人の名前を操作し、それらをファジールックアップする際に、私にとってうまくいったのは、単語の2番目のテーブルを作成することでした。また、テキストを含むテーブルと単語テーブルの間の多対多の関係の交差テーブルである3番目のテーブルを作成します。テキストテーブルに行が追加されたら、テキストを単語に分割し、交差テーブルに適切に入力し、必要に応じて新しい単語を単語テーブルに追加します。この構造が整ったら、一意の単語のテーブルに対してdamlev関数を実行するだけでよいため、ルックアップを少し速く実行できます。単純な結合により、一致する単語を含むテキストが取得されます。 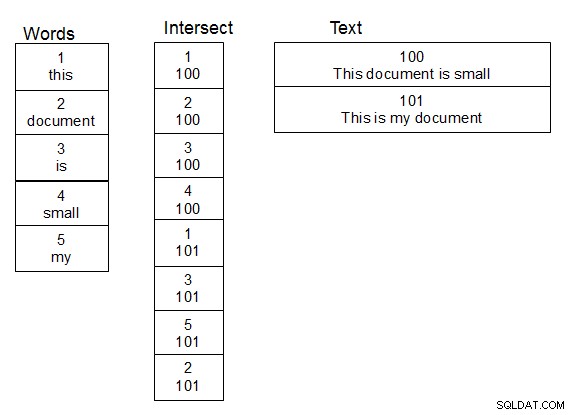
単一の単語の一致に対するクエリは、次のようになります。
SELECT T.* FROM Words AS W
JOIN Intersect AS I ON I.WordId = W.WordId
JOIN Text AS T ON T.TextId = I.TextId
WHERE damlev('document',W.Word) <= 5
そして、2つの単語は次のようになります(頭のてっぺんから離れているため、正確に正しくない可能性があります):
SELECT T.* FROM Text AS T
JOIN (SELECT I.TextId, COUNT(I.WordId) AS MatchCount FROM Word AS W
JOIN Intersect AS I ON I.WordId = W.WordId
WHERE damlev('john',W.Word) <= 2
OR damlev('smith',W.Word) <=2
GROUP BY I.TextId) AS Matches ON Matches.TextId = T.TextId
AND Matches.MatchCount = 2
ここでの利点は、データベーススペースをいくらか犠牲にして、時間のかかるdamlev関数を一意の単語に適用するだけでよいことです。これは、テキストのテーブルのサイズに関係なく、おそらく数万にすぎません。これは重要です。damlevUDFはインデックスを使用しないため、すべての行の値を計算するために適用されるテーブル全体をスキャンします。一意の単語だけをスキャンする方がはるかに高速です。他の利点は、damlevが単語レベルで適用されることです。これはあなたが求めているもののようです。もう1つの利点は、クエリを拡張して複数の単語の検索をサポートし、TextIdで一致する交差行をグループ化し、一致数でランク付けすることで結果をランク付けできることです。