最も密接に関連する都市を計算するにはどうすればよいですか?例えば。都市1(パリ)を見ると、結果は次のようになります:ロンドン(2)、ニューヨーク(3) 提供されたデータセットに基づいて、関連するのは都市間の共通タグだけです。したがって、共通タグを共有する都市が最も近いのは、都市を検索するサブクエリです(共通のタグを共有する最も近い都市を見つける
SELECT * FROM `cities` WHERE id IN (
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
作業中
私の場合、「パリ」のIDが1である場合は、都市IDまたは名前のいずれかを入力して最も近いものを見つけると仮定します
SELECT tag_id FROM `cities_tags` WHERE city_id=1
パリが持っているすべてのタグIDが検索されます
SELECT city_id FROM `cities_tags` WHERE tag_id IN (
SELECT tag_id FROM `cities_tags` WHERE city_id=1) AND city_id !=1 )
パリと同じタグを持つパリを除くすべての都市を取得します
これがあなたの
ジャッカードの類似性/インデックスについて読みながら 用語が実際に何であるかを理解するためにいくつかのものを見つけました。この例を見てみましょう。2つのセットAとBがあります
次に、シナリオに進みます
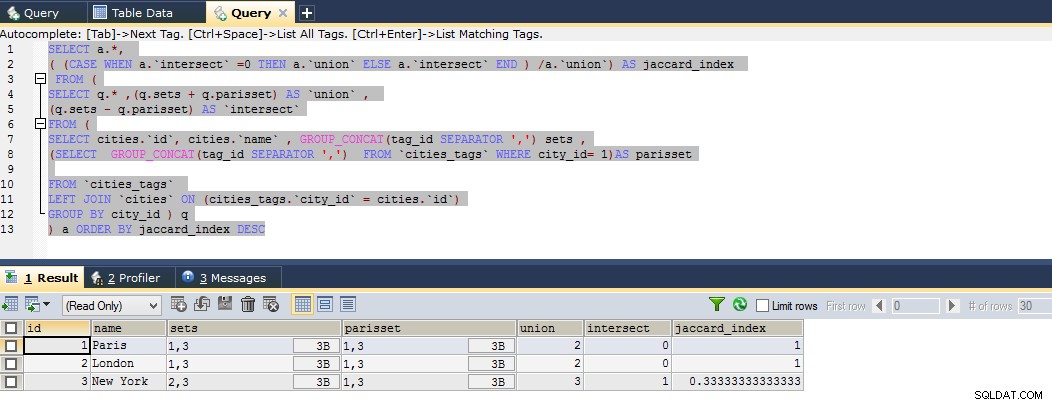
これまでのところ、完璧なジャッカード係数を計算するクエリを次に示します。以下のフィドルの例をご覧ください。
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`)
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
上記のクエリでは、カスタム計算されたエイリアスを取得するために、結果セットを2つの副選択に導きました
上記のクエリにフィルターを追加して、それ自体との類似性を計算しないようにすることができます
SELECT a.*,
( (CASE WHEN a.`intersect` =0 THEN a.`union` ELSE a.`intersect` END ) /a.`union`) AS jaccard_index
FROM (
SELECT q.* ,(q.sets + q.parisset) AS `union` ,
(q.sets - q.parisset) AS `intersect`
FROM (
SELECT cities.`id`, cities.`name` , GROUP_CONCAT(tag_id SEPARATOR ',') sets ,
(SELECT GROUP_CONCAT(tag_id SEPARATOR ',') FROM `cities_tags` WHERE city_id= 1)AS parisset
FROM `cities_tags`
LEFT JOIN `cities` ON (cities_tags.`city_id` = cities.`id`) WHERE cities.`id` !=1
GROUP BY city_id ) q
) a ORDER BY jaccard_index DESC
したがって、結果は、パリがロンドンと密接に関連していて、次にニューヨークと関連していることを示しています