Pythonは最近非常に人気があります。 Pythonは汎用プログラミング言語であるため、抽出、変換、読み込み(ETL)プロセスの実行にも使用できます。さまざまなETLモジュールを利用できますが、今日はPythonとMySQLの組み合わせを使用します。 Pythonを使用してストアドプロシージャを呼び出し、SQLステートメントを準備して実行します。
2つの類似しているが異なるアプローチを使用します。最初に、ジョブ全体を実行するストアドプロシージャを呼び出し、その後、PythonでMySQLコードを使用して、ストアドプロシージャなしで同じプロセスを実行する方法を分析します。
準備?掘り下げる前に、データモデル、またはこの記事に2つあるデータモデルを見てみましょう。
データモデル
2つのデータモデルが必要です。1つは運用データを保存するためのもので、もう1つはレポートデータを保存するためのものです。
最初のモデルは上の写真に示されています。このモデルは、サブスクリプションベースのビジネスの運用(ライブ)データを保存するために使用されます。このモデルの詳細については、前回の記事「DWHの作成、パート1:サブスクリプションビジネスデータモデル」をご覧ください。
運用データとレポートデータを分離することは、通常、非常に賢明な決定です。その分離を実現するには、データウェアハウス(DWH)を作成する必要があります。私たちはすでにそれをしました。上の写真でモデルを見ることができます。このモデルについては、「DWHの作成、パート2:サブスクリプションビジネスデータモデル」の投稿でも詳しく説明されています。
最後に、ライブデータベースからデータを抽出して変換し、DWHにロードする必要があります。これは、SQLストアドプロシージャを使用してすでに行っています。達成したいことの説明といくつかのコード例は、データウェアハウスの作成、パート3:サブスクリプションビジネスデータモデルにあります。
DWHに関する追加情報が必要な場合は、次の記事を読むことをお勧めします。
- スタースキーマ
- スノーフレークスキーマ
- スタースキーマとスノーフレークスキーマ。
今日の私たちの仕事は、SQLストアドプロシージャをPythonコードに置き換えることです。 Pythonの魔法をかける準備ができました。 Pythonでストアドプロシージャのみを使用することから始めましょう。
方法1:ストアドプロシージャを使用したETL
プロセスの説明を始める前に、サーバー上に2つのデータベースがあることを言及することが重要です。
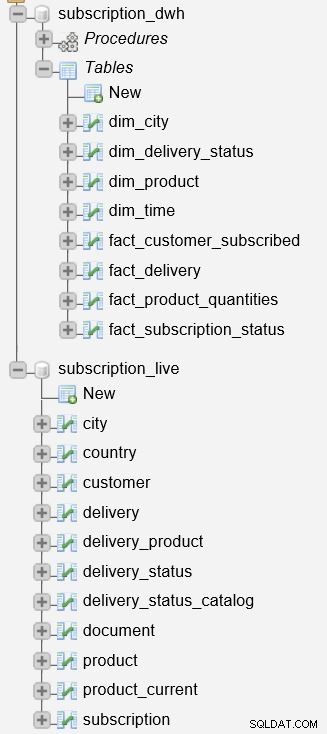
subscription_live データベースはトランザクション/ライブデータを保存するために使用され、subscription_dwh はレポートデータベース(DWH)です。
ディメンションテーブルとファクトテーブルを更新するために使用されるストアドプロシージャについては、すでに説明しました。 subscription_live データベース、subscription_dwh データベースを作成し、新しいデータをsubscription_dwh データベース。これらの2つの手順は次のとおりです。
-
p_update_dimensions–ディメンションテーブルを更新しますdim_timeおよびdim_city。 -
p_update_facts–2つのファクトテーブルfact_customer_subscribedおよびfact_subscription_status。
これらの手順の完全なコードを確認したい場合は、データウェアハウスの作成、パート3:サブスクリプションビジネスデータモデルをお読みください。
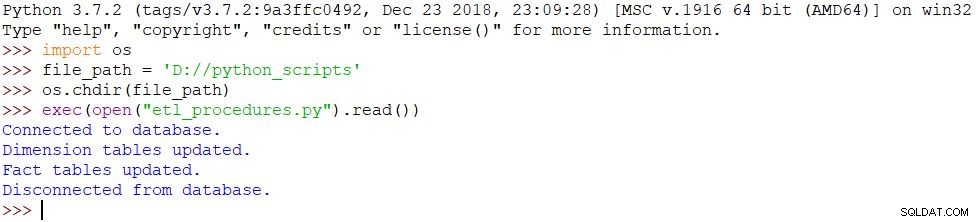
これで、サーバーに接続してETLプロセスを実行する簡単なPythonスクリプトを作成する準備が整いました。まず、スクリプト全体( etl_procedures.py )を見てみましょう。 )。次に、最も重要な部分について説明します。
#import MySQL Connectorimport mysql.connector#connect to serverconnection =mysql.connector.connect(user =''、password =' '、host ='127.0.0.1')print('Connected to database。')cursor =connection.cursor()#私はdimensionscursor.callproc(' subscription_dwh.p_update_dimensions')print('ディメンションテーブルが更新されました。テーブルが更新されました。')#commit&close connectioncursor.close()connection.commit()connection.close()print(' Disconnected from database。')
etl_procedures.py
モジュールのインポートとデータベースへの接続
Pythonは、モジュールを使用して定義とステートメントを格納します。既存のモジュールを使用することも、独自のモジュールを作成することもできます。事前に作成されたコードを使用しているため、既存のモジュールを使用すると作業が簡素化されますが、独自のモジュールを作成することも非常に便利です。 Pythonインタープリターを終了して再度実行すると、以前に定義した関数と変数が失われます。もちろん、同じコードを何度も入力する必要はありません。これを回避するには、定義をモジュールに保存してPythonにインポートします。
etl_procedures.pyに戻る 。私たちのプログラムでは、MySQLコネクタのインポートから始めます:
#import MySQL Connectorimport mysql.connector
Python用のMySQLコネクタは、MySQLサーバー/データベースに接続する標準化されたドライバとして使用されます。以前に行ったことがない場合は、ダウンロードしてインストールする必要があります。データベースへの接続に加えて、データベースを操作するための多くのメソッドとプロパティを提供します。それらの一部を使用しますが、完全なドキュメントはここで確認できます。
次に、データベースに接続する必要があります:
#connect to serverconnection =mysql.connector.connect(user =''、password =' '、host ='127.0.0.1')print('Connected to database。')cursor =connection .cursor()
最初の行は、資格情報(
connection =mysql.connector.connect(user =''、password =' '、host ='127.0.0.1'、database =' ')
同じサーバー上にある2つのデータベースを使用するため、意図的にサーバーにのみ接続し、特定のデータベースには接続していません。
次のコマンド– print –ここでは、接続に成功したことを通知します。プログラミング上の重要性はありませんが、スクリプトで問題が発生した場合にコードをデバッグするために使用できます。
この部分の最後の行は次のとおりです。
cursor =connection.cursor()
カーソルは、データの操作に使用されるハンドラー構造です。これらは、データベースからデータを取得するため(SELECT)だけでなく、データを変更するため(INSERT、UPDATE、DELETE)にも使用します。カーソルを使用する前に、カーソルを作成する必要があります。そして、それがこの行の役割です。
呼び出し手順
前の部分は一般的であり、他のデータベース関連のタスクに使用できます。コードの次の部分は、特にETL用です。cursor.callprocを使用してストアドプロシージャを呼び出す 指図。次のようになります:
#1。dimensionscursor.callproc('subscription_dwh.p_update_dimensions')print('ディメンションテーブルが更新されました。')#2。factscursor.callproc('subscription_dwh.p_update_facts')print('ファクトテーブルが更新されました。')<を更新します。 / pre>プロシージャの呼び出しはほとんど自明です。各呼び出しの後に、印刷コマンドが追加されました。繰り返しになりますが、これはすべてが正常に行われたことを通知するだけです。
コミットして閉じる
スクリプトの最後の部分は、データベースの変更をコミットし、使用されているすべてのオブジェクトを閉じます。
#commit&close connectioncursor.close()connection.commit()connection.close()print('データベースから切断されました。')プロシージャの呼び出しはほとんど自明です。各呼び出しの後に、印刷コマンドが追加されました。繰り返しになりますが、これはすべてが正常に行われたことを通知するだけです。
ここではコミットが不可欠です。これがないと、プロシージャを呼び出したりSQLステートメントを実行したりしても、データベースに変更はありません。
スクリプトの実行
最後に行う必要があるのは、スクリプトを実行することです。これを実現するために、Pythonシェルで次のコマンドを使用します。
import osfile_path ='D://python_scripts' os.chdir(file_path)exec(open( "etl_procedures.py")。read())スクリプトが実行され、それに応じてすべての変更がデータベースで行われます。結果は下の写真で見ることができます。
方法2:PythonとMySQLを使用したETL
上記のアプローチは、MySQLで直接ストアドプロシージャを呼び出すアプローチと大差ありません。唯一の違いは、すべての作業を実行するスクリプトがあることです。
別のアプローチを使用することもできます。すべてをPythonスクリプト内に配置することです。 Pythonステートメントを含めますが、SQLクエリを準備し、データベースで実行します。ソースデータベース(ライブ)と宛先データベース(DWH)は、ストアドプロシージャを使用した例と同じです。
これについて詳しく説明する前に、完全なスクリプト( etl_queries.py )を見てみましょう。 ):
from datetime import date#import MySQL Connectorimport mysql.connector#connect to serverconnection =mysql.connector.connect(user =''、password =' '、host ='127.0.0.1')print ('データベースに接続しました。')#1。ディメンションの更新#1.1更新dim_time#date-yesterdayyesterday =date.fromordinal(date.today()。toordinal()-1)yesterday_str ='"' + str(yesterday)+ ' "'#日付がすでにテーブルにあるかどうかをテストcursor =connection.cursor()query =(" SELECT COUNT(*) "" FROM Subscription_dwh.dim_time "" WHERE time_date ="+ yesterday_str)cursor.execute(query)result =cursor .fetchall()yesterday_subscription_count =int(result [0] [0])if yesterday_subscription_count ==0:yesterday_year ='YEAR( "'+ str(yesterday)+'")' yesterday_month ='MONTH( "'+ str(yesterday )+'")' yesterday_week ='WEEK("' + str(yesterday)+'")' yesterday_weekday ='WEEKDAY("' + str(yesterday)+'")' query =(" INSERT INTO Subscription_dwh.`dim_time `(` time_date`、 `time_year`、` time_month`、 `time_week` 、` time_weekday`、` ts`) "" VALUES( "+ yesterday_str +"、 "+ yesterday_year +"、 "+ yesterday_month +"、 "+ yesterday_week +"、 "+ yesterday_weekday +"、Now()) ")カーソル.execute(query)#1.2 update dim_cityquery =( "INSERT INTO Subscription_dwh.`dim_city`(` city_name`、 `postal_code`、` country_name`、 `ts`)" "SELECT city_live.city_name、city_live.postal_code、country_live.country_name 、Now() "" FROM Subscription_live.city city_live "" INNER JOIN Subscription_live.country country_live ON city_live.country_id =country_live.id "" LEFT JOIN Subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =postal_code AND country_live.country_name =city_dwh.country_name "" WHERE city_dwh.id IS NULL ")cursor.execute(query)print('ディメンションテーブルが更新されました。')#2。更新されたファクト#2.1サブスクライブされた顧客の更新# same datequery =("DELETEsubscription_dwh.`fact_customer_subscribed`。*""FROMsubscription_dwh.`fa ct_customer_subscribed` "" INNER JOIN Subscription_dwh.`dim_time` ON Subscription_dwh.`fact_customer_subscribed`.`dim_time_id` =Subscription_dwh.`dim_time`.`id` "" WHERE Subscription_dwh.`dim_time`.`time_date` ="+ yesterday_str execute(query)#insert new dataquery =( "INSERT INTO Subscription_dwh.`fact_customer_subscribed`(` dim_city_id`、 `dim_time_id`、` total_active`、 `total_inactive`、` daily_new`、 `daily_canceled`、` ts`) "" SELECT city_dwh.id AS dim_ctiy_id、time_dwh.id AS dim_time_id、SUM(CASE WHEN customer_live.active =1 THEN 1 ELSE 0 END)AS total_active、SUM(CASE WHEN customer_live.active =0 THEN 1 ELSE 0 END)AS total_inactive、SUM( CASE WHEN customer_live.active =1 AND DATE(customer_live.time_updated)=@time_date THEN 1 ELSE 0 END)AS daily_new、SUM(CASE WHEN customer_live.active =0 AND DATE(customer_live.time_updated)=@time_date THEN 1 ELSE 0 END )AS daily_canceled、MIN(NOW())AS ts "" FROM Subscription_live.`customer` customer_live "" INNER JOIN subscri ption_live.`city` city_live ON customer_live.city_id =city_live.id "" INNER JOIN Subscription_live.`country` country_live ON city_live.country_id =country_live.id "" INNER JOIN Subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_ .postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name "" INNER JOIN Subscription_dwh.dim_time time_dwh ON time_dwh.time_date ="+ yesterday_str +" "" GROUP BY city_dwh.id、time_dwh.id )#2.2サブスクリプションステータスの更新#同じ日付の古いデータを削除query =("DELETEsubscription_dwh.`fact_subscription_status`。*""FROMsubscription_dwh.`fact_subscription_status`" "INNER JOINsubscription_dwh.`dim_time` ONsubscription_dwh.`fact_subscription_status`.` dim_time_id` =Subscription_dwh.`dim_time`.`id` "" WHERE Subscription_dwh.`dim_time`.`time_date` ="+ yesterday_str)cursor.execute(query)#insert new dataquery =(" INSERT INTOsubscription_dwh.`fact _subscription_status`( `dim_city_id`、` dim_time_id`、 `total_active`、` total_inactive`、 `daily_new`、` daily_canceled`、 `ts`)" "SELECT city_dwh.id AS dim_ctiy_id、time_dwh.id AS dim_time_id、SUM(CASE Subscription_live.active =1 THEN 1 ELSE 0 END)AS total_active、SUM(CASE WHEN Subscription_live.active =0 THEN 1 ELSE 0 END)AS total_inactive、SUM(CASE WHEN Subscription_live.active =1 AND DATE(subscription_live.time_updated)=@ time_date THEN 1 ELSE 0 END)AS daily_new、SUM(CASE WHEN Subscription_live.active =0 AND DATE(subscription_live.time_updated)=@time_date THEN 1 ELSE 0 END)AS daily_canceled、MIN(NOW())AS ts "" FROM Subscription_live 。 country_live ON city_live.country_id =country_live.id "" INNER JOIN Subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_dwh.postal_code AND country_live.country_name =city_dwh.country_name "" INNER JOIN Subscription_dwh.dim_time " BY city_dwh.id、time_dwh.id ")cursor.execute(query)print('ファクトテーブルが更新されました。')#commit&close connectioncursor.close()connection.commit()connection.close()print('データベースから切断されました。') etl_queries.py
モジュールのインポートとデータベースへの接続
もう一度、次のコードを使用してMySQLをインポートする必要があります。
import mysql.connector以下に示すように、日時モジュールもインポートします。 Pythonでの日付関連の操作にはこれが必要です:
日時インポート日からデータベースに接続するプロセスは、前の例と同じです。
dim_timeディメンションの更新
dim_timeテーブルの場合、値(昨日の値)がすでにテーブルにあるかどうかを確認する必要があります。これを行うには、(SQLではなく)Pythonの日付関数を使用する必要があります:
#date-yesterdayyesterday =date.fromordinal(date.today()。toordinal()-1)yesterday_str ='"' + str(yesterday)+'"'コードの最初の行は、日付変数に昨日の日付を返し、2行目はこの値を文字列として格納します。 SQLクエリを作成するときに別の文字列と連結するため、これは文字列として必要になります。
次に、この日付がすでに
dim_timeテーブル。カーソルを宣言したら、SQLクエリを準備します。クエリを実行するには、cursor.executeを使用します コマンド:
#日付がすでにテーブルにあるかどうかをテストcursor =connection.cursor()query =( "SELECT COUNT(*)" "FROM Subscription_dwh.dim_time" "WHERE time_date =" + yesterday_str)cursor.execute(query)'" 'クエリ結果を結果に保存します 変数。結果には0行または1行が含まれるため、最初の行の最初の列をテストできます。 0または1のいずれかが含まれます(ディメンションテーブルで同じ日付を設定できるのは1回だけです)。
日付がまだテーブルにない場合は、SQLクエリの一部となる文字列を準備します:
result =cursor.fetchall()yesterday_subscription_count =int(result [0] [0])if yesterday_subscription_count ==0:yesterday_year ='YEAR( "'+ str(yesterday)+'")' yesterday_month ='MONTH( "'+ str(yesterday)+'")'yesterday_week ='WEEK( "'+ str(yesterday)+'")'yesterday_weekday ='WEEKDAY( "'+ str(yesterday)+'")'最後に、クエリを作成して実行します。これにより、
dim_timeコミットされた後のテーブル。データベース名(subscription_dwh)。
query =( "INSERT INTO Subscription_dwh.`dim_time`(` time_date`、 `time_year`、` time_month`、 `time_week`、` time_weekday`、 `ts`)" "VALUES(" + yesterday_str + "、" + yesterday_year + "、" + yesterday_month + "、" + yesterday_week + "、" + yesterday_weekday + "、Now())")cursor.execute(query)dim_cityディメンションを更新します
dim_city挿入前に何もテストする必要がないため、テーブルはさらに単純です。実際にそのテストをSQLクエリに含めます。
#1.2 update dim_cityquery =( "INSERT INTO Subscription_dwh.`dim_city`(` city_name`、 `postal_code`、` country_name`、 `ts`)" "SELECT city_live.city_name、city_live.postal_code、country_live.country_name、Now ()"" FROM Subscription_live.city city_live "" INNER JOIN Subscription_live.country country_live ON city_live.country_id =country_live.id "" LEFT JOIN Subscription_dwh.dim_city city_dwh ON city_live.city_name =city_dwh.city_name AND city_live.postal_code =city_d country_live.country_name =city_dwh.country_name "" WHERE city_dwh.id IS NULL ")cursor.execute(query)ここでは、SQLクエリの実行を準備します。両方のデータベースの名前(
subscription_liveおよびsubscription_dwh)。ファクトテーブルの更新
最後に行う必要があるのは、ファクトテーブルを更新することです。プロセスはディメンションテーブルの更新とほぼ同じです。クエリを準備して実行します。これらのクエリははるかに複雑ですが、ストアドプロシージャで使用されるクエリと同じです。
ストアドプロシージャと比較して1つの改善点が追加されました。それは、ファクトテーブル内の同じ日付の既存のデータを削除することです。これにより、同じ日にスクリプトを複数回実行できるようになります。最後に、トランザクションをコミットして、すべてのオブジェクトと接続を閉じる必要があります。
スクリプトの実行
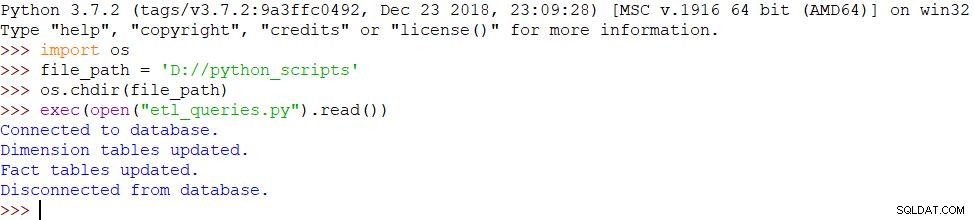
この部分に小さな変更があり、別のスクリプトを呼び出しています:
-import os- file_path ='D:// python_scripts'- os.chdir(file_path)-exec(open( "etl_queries.py")。read())同じメッセージを使用し、スクリプトが正常に完了したため、結果は同じです。
ETLでPythonをどのように使用しますか?
今日は、Pythonスクリプトを使用してETLプロセスを実行する1つの例を見ました。これを行うには他の方法があります。 Pythonライブラリを利用してデータベースを操作し、ETLプロセスを実行する多数のオープンソースソリューション。次の記事では、そのうちの1つで遊んでいきます。それまでの間、PythonとETLの経験をお気軽に共有してください。