以前のブログでは、スタンドアロンのMoodleセットアップをクラスター化されたデータベースに基づくスケーラブルなセットアップに移行する方法について説明しました。考慮する必要がある次のステップは、フェイルオーバーメカニズムです。データベースサービスがダウンした場合はどうしますか。
バックエンドMoodleデータベースとしてMySQLレプリケーションを使用している場合、データベースサーバーの障害は珍しくありません。発生した場合は、たとえばスタンバイサーバーを次のように昇格させることでトポロジを回復する方法を見つける必要があります。新しいプライマリサーバーになります。 Moodle MySQLデータベースの自動フェイルオーバーがあると、アプリケーションの稼働時間が向上します。フェイルオーバーメカニズムの仕組みと、セットアップに自動フェイルオーバーを組み込む方法について説明します。
MySQLデータベースの高可用性アーキテクチャ
高可用性アーキテクチャは、MySQLデータベースをいくつかの異なる方法でクラスタリングすることで実現できます。 MySQLレプリケーションを使用して、プライマリデータベースに厳密に従う複数のレプリカを設定できます。さらに、データベースロードバランサーを配置して、読み取り/書き込みトラフィックを分割し、トラフィックを読み取り/書き込みノードと読み取り専用ノードに分散できます。 MySQLレプリケーションを使用したデータベースの高可用性アーキテクチャは次のように説明できます:
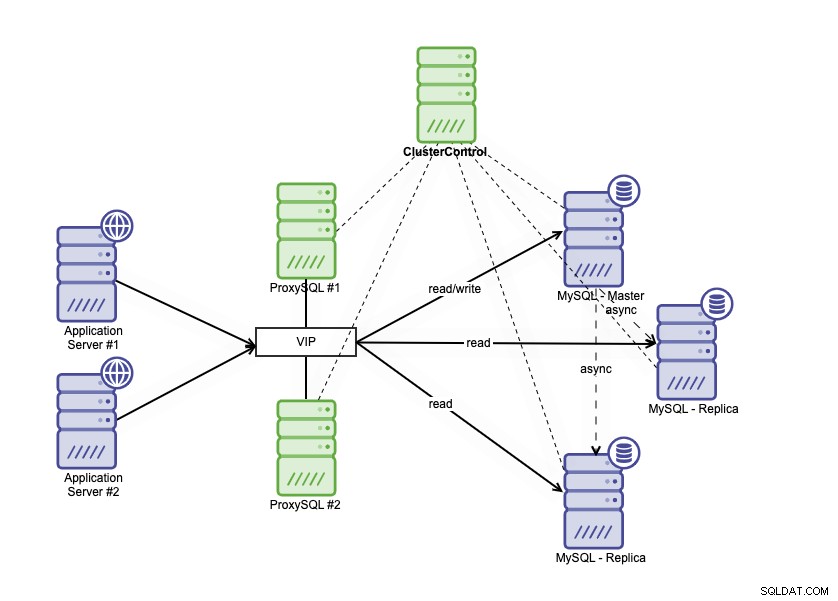
1つのプライマリデータベース、2つのデータベースレプリカ、およびデータベースロードバランサーで構成されます(このブログでは、データベースのロードバランサーとしてProxySQLを使用しています)、ProxySQLプロセスを監視するサービスとしてkeepalivedを使用しています。アプリケーションからの単一の接続として仮想IPアドレスを使用します。トラフィックは、keepalivedのロールフラグに基づいてアクティブなロードバランサーに分散されます。
ProxySQLはトラフィックを分析し、リクエストが読み取りか書き込みかを理解できます。次に、リクエストを適切なホストに転送します。
MySQLレプリケーションのフェイルオーバー
MySQLレプリケーションは、バイナリログを使用してプライマリからレプリカにデータをレプリケートします。レプリカはプライマリノードに接続し、すべての変更が複製され、IO_THREADを介してレプリカノードのリレーログに書き込まれます。変更がリレーログに保存された後、SQL_THREADプロセスはレプリカデータベースへのデータの適用を続行します。
レプリカの1つをプライマリにプロモートし、プロモートされたレプリカの読み取り専用パラメータを無効にして、書き込み可能にする必要があります。また、新しいプライマリに接続するには、他のレプリカを変更する必要があります。 GTIDモードでは、レプリケーションを再開する場所からバイナリログの名前と位置をメモする必要はありません。ただし、従来のbinlogベースのレプリケーションでは、実行する最後のバイナリログ名と位置を確実に知る必要があります。 binlogベースのレプリケーションでのフェイルオーバーは非常に複雑なプロセスですが、GTIDベースのレプリケーションでのフェイルオーバーでさえ、誤ったトランザクションなどに注意する必要があるため、簡単ではありません。障害の検出は1つのことであり、自動化なしでは、短い遅延で障害に対応することはおそらく不可能です。
ClusterControlが自動フェイルオーバーを有効にする方法
ClusterControlには、MoodleMySQLデータベースの自動フェイルオーバーを実行する機能があります。データベースプライマリがクラッシュしたときにフェイルオーバープロセスをトリガーするクラスターおよびノードの自動回復機能があります。
ClusterControlで自動フェイルオーバーがどのように発生するかをシミュレートします。プライマリデータベースをクラッシュさせ、ClusterControlダッシュボードに表示されます。以下は、クラスターの現在のトポロジーです:
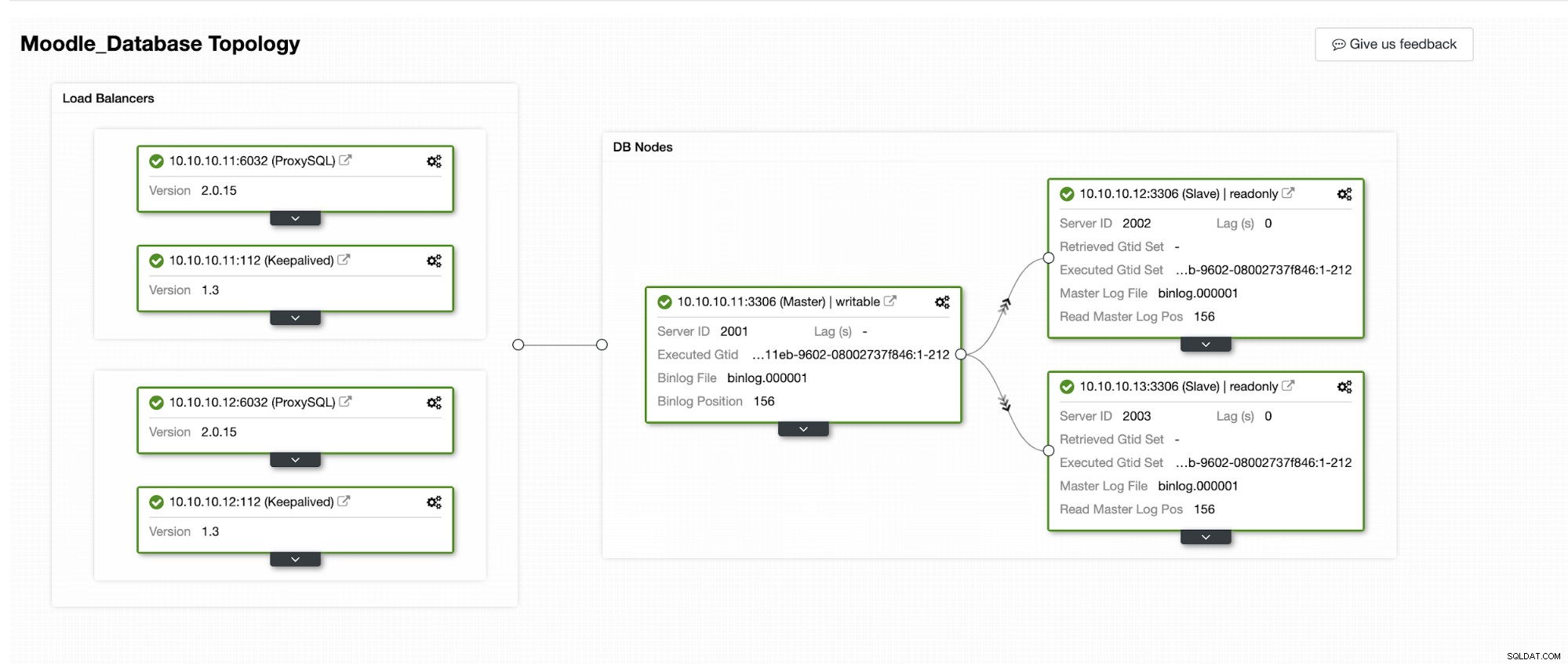
データベースプライマリはIPアドレス10.10.10.11を使用しており、レプリカは次のとおりです。 10.10.10.12および10.10.10.13。プライマリでクラッシュが発生すると、ClusterControlがアラートをトリガーし、次の図に示すようにフェイルオーバーが開始されます。
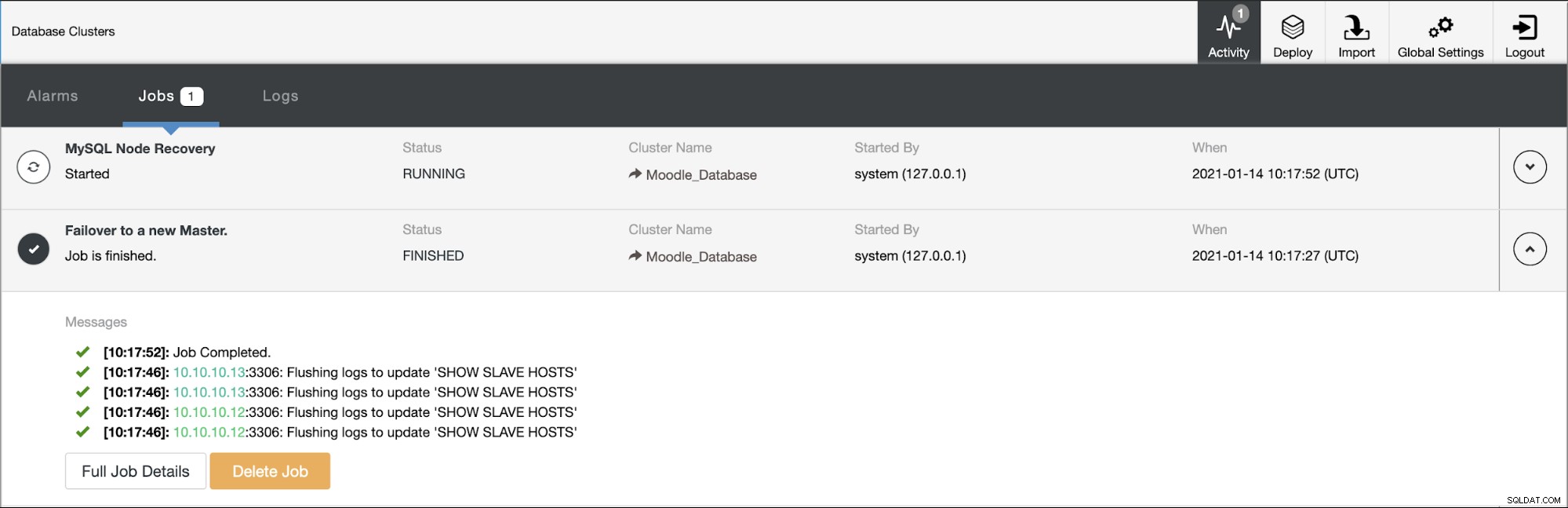
レプリカの1つがプライマリにプロモートされ、トポロジが次のようになります。下の写真:
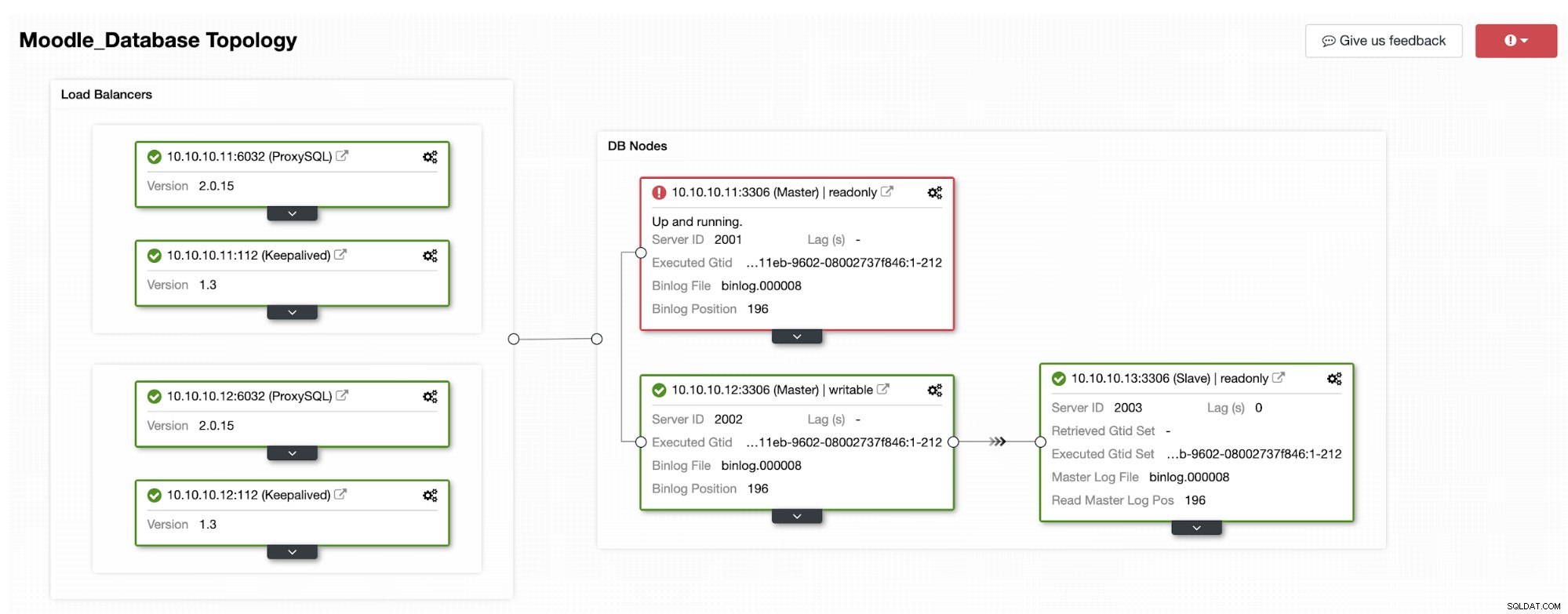
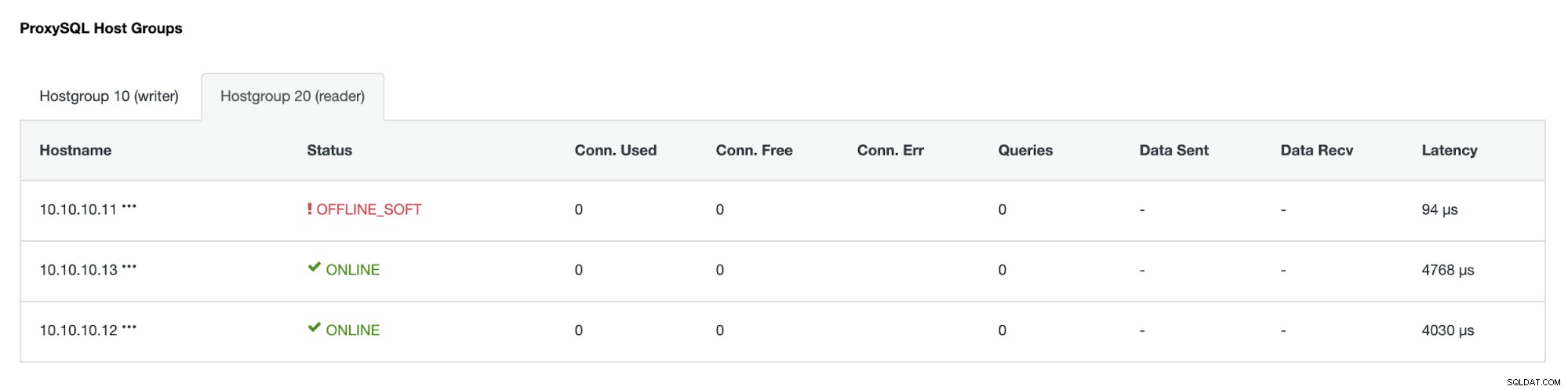
IPアドレス10.10.10.12は、書き込みトラフィックをプライマリとして処理しています。また、IPアドレスが10.10.10.13のレプリカが1つだけ残っています。 ProxySQL側では、プロキシが新しいプライマリを自動的に検出します。ホストグループ(HG10)は、以下に示すように、メンバー10.10.10.12を持つ書き込みトラフィックを引き続き処理します。

ホストグループ(HG20)は引き続き読み取りトラフィックを処理できますが、ご覧のとおりクラッシュのため、ノード10.10.10.11はオフラインです:
障害が発生したプライマリサーバーがオンラインに戻ると、自動的に再起動されることはありません。 -データベーストポロジに導入されました。これは、レプリカとしてノードを再導入すると、一部のログやその他の情報を上書きする必要がある場合があるため、トラブルシューティング情報が失われないようにするためです。ただし、障害が発生したノードの自動再結合を構成することは可能です。