日付と時刻のデータのバケット化には、分析目的で一定の時間間隔を表すグループにデータを編成することが含まれます。多くの場合、入力はテーブルに格納された時系列データであり、行は一定の時間間隔で行われた測定値を表します。たとえば、測定値は5分ごとに取得される温度と湿度の読み取り値であり、1時間ごとのバケットを使用してデータをグループ化し、1時間あたりの平均などの集計を計算する必要があります。時系列データはバケットベースの分析の一般的なソースですが、この概念は、日付と時刻の属性および関連する測定値を含むすべてのデータに同様に関連しています。たとえば、売上データを会計年度バケットに整理し、会計年度ごとの総売上値などの集計を計算したい場合があります。この記事では、日付と時刻のデータをバケット化する2つの方法について説明します。 1つは、DATE_BUCKETという関数を使用しています。この関数は、執筆時点ではAzureSQLEdgeでのみ使用できます。もう1つは、DATE_BUCKET関数をエミュレートするカスタム計算を使用することです。この関数は、SQLServerおよびAzureSQLデータベースの任意のバージョン、エディション、およびフレーバーで使用できます。
私の例では、サンプルデータベースTSQLV5を使用します。 TSQLV5を作成してデータを取り込むスクリプトはここにあり、そのER図はここにあります。
DATE_BUCKET
前述のように、DATE_BUCKET関数は現在AzureSQLEdgeでのみ使用できます。図1に示すように、SQL ServerManagementStudioはすでにIntelliSenseをサポートしています。
 図1:SSMSでのDATE_BUCKETのインテリジェンスサポート
図1:SSMSでのDATE_BUCKETのインテリジェンスサポート
関数の構文は次のとおりです。
DATE_BUCKET(<日付部分>、<バケット幅>、<タイムスタンプ> [、<原点>])入力origin 時間の矢のアンカーポイントを表します。サポートされている任意の日付と時刻のデータ型にすることができます。指定しない場合、デフォルトは1900年1月1日深夜です。次に、タイムラインが原点から始まる個別の間隔に分割されることを想像できます。各間隔の長さは、入力バケット幅に基づいています。 および日付部分 。前者は数量で、後者は単位です。たとえば、タイムラインを2か月単位で整理するには、 2を指定します。 バケット幅として 入力と月 日付部分として 入力。
入力タイムスタンプ は、それを含むバケットに関連付ける必要がある任意の時点です。そのデータ型は、入力 originのデータ型と一致する必要があります 。入力タイムスタンプ キャプチャするメジャーに関連付けられた日付と時刻の値です。
関数の出力は、含まれているバケットの開始点になります。出力のデータ型は、入力のタイムスタンプのデータ型です。 。
まだ明らかでない場合は、通常、DATE_BUCKET関数をクエリのGROUP BY句のグループ化セット要素として使用し、集計されたメジャーとともにSELECTリストにも自然に返します。
関数、その入力、およびその出力についてまだ少し混乱していますか?関数のロジックを視覚的に表現した特定の例が役立つかもしれません。入力変数を使用する例から始め、この記事の後半で、入力テーブルに対するクエリの一部として使用するより一般的な方法を示します。
次の例を考えてみましょう:
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00'; SELECT DATE_BUCKET(month, @bucketwidth, @timestamp, @origin);
関数のロジックの視覚的な描写を図2に示します。
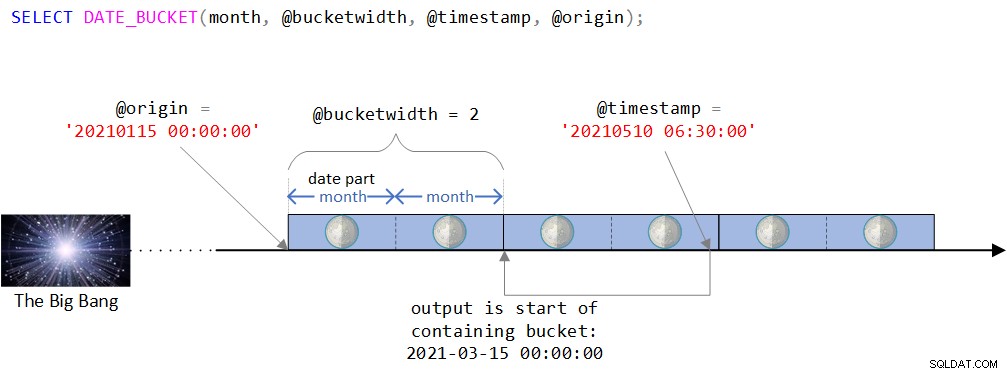 図2:DATE_BUCKET関数のロジックの視覚的描写
図2:DATE_BUCKET関数のロジックの視覚的描写
図2に示されているように、起点は、2021年1月15日の深夜0時のDATETIME2値です。この原点が少し奇妙に思える場合は、通常、ある年の初めやある日の始まりなど、より自然なものを使用することを直感的に感じることができます。実際、デフォルトは1900年1月1日の深夜であることに満足することがよくあります。私は意図的に、より自然なものを使用する場合には関係がないかもしれない特定の複雑さを議論できるように、ささいな原点を使用したかったのです。これについてはまもなく詳しく説明します。
次に、タイムラインは、原点から始まる個別の2か月間隔に分割されます。入力タイムスタンプは、2021年5月10日午前6時30分のDATETIME2値です。
入力タイムスタンプが2021年3月15日午前0時に開始するバケットの一部であることに注意してください。実際、この関数はこの値をDATETIME2タイプの値として返します。
--------------------------- 2021-03-15 00:00:00.0000000
DATE_BUCKETのエミュレート
Azure SQL Edgeを使用していない限り、日付と時刻のデータをバケット化する場合は、当面の間、DATE_BUCKET関数の機能をエミュレートする独自のカスタムソリューションを作成する必要があります。そうすることはそれほど複雑ではありませんが、それほど単純でもありません。日付と時刻のデータを処理するには、多くの場合、注意が必要なトリッキーなロジックと落とし穴が含まれます。
計算を段階的に作成し、前に示したDATE_BUCKETの例で使用したものと同じ入力を使用します。
DECLARE @timestamp AS DATETIME2 = '20210510 06:30:00', @bucketwidth AS INT = 2, @origin AS DATETIME2 = '20210115 00:00:00';
実際にコードを実行するかどうかを示す各コードサンプルの前に、この部分を必ず含めてください。
ステップ1では、DATEDIFF関数を使用して、日付部分の差を計算します。 原点間の単位 およびタイムスタンプ 。この違いをdiff1と呼びます。 。これは次のコードで行われます:
SELECT DATEDIFF(month, @origin, @timestamp) AS diff1;
サンプル入力では、この式は4を返します。
ここで注意が必要なのは、日付部分のユニット全体の数を計算する必要があることです。 originの間に存在する およびタイムスタンプ 。サンプル入力では、2つの間に4か月ではなく3か月あります。DATEDIFF関数が4を報告する理由は、差を計算するときに、入力の要求された部分と上位の部分のみを調べ、下位の部分は調べないためです。 。したがって、月の差を求める場合、関数は入力の年と月の部分のみを考慮し、月より下の部分(日、時、分、秒など)は考慮しません。実際、2021年1月から2021年5月までの間に4か月ありますが、完全な入力の間には3か月しかありません。
ステップ2の目的は、日付部分のユニット全体の数を計算することです。 originの間に存在する およびタイムスタンプ 。この違いをdiff2と呼びます。 。これを実現するために、 diff1を追加できます。 日付部分の単位 起源 。結果がタイムスタンプより大きい場合 、 diff1から1を引きます diff2を計算する 、それ以外の場合は0を引くため、 diff1を使用します diff2として 。これは、次のようにCASE式を使用して実行できます。
SELECT
DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END AS diff2; この式は3を返します。これは、2つの入力間の全体の月数です。
先ほど、私の例では、周期の始まりのような自然な原点ではない原点を意図的に使用したことを思い出してください。これにより、関連する可能性のある特定の複雑さについて話し合うことができます。たとえば、 monthを使用する場合 日付の部分として、ある月の正確な始まり(深夜のある月の1)を起点として、ステップ2をスキップして、 diff1を安全に使用できます。 diff2として 。それは起源だからです + diff1 >タイムスタンプになることはできません このような場合には。ただし、私の目標は、共通であるかどうかに関係なく、任意の起点で正しく機能するDATE_BUCKET関数と論理的に同等の代替手段を提供することです。そのため、例にステップ2のロジックを含めますが、このステップが関係しないケースを特定するときは、CASE式の出力を減算する部分を安全に削除できることを覚えておいてください。
ステップ3では、日付部分のユニット数を特定します。 originの間に存在するバケット全体があります およびタイムスタンプ 。この値をdiff3と呼びます。 。これは、次の式で実行できます。
diff3 = diff2 / <bucket width> * <bucket width>
ここでの秘訣は、整数オペランドを使用するT-SQLで除算演算子/を使用すると、整数除算が得られることです。たとえば、T-SQLの3/2は1であり、1.5ではありません。式diff2/<バケット幅> originの間に存在するバケット全体の数を示します およびタイムスタンプ (この場合は1)。結果にバケット幅を掛けます 次に、日付部分のユニット数を示します。 それらのバケット全体(この場合は2)内に存在します。この式は、T-SQLでは次の式に変換されます。
SELECT
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth AS diff3; この式は2を返します。これは、2つの入力の間に存在する2か月のバケット全体の月数です。
最後のステップであるステップ4で、 diff3を追加します。 日付部分の単位 起源 含まれているバケットの開始を計算します。これを実現するためのコードは次のとおりです。
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); このコードは次の出力を生成します:
--------------------------- 2021-03-15 00:00:00.0000000
ご存知のとおり、これは同じ入力に対してDATE_BUCKET関数によって生成されたものと同じ出力です。
この表現をさまざまな入力やパーツで試してみることをお勧めします。ここではいくつかの例を示しますが、自由に試してみてください。
これがoriginの例です タイムスタンプよりわずかに進んでいます その月に:
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:01';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); このコードは次の出力を生成します:
--------------------------- 2021-03-10 06:30:01.0000000
含まれているバケットの開始は3月であることに注意してください。
これがoriginの例です 月内のタイムスタンプと同じ時点です :
DECLARE
@timestamp AS DATETIME2 = '20210510 06:30:00',
@bucketwidth AS INT = 2,
@origin AS DATETIME2 = '20210110 06:30:00';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
month,
( DATEDIFF(month, @origin, @timestamp)
- CASE
WHEN DATEADD(
month,
DATEDIFF(month, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); このコードは次の出力を生成します:
--------------------------- 2021-05-10 06:30:00.0000000
今回は、含まれているバケットの開始が5月であることに注意してください。
4週間のバケットの例を次に示します。
DECLARE
@timestamp AS DATETIME2 = '20210303 21:22:11',
@bucketwidth AS INT = 4,
@origin AS DATETIME2 = '20210115';
-- SELECT DATE_BUCKET(week, @bucketwidth, @timestamp, @origin);
SELECT DATEADD(
week,
( DATEDIFF(week, @origin, @timestamp)
- CASE
WHEN DATEADD(
week,
DATEDIFF(week, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); コードが週を使用していることに注意してください 今回は別れます。
このコードは次の出力を生成します:
--------------------------- 2021-02-12 00:00:00.0000000
15分のバケットの例を次に示します。
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF(minute, @origin, @timestamp)
- CASE
WHEN DATEADD(
minute,
DATEDIFF(minute, @origin, @timestamp),
@origin) > @timestamp
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin); このコードは次の出力を生成します:
--------------------------- 2021-02-03 21:15:00.0000000
パーツが分であることに注意してください 。この例では、時間の最下部から開始する15分のバケットを使用するため、任意の時間の最下部である起点が機能します。実際、00、15、30、または45の分単位を持ち、下部にゼロがあり、任意の日付と時刻の原点が機能します。したがって、DATE_BUCKET関数が入力 originに使用するデフォルト 動作します。もちろん、カスタム式を使用する場合は、原点について明示的にする必要があります。したがって、DATE_BUCKET関数に共感するために、上記の例のように深夜の基準日を使用できます。
ちなみに、これがソリューションのステップ2をスキップすることが完全に安全である良い例である理由を理解できますか?実際にステップ2をスキップすることを選択した場合は、次のコードが表示されます。
DECLARE
@timestamp AS DATETIME2 = '20210203 21:22:11',
@bucketwidth AS INT = 15,
@origin AS DATETIME2 = '19000101';
-- SELECT DATE_BUCKET(minute, @bucketwidth, @timestamp);
SELECT DATEADD(
minute,
( DATEDIFF( minute, @origin, @timestamp ) ) / @bucketwidth * @bucketwidth,
@origin
); 明らかに、ステップ2が不要な場合、コードは大幅に単純化されます。
日付と時刻のバケットによるデータのグループ化と集計
高度な関数や扱いにくい表現を必要としない日付と時刻のデータをバケット化する必要がある場合があります。たとえば、TSQLV5データベースのSales.OrderValuesビューにクエリを実行し、データを毎年グループ化し、年間の合計注文数と値を計算するとします。明らかに、次のように、YEAR(orderdate)関数をグループ化セット要素として使用するだけで十分です。
USE TSQLV5; SELECT YEAR(orderdate) AS orderyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues GROUP BY YEAR(orderdate) ORDER BY orderyear;
このコードは次の出力を生成します:
orderyear numorders totalvalue ----------- ----------- ----------- 2017 152 208083.99 2018 408 617085.30 2019 270 440623.93
しかし、組織の会計年度ごとにデータをバケット化したい場合はどうでしょうか。一部の組織では、会計、予算、および財務報告の目的で会計年度を使用しており、暦年と一致していません。たとえば、組織の会計年度が10月から9月の会計カレンダーで運用されており、会計年度が終了する暦年で示されているとします。したがって、2018年10月3日に発生したイベントは、2018年10月1日に開始し、2019年9月30日に終了した会計年度に属し、2019年で表されます。
これは、次のようにDATE_BUCKET関数を使用して非常に簡単に実現できます。
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year SELECT YEAR(startofbucket) + 1 AS fiscalyear, COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
そして、これがDATE_BUCKET関数のカスタム論理等価物を使用するコードです:
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19001001'; -- this is Oct 1 of some year
SELECT
YEAR(startofbucket) + 1 AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; このコードは次の出力を生成します:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2017 70 79728.58 2018 370 563759.24 2019 390 622305.40
ここでは、コードをより一般化するためにバケット幅と原点に変数を使用しましたが、常に同じものを使用している場合は、それらを定数に置き換えて、必要に応じて計算を簡略化できます。
上記のわずかなバリエーションとして、会計年度が1暦年の7月15日から次の暦年の7月14日までであり、会計年度の初めが属する暦年で示されているとします。したがって、2018年7月18日に発生したイベントは2018会計年度に属します。2018年7月14日に発生したイベントは2017会計年度に属します。DATE_BUCKET関数を使用すると、次のようになります。
DECLARE @bucketwidth AS INT = 1, @origin AS DATETIME2 = '19000715'; -- July 15 marks start of fiscal year SELECT YEAR(startofbucket) AS fiscalyear, -- no need to add 1 here COUNT(*) AS numorders, SUM(val) AS totalvalue FROM Sales.OrderValues CROSS APPLY ( VALUES( DATE_BUCKET( year, @bucketwidth, orderdate, @origin ) ) ) AS A(startofbucket) GROUP BY startofbucket ORDER BY startofbucket;
コメントで前の例と比較した変更を確認できます。
そして、DATE_BUCKET関数と同等のカスタム論理を使用したコードは次のとおりです。
DECLARE
@bucketwidth AS INT = 1,
@origin AS DATETIME2 = '19000715';
SELECT
YEAR(startofbucket) AS fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
DATEADD(
year,
( DATEDIFF(year, @origin, orderdate)
- CASE
WHEN DATEADD(
year,
DATEDIFF(year, @origin, orderdate),
@origin) > orderdate
THEN 1
ELSE 0
END ) / @bucketwidth * @bucketwidth,
@origin) ) ) AS A(startofbucket)
GROUP BY startofbucket
ORDER BY startofbucket; このコードは次の出力を生成します:
fiscalyear numorders totalvalue ----------- ----------- ----------- 2016 8 12599.88 2017 343 495118.14 2018 479 758075.20
明らかに、特定の場合に使用できる代替方法があります。会計年度が10月から9月までで、会計年度が終了する暦年で示される最後の前の例を取り上げます。このような場合、次のはるかに単純な式を使用できます。
YEAR(orderdate) + CASE WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1 ELSE 0 END
そして、クエリは次のようになります:
SELECT
fiscalyear,
COUNT(*) AS numorders,
SUM(val) AS totalvalue
FROM Sales.OrderValues
CROSS APPLY ( VALUES(
YEAR(orderdate)
+ CASE
WHEN MONTH(orderdate) BETWEEN 10 AND 12 THEN 1
ELSE 0
END ) ) AS A(fiscalyear)
GROUP BY fiscalyear
ORDER BY fiscalyear; ただし、より多くの場合に機能し、パラメーター化できる一般化されたソリューションが必要な場合は、当然、より一般的な形式を使用することをお勧めします。 DATE_BUCKET関数にアクセスできる場合、それはすばらしいことです。そうでない場合は、カスタムの論理的等価物を使用できます。
結論
DATE_BUCKET関数は、日付と時刻のデータをバケット化できる非常に便利な関数です。時系列データの処理だけでなく、日付と時刻の属性を含むデータのバケット化にも役立ちます。この記事では、DATE_BUCKET関数がどのように機能するかを説明し、使用しているプラットフォームがDATE_BUCKET関数をサポートしていない場合に備えて、同等のカスタム論理を提供しました。