、これは、テーブルが適切にインデックス付けされていないか、クエリが既存のインデックスを利用するように記述されていないことを示しています。全表スキャンの割合を計算するには:
Full table scans (%) = (handler_read_rnd_next + handler_read_rnd) /
(handler_read_rnd_next + handler_read_rnd + handler_read_first + handler_read_next + handler_read_key + handler_read_prev)
x 100適切な値は25%未満である必要があります。 MySQLの低速クエリログ出力を調べて、次善のクエリを見つけます。
select_full_joinのステータスは、インデックスを使用しないためにテーブルスキャンを実行する結合の数です。この値が0でない場合は、テーブルのインデックスを注意深く確認する必要があります。
select_range_checkのステータスは、各行の後でキーの使用状況をチェックするキーなしの結合の数です。これが0でない場合は、テーブルのインデックスを注意深く確認する必要があります。
ソートアルゴリズムが実行しなければならなかったマージパスの比率。この値が高い場合は、sort_buffer_sizeとread_rnd_buffer_sizeの値を増やすことを検討する必要があります。簡単な比率の計算は次のとおりです。
Sort passes = sort_merge_passes / (sort_scan + sort_range)3未満の比率値が適切な値である必要があります。 sort_buffer_sizeまたはread_rnd_buffer_sizeを増やしたい場合は、許容可能な比率に達するまで少しずつ増やしてみてください。
InnoDBのパフォーマンス
InnoDBバッファープールヒット率
ページがディスクではなくメモリから取得される頻度の比率。 MySQLの初期起動時に値が低い場合は、バッファプールがウォームアップするまでしばらくお待ちください。バッファープールのヒット率を取得するには、SHOW ENGINEINNODBSTATUSステートメントを使用します。
mysql> SHOW ENGINE INNODB STATUS\G
...
----------------------
BUFFER POOL AND MEMORY
----------------------
...
Buffer pool hit rate 1000 / 1000, young-making rate 0 / 1000 not 0 / 1000
...innodb_buffer_pool_size変数を増やすと、MySQLが作業するためのより多くのスペースに対応するのに大いに役立ちます。ただし、事前に十分なRAMリソースがあることを確認してください。冗長インデックスを削除することも役立つ可能性があります。複数のバッファプールインスタンスがある場合は、すべてのインスタンスのヒット率が1000/1000に達することを確認してください。
InnoDBダーティページ
InnoDBをフラッシュする必要がある頻度の比率。書き込みの多い負荷の間、このパーセンテージが増加するのは正常です。
InnoDB dirty pages(%) = (innodb_buffer_pool_pages_dirty / innodb_buffer_pool_pages_total) x 100適切な値は75%以下である必要があります。ダーティページの割合が長期間高いままである場合は、パフォーマンスのボトルネックを回避するために、バッファプールを増やすか、より高速なディスクを取得することをお勧めします。
InnoDBはチェックポイントを待機します
クリーンなページが利用できないページをInnoDBが読み取ったり作成したりする必要がある頻度の比率。通常、InnoDBバッファープールへの書き込みはバックグラウンドで行われます。ただし、ページを読み取ったり作成したりする必要があり、クリーンなページが利用できない場合は、最初にページがフラッシュされるのを待つ必要もあります。 innodb_buffer_pool_wait_freeカウンターは、これが発生した回数をカウントします。 InnoDBがチェックポイントを待機する比率を計算するには、次の計算を使用できます。
InnoDB waits for checkpoint = innodb_buffer_pool_wait_free / innodb_buffer_pool_write_requestsinnodb_buffer_pool_wait_freeが0より大きい場合は、InnoDBバッファープールが小さすぎることを示す強力な指標であり、操作はチェックポイントで待機する必要がありました。 innodb_buffer_pool_sizeを増やすと、通常、この比率だけでなく、innodb_buffer_pool_wait_freeも減少します。適切な比率の値は1未満にとどまる必要があります。
InnoDBはREDOログを待機します
REDOログの競合の比率。 innodb_log_waitsを確認し、それが増え続ける場合は、innodb_log_buffer_sizeを増やします。また、書き込み負荷のピークが原因で、ディスクが遅すぎてディスクIOを維持できないことも意味します。次の計算を使用して、REDOログ待機率を計算します。
InnoDB waits for redolog = innodb_log_waits / innodb_log_writes適切な比率の値は1未満である必要があります。それ以外の場合は、innodb_log_buffer_sizeを増やします。
すべてのスレッドのテーブルキャッシュ使用率。簡単な計算は次のようになります:
Table cache usage(%) = (opened_tables / table_open_cache) x 100適切な値は80%未満である必要があります。パーセンテージが適切な値に達するまで、table_open_cache変数を増やします。
テーブルキャッシュのヒット使用率。簡単な計算は次のようになります:
Table cache hit ratio(%) = (open_tables / opened_tables) x 100適切なヒット率の値は90%以上である必要があります。それ以外の場合は、ヒット率が適切な値に達するまでtable_open_cache変数を増やします。
ClusterControlを使用したメトリクスモニタリング
ClusterControlはMySQL用のPerconaServerをサポートし、ClusterControl-> Performance->DBStatusページでクラスター内のすべてのノードの集約ビューを提供します。これにより、次のスクリーンショットに示すように、すべてのホストのすべてのステータスを検索するための集中型のアプローチが提供され、ステータスをフィルタリングできます。
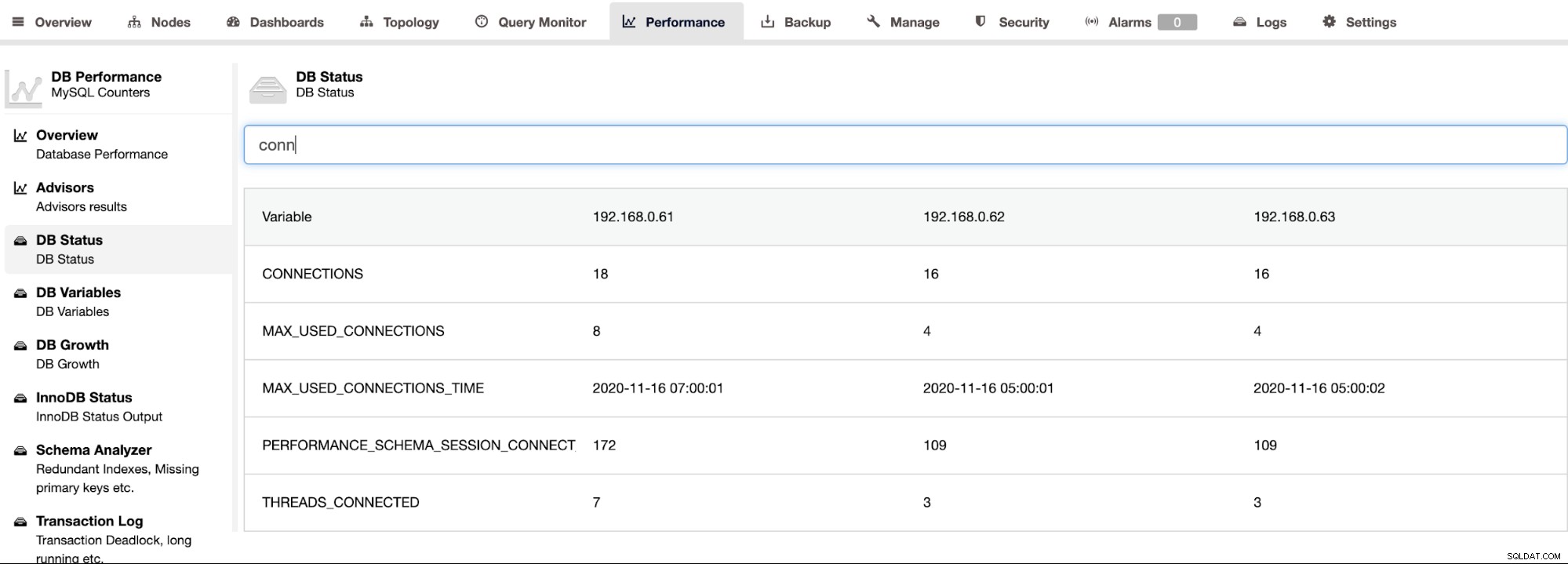
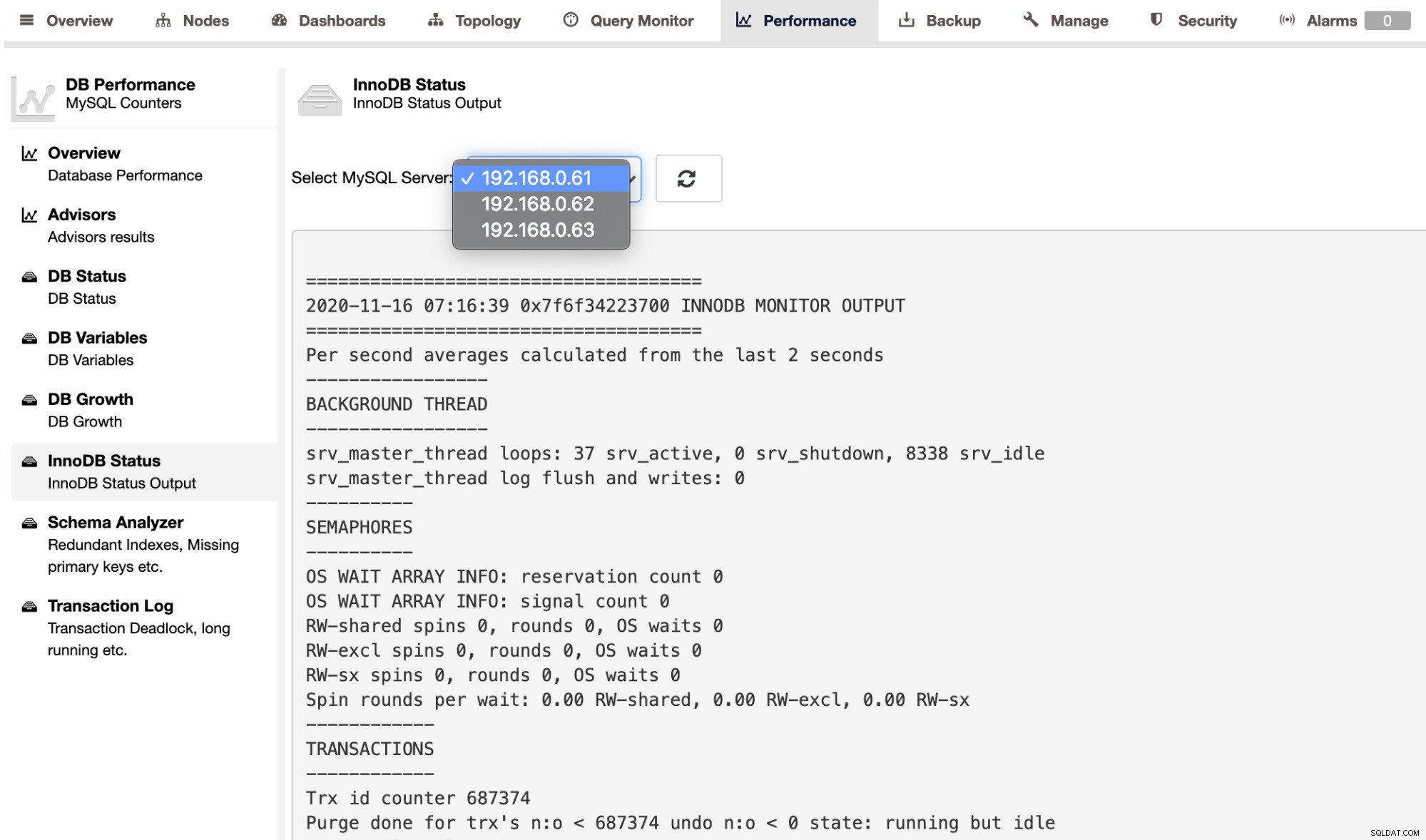
個々のサーバーのSHOWENGINEINNODB STATUS出力を取得するには、次のことができます。以下に示すように、[パフォーマンス]->[InnoDBステータス]ページを使用します。
ClusterControlには、データベースの追跡に使用できる組み込みのアドバイザーも用意されています。パフォーマンス。この機能には、ClusterControl-> Performance-> Advisors:
からアクセスできます。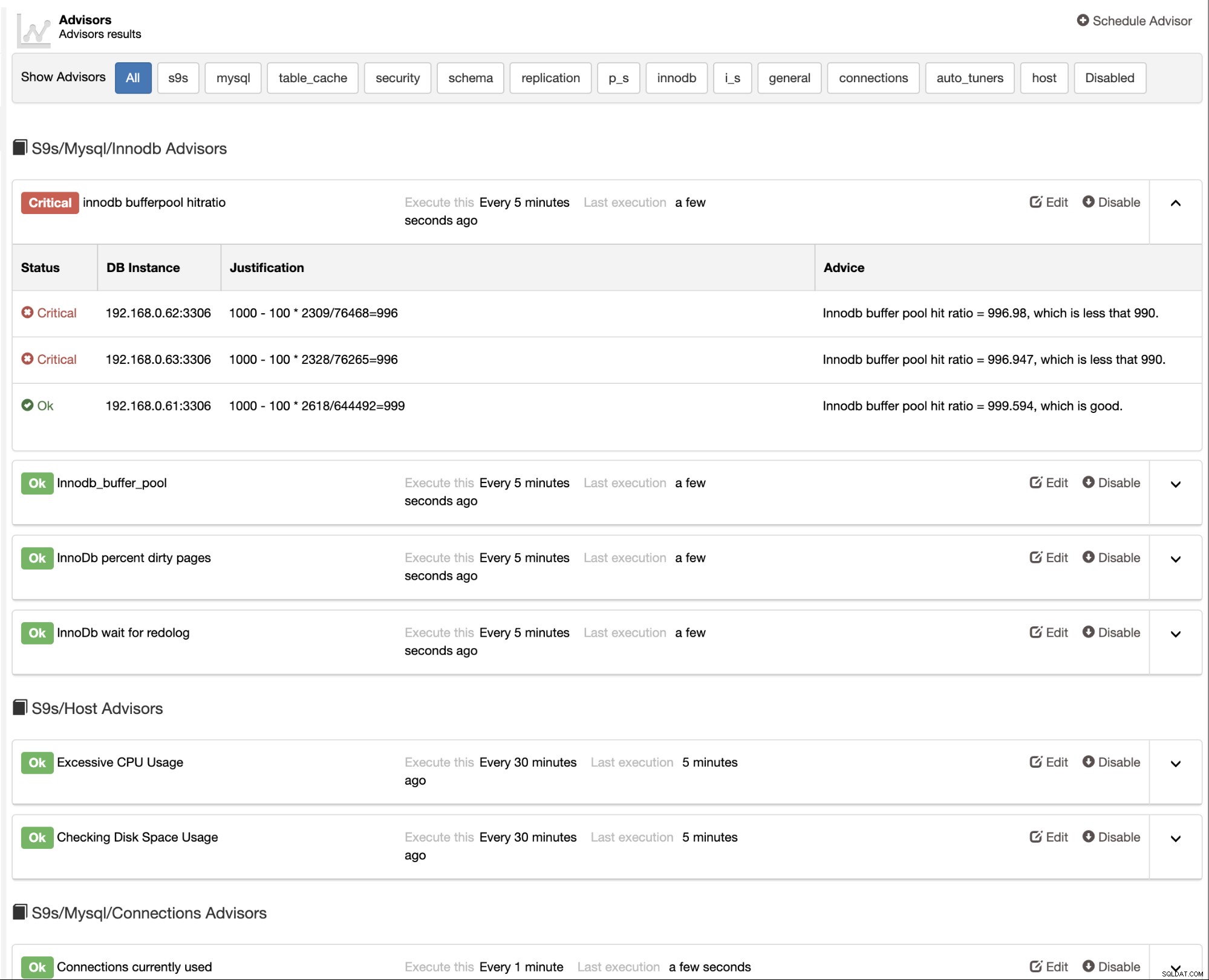
アドバイザーは基本的に、cronのようにスケジュールされたタイミングでClusterControlによって実行されるミニプログラムです。ジョブ。 [アドバイザのスケジュール]ボタンをクリックしてアドバイザをスケジュールし、DeveloperStudioオブジェクトツリーから既存のアドバイザを選択できます。
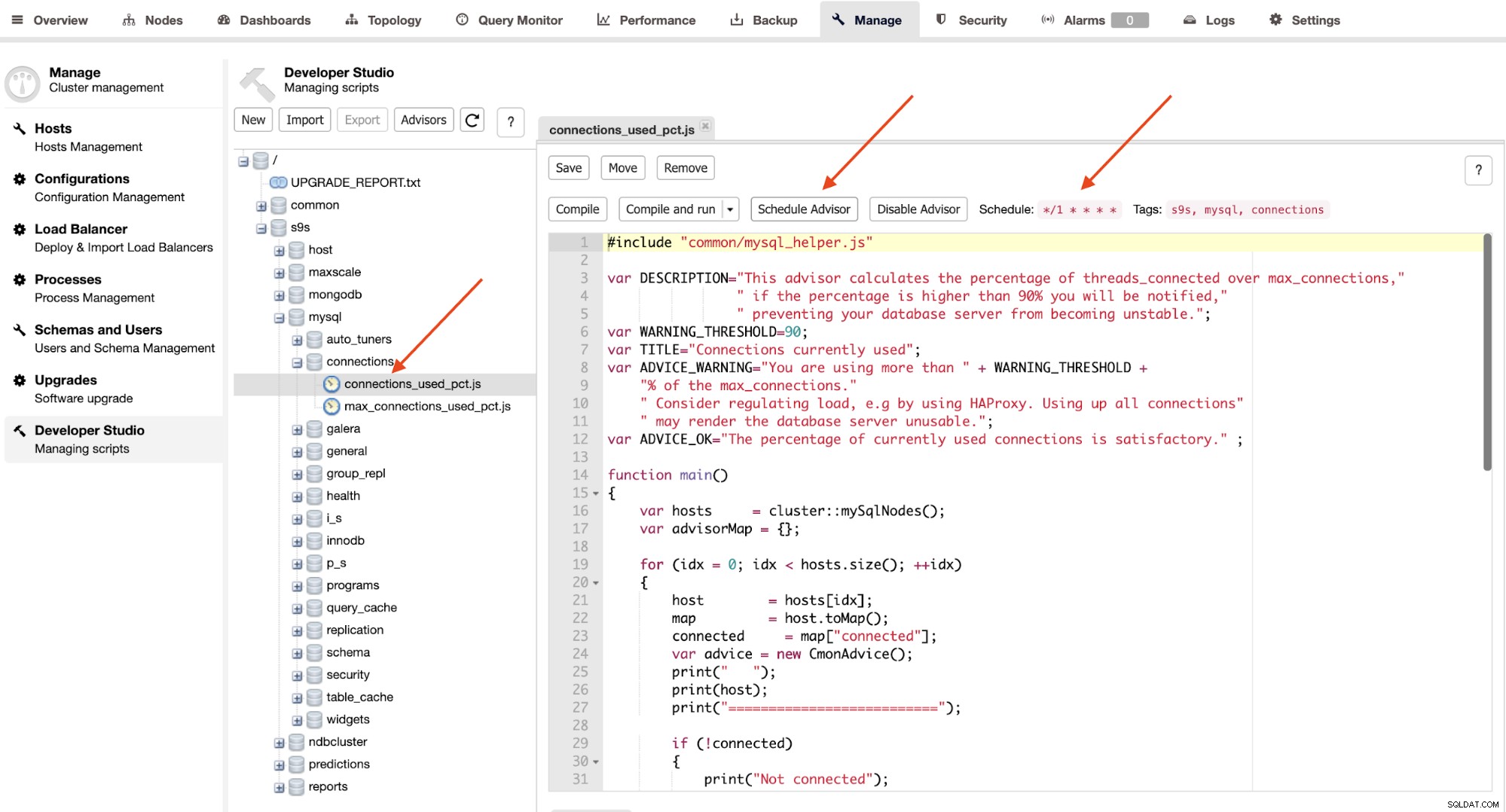
[スケジュールアドバイザー]ボタンをクリックして、スケジュールを設定します。パスとアドバイザーのタグ。 [コンパイルして実行]ボタンをクリックすると、アドバイザをコンパイルして出力をすぐに確認することもできます。その下の[メッセージ]の下に次の出力が表示されます。

この開発者ガイドを参照して、独自のアドバイザーを作成できます。 ClusterControlドメイン固有言語(Javascriptに非常に似ています)、または監視ポリシーに合わせて既存のアドバイザーをカスタマイズします。つまり、ClusterControlの監視義務は、ClusterControlAdvisorsを介して無制限の可能性で拡張できます。