SQLAlchemyは、Pythonでデータベースを操作するのに役立ちます。この投稿では、このモジュールを開始するために知っておく必要のあるすべてのことを説明します。
前回の記事では、ETLプロセスでPythonを使用する方法について説明しました。ストアドプロシージャとSQLクエリを実行して作業を完了することに重点を置きました。この記事と次の記事では、別のアプローチを使用します。 SQLコードを記述する代わりに、SQLAlchemyツールキットを使用します。 SQLAlchemyのインストールと使用の簡単な紹介として、この記事を個別に使用することもできます。
準備?始めましょう。
SQLAlchemyとは何ですか?
Pythonは、その数と多様なモジュールでよく知られています。これらのモジュールは、特定のタスクを実行するために必要なルーチンを実装しているため、コーディング時間を大幅に短縮します。 SQLAlchemyなど、データを処理する多数のモジュールを利用できます。
SQLAlchemyを説明するために、SQLAlchemy.orgからの引用を使用します:
SQLAlchemyは、PythonSQLツールキットおよびオブジェクトリレーショナルマッパーであり、アプリケーション開発者にSQLの完全な機能と柔軟性を提供します。
これは、よく知られているエンタープライズレベルの永続性の完全なスイートを提供します。効率的で高性能なデータベースアクセス用に設計されたパターンは、シンプルでPythonicのドメイン言語に適合しています。
ここで最も重要な部分は、ORM(オブジェクトリレーショナルマッパー)についてのビットです。これは、データベースオブジェクトをリストではなくPythonオブジェクトとして扱うのに役立ちます。
SQLAlchemyをさらに進める前に、一時停止してORMについて話しましょう。
ORMを使用することの長所と短所
生のSQLと比較すると、ORMには長所と短所があります。これらのほとんどはSQLAlchemyにも当てはまります。
良いもの:
- コードの移植性。 ORMは、データベース間の構文上の違いを処理します。
- 1つの言語のみ データベースを処理するために必要です。ただし、正直なところ、これがORMを使用する主な動機となることはありません。
- ORMはコードを簡素化します 、例:彼らは関係を処理し、それらをオブジェクトのように扱います。これは、OOPに慣れている場合に最適です。
- プログラム内でデータを操作することができます 。
残念ながら、すべてに代償が伴います。 ORMに関するあまり良くないこと:
- 場合によっては、ORMが遅くなる可能性があります 。
- 複雑なクエリの作成 さらに複雑になるか、クエリが遅くなる可能性があります。ただし、SQLAlchemyを使用する場合はそうではありません。
- DBMSをよく知っている場合は、ORMで同じものを作成する方法を学ぶのは時間の無駄です。
そのトピックを処理したので、SQLAlchemyに戻りましょう。
始める前に...
…この記事の目的を思い出してみましょう。 SQLAlchemyのインストールに興味があり、簡単なコマンドを実行する方法についての簡単なチュートリアルが必要な場合は、この記事でそれを実行できます。ただし、この記事で紹介するコマンドは、次の記事でETLプロセスを実行し、前の記事で紹介したSQL(ストアドプロシージャ)とPythonコードを置き換えるために使用されます。
では、SQLAlchemyのインストールから始めましょう。
SQLAlchemyのインストール
1。モジュールがすでにインストールされているかどうかを確認します
Pythonモジュールを使用するには、それをインストールする必要があります(つまり、以前にインストールされていなかった場合)。インストールされているモジュールを確認する1つの方法は、Pythonシェルで次のコマンドを使用することです。
help('modules')
特定のモジュールがインストールされているかどうかを確認するには、そのモジュールをインポートしてみてください。次のコマンドを使用します:
import sqlalchemy sqlalchemy.__version__
SQLAlchemyがすでにインストールされている場合、最初の行は正常に実行されます。 import モジュールのインポートに使用される標準のPythonコマンドです。モジュールがインストールされていない場合、Pythonはエラー(実際にはエラーのリストを赤いテキストで表示)をスローしますが、見逃すことはできません:)
2番目のコマンドは、SQLAlchemyの現在のバージョンを返します。返される結果を以下に示します。

別のモジュールも必要になります。それがPyMySQL 。これは、純粋なPythonの軽量MySQLクライアントライブラリです。このモジュールは、単純なクエリの実行からより複雑なデータベースアクションまで、MySQLデータベースでの作業に必要なすべてをサポートします。 help('modules')を使用して存在するかどうかを確認できます 、前述のように、または次の2つのステートメントを使用します。
import pymysql pymysql.__version__
もちろん、これらはSQLAlchemyがインストールされているかどうかをテストするために使用したコマンドと同じです。
SQLAlchemyまたはPyMySQLがまだインストールされていない場合はどうなりますか?
以前にインストールしたモジュールをインポートするのは難しくありません。しかし、必要なモジュールがまだインストールされていない場合はどうなりますか?
一部のモジュールにはインストールパッケージがありますが、ほとんどの場合、pipコマンドを使用してインストールします。 PIPは、モジュールのインストールとアンインストールに使用されるPythonツールです。モジュールを(Windows OSで)インストールする最も簡単な方法は次のとおりです。
- Command Prompt-> Run-> cmdを使用します 。
- Pythonディレクトリへの位置cdC:\ ... \ Python \ Python37 \ Scripts 。
- コマンドpip
installを実行します (この場合、pip install pyMySQLを実行します およびpip install sqlAlchemy。
PIPを使用して、既存のモジュールをアンインストールすることもできます。これを行うには、pip uninstall を使用する必要があります 。
2。データベースへの接続
SQLAlchemyを使用するために必要なすべてのものをインストールすることは不可欠ですが、それほど興味深いものではありません。また、それは私たちが興味を持っていることの一部でもありません。使用したいデータベースに接続していません。今すぐ解決します:
import sqlalchemy
from sqlalchemy.engine import create_engine
engine_live = sqlalchemy.create_engine('mysql+pymysql://:@localhost:3306/subscription_live')
connection_live = engine_live.connect()
print(engine_live.table_names())
上記のスクリプトを使用して、ローカルサーバーにあるデータベース subset_liveへの接続を確立します。 データベース。
(注:
コマンドごとにスクリプトを見ていきましょう。
import sqlalchemy from sqlalchemy.engine import create_engine
これらの2行は、モジュールとcreate_engineをインポートします 機能。
次に、サーバー上にあるデータベースへの接続を確立します。
engine_live = sqlalchemy.create_engine('mysql+pymysql:// :@localhost:3306/subscription_live')
connection_live = engine_live.connect()
create_engine関数はエンジンを作成し、.connect()を使用します 、データベースに接続します。 create_engine 関数は次のパラメータを使用します:
dialect+driver://username:password@host:port/database
この場合、方言はmysqlです。 、ドライバーはpymysqlです (以前にインストールされた)残りの変数は、接続するサーバーとデータベースに固有です。
(注: ローカルに接続している場合は、localhostを使用します 「ローカル」IPアドレスの代わりに、127.0.0.1 および適切なポート:3306 。)

コマンドprint(engine_live.table_names())の結果 上の写真に示されています。予想どおり、運用/ライブデータベースからすべてのテーブルのリストを取得しました。
3。 SQLAlchemyを使用したSQLコマンドの実行
このセクションでは、最も重要なSQLコマンドを分析し、テーブル構造を調べて、SELECT、INSERT、UPDATE、およびDELETEの4つのDMLコマンドすべてを実行します。
このスクリプトで使用されるステートメントについては、個別に説明します。このスクリプトの接続部分はすでに完了しており、テーブル名はすでにリストされていることに注意してください。この行には小さな変更があります:
from sqlalchemy import create_engine, select, MetaData, Table, asc
使用するすべてのものをSQLAlchemyからインポートしました。
テーブルと構造
Pythonシェルで次のコマンドを入力して、スクリプトを実行します。
import os
file_path = 'D://python_scripts'
os.chdir(file_path)
exec(open("queries.py").read())
結果は実行されたスクリプトです。それでは、スクリプトの残りの部分を分析しましょう。
SQLAlchemyは、テーブル、構造、およびリレーションに関連する情報をインポートします。その情報を操作するには、データベース内のテーブル(およびその列)のリストを確認すると便利な場合があります。
#print connected tables
print("\n -- Tables from _live database -- ")
print (engine_live.table_names())

これは、接続されたデータベースからすべてのテーブルのリストを返すだけです。
注: table_names() メソッドは、指定されたエンジンのテーブル名のリストを返します。リスト全体を印刷することも、ループを使用してリストを反復処理することもできます(他のリストの場合と同じように)。
次に、選択したテーブルのすべての属性のリストを返します。スクリプトの関連部分と結果を以下に示します。
#SELECT
metadata = MetaData(bind=None)
table_city = Table('city', metadata, autoload = True, autoload_with = engine_live)
# print table columns
print("\n -- Tables columns for table 'city' --")
for column in table_city.c:
print(column.name)
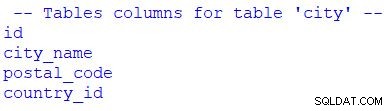
forを使用したことがわかります 結果セットをループします。 table_city.cを置き換えることができます table_city.columnsを使用 。
注: データベース記述をロードし、SQLAlchemyでメタデータを作成するプロセスは、リフレクションと呼ばれます。
注: MetaDataは、データベース内のオブジェクトに関する情報を保持するオブジェクトであるため、データベース内のテーブルもこのオブジェクトにリンクされています。一般に、このオブジェクトはデータベーススキーマがどのように見えるかに関する情報を格納します。 DBスキーマに変更を加えたり、DBスキーマに関する事実を入手したりする場合は、単一の連絡先として使用します。
注: 属性autoload = True およびautoload_with = engine_live テーブル属性がアップロードされるようにするために使用する必要があります(まだアップロードされていない場合)。
SELECT
SELECTステートメントの重要性を説明する必要はないと思います:)つまり、SQLAlchemyを使用してSELECTステートメントを記述できるとしましょう。 MySQL構文に慣れている場合は、適応するのに少し時間がかかります。それでも、すべてがかなり論理的です。簡単に言うと、SELECTステートメントはスライスされ、一部が省略されていますが、すべてが同じ順序のままです。
ここで、いくつかのSELECTステートメントを試してみましょう。
# simple select
print("\n -- SIMPLE SELECT -- ")
stmt = select([table_city])
print(stmt)
print(connection_live.execute(stmt).fetchall())
# loop through results
results = connection_live.execute(stmt).fetchall()
for result in results:
print(result)
最初のステートメントは単純なSELECTステートメントです。 指定されたテーブルからすべての値を返します。このステートメントの構文は非常に単純です。テーブルの名前をselect()に配置しました。 。私がしたことに注意してください:
- ステートメントを準備しました-
stmt = select([table_city]。 -
print(stmt)を使用してステートメントを印刷しました 、実行されたばかりのステートメントについての良いアイデアが得られます。これはデバッグにも使用できます。 - 結果を
print(connection_live.execute(stmt).fetchall())で出力しました 。 - 結果をループして、各レコードを印刷しました。
注: 主キーと外部キーの制約もSQLAlchemyにロードしたため、SELECTステートメントはテーブルオブジェクトのリストを引数として受け取り、必要に応じて関係を自動的に確立します。
結果を下の図に示します:

Pythonはテーブルからすべての属性をフェッチし、それらをオブジェクトに格納します。示されているように、このオブジェクトを使用して追加の操作を実行できます。ステートメントの最終結果は、city テーブル。
これで、より複雑なクエリの準備が整いました。 ORDERBY句を追加しました 。
# simple select
# simple select, using order by
print("\n -- SIMPLE SELECT, USING ORDER BY")
stmt = select([table_city]).order_by(asc(table_city.columns.id))
print(stmt)
print(connection_live.execute(stmt).fetchall())

注: asc() メソッドは、定義された列をパラメーターとして使用して、親オブジェクトに対して昇順の並べ替えを実行します。
返されるリストは同じですが、ID値で昇順でソートされるようになりました。 .order_by(を追加しただけであることに注意してください。 前のSELECTクエリに。 .order_by(...) メソッドを使用すると、SQLクエリで使用するのと同じ方法で、返される結果セットの順序を変更できます。したがって、パラメータは、列名または列の順序とASCまたはDESCを使用して、SQLロジックに従う必要があります。
次に、WHEREを追加します SELECTステートメントに。
# select with WHERE
print("\n -- SELECT WITH WHERE --")
stmt = select([table_city]).where(table_city.columns.city_name == 'London')
print(stmt)
print(connection_live.execute(stmt).fetchall())

注: .where() メソッドは、引数として使用した条件をテストするために使用されます。 .filter()を使用することもできます より複雑な条件のフィルタリングに適したメソッド。
もう一度、.where 一部は、SELECTステートメントに単純に連結されます。条件を角かっこで囲んでいることに注意してください。括弧内の条件はすべて、SELECTステートメントのWHERE部分でテストされるのと同じ方法でテストされます。等式条件は、=の代わりに==を使用してテストされます。
SELECTで最後に試すのは、2つのテーブルを結合することです。まず、コードとその結果を見てみましょう。
# select with JOIN
print("\n -- SELECT WITH JOIN --")
table_country = Table('country', metadata, autoload = True, autoload_with = engine_live)
stmt = select([table_city.columns.city_name, table_country.columns.country_name]).select_from(table_city.join(table_country))
print(stmt)
print(connection_live.execute(stmt).fetchall())

上記のステートメントには2つの重要な部分があります:
-
select([table_city.columns.city_name, table_country.columns.country_name])結果で返される列を定義します。 -
.select_from(table_city.join(table_country))結合条件/テーブルを定義します。キーを含む完全な結合条件を書き留める必要がないことに注意してください。これは、主キーと外部キーのルールがバックグラウンドでインポートされるため、SQLAlchemyがこれら2つのテーブルがどのように結合されるかを「認識」しているためです。
挿入/更新/削除
これらは、この記事で取り上げる残りの3つのDMLコマンドです。それらの構造は非常に複雑になる可能性がありますが、これらのコマンドは通常、はるかに単純です。使用したコードを以下に示します。
# INSERT
print("\n -- INSERT --")
stmt = table_country.insert().values(country_name='USA')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# UPDATE
print("\n -- UPDATE --")
stmt = table_country.update().where(table_country.columns.country_name == 'USA').values(country_name = 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
# DELETE
print("\n -- DELETE --")
stmt = table_country.delete().where(table_country.columns.country_name == 'United States of America')
print(stmt)
connection_live.execute(stmt)
# check & print changes
stmt = select([table_country]).order_by(asc(table_country.columns.id))
print(connection_live.execute(stmt).fetchall())
3つのステートメントすべてに同じパターンが使用されます。ステートメントの準備、印刷と実行、各ステートメントの後に結果を印刷して、データベースで実際に何が起こったかを確認できるようにします。ステートメントの一部がオブジェクト(.values()、。where())として扱われたことにもう一度注意してください。

今後の記事でこの知識を使用して、SQLAlchemyを使用してETLスクリプト全体を構築します。
次へ:ETLプロセスのSQLAlchemy
今日は、SQLAlchemyを設定する方法と簡単なDMLコマンドを実行する方法を分析しました。次の記事では、この知識を使用して、SQLAlchemyを使用した完全なETLプロセスを記述します。
この記事で使用されている完全なスクリプトをここからダウンロードできます。